 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheia: Distilling Diverse Vision Foundation Models for Robot Learning
Jul 29, 2024



Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance. Code and models are available at https://github.com/bdaiinstitute/theia.
Comprehensive Dataset of Synthetic and Manipulated Overhead Imagery for Development and Evaluation of Forensic Tools
May 09, 2023We present a first of its kind dataset of overhead imagery for development and evaluation of forensic tools. Our dataset consists of real, fully synthetic and partially manipulated overhead imagery generated from a custom diffusion model trained on two sets of different zoom levels and on two sources of pristine data. We developed our model to support controllable generation of multiple manipulation categories including fully synthetic imagery conditioned on real and generated base maps, and location. We also support partial in-painted imagery with same conditioning options and with several types of manipulated content. The data consist of raw images and ground truth annotations describing the manipulation parameters. We also report benchmark performance on several tasks supported by our dataset including detection of fully and partially manipulated imagery, manipulation localization and classification.
Salient Conditional Diffusion for Defending Against Backdoor Attacks
Jan 31, 2023



We propose a novel algorithm, Salient Conditional Diffusion (Sancdifi), a state-of-the-art defense against backdoor attacks. Sancdifi uses a denoising diffusion probabilistic model (DDPM) to degrade an image with noise and then recover said image using the learned reverse diffusion. Critically, we compute saliency map-based masks to condition our diffusion, allowing for stronger diffusion on the most salient pixels by the DDPM. As a result, Sancdifi is highly effective at diffusing out triggers in data poisoned by backdoor attacks. At the same time, it reliably recovers salient features when applied to clean data. This performance is achieved without requiring access to the model parameters of the Trojan network, meaning Sancdifi operates as a black-box defense.
Explainable Face Recognition
Aug 03, 2020
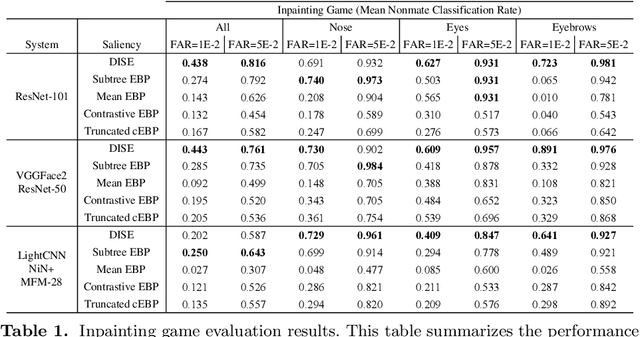

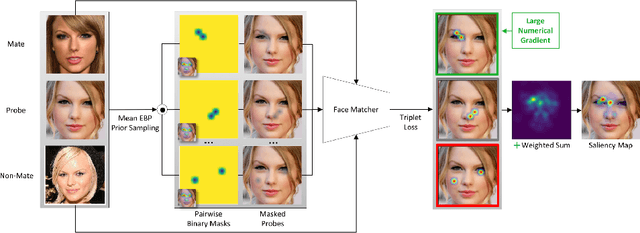
Explainable face recognition is the problem of explaining why a facial matcher matches faces. In this paper, we provide the first comprehensive benchmark and baseline evaluation for explainable face recognition. We define a new evaluation protocol called the ``inpainting game'', which is a curated set of 3648 triplets (probe, mate, nonmate) of 95 subjects, which differ by synthetically inpainting a chosen facial characteristic like the nose, eyebrows or mouth creating an inpainted nonmate. An explainable face matcher is tasked with generating a network attention map which best explains which regions in a probe image match with a mated image, and not with an inpainted nonmate for each triplet. This provides ground truth for quantifying what image regions contribute to face matching. Furthermore, we provide a comprehensive benchmark on this dataset comparing five state of the art methods for network attention in face recognition on three facial matchers. This benchmark includes two new algorithms for network attention called subtree EBP and Density-based Input Sampling for Explanation (DISE) which outperform the state of the art by a wide margin. Finally, we show qualitative visualization of these network attention techniques on novel images, and explore how these explainable face recognition models can improve transparency and trust for facial matchers.