 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Under Pressure: The Case for Informed Adversaries When Evaluating LLM Defenses
May 21, 2025



Large language models (LLMs) are rapidly deployed in real-world applications ranging from chatbots to agentic systems. Alignment is one of the main approaches used to defend against attacks such as prompt injection and jailbreaks. Recent defenses report near-zero Attack Success Rates (ASR) even against Greedy Coordinate Gradient (GCG), a white-box attack that generates adversarial suffixes to induce attacker-desired outputs. However, this search space over discrete tokens is extremely large, making the task of finding successful attacks difficult. GCG has, for instance, been shown to converge to local minima, making it sensitive to initialization choices. In this paper, we assess the future-proof robustness of these defenses using a more informed threat model: attackers who have access to some information about the alignment process. Specifically, we propose an informed white-box attack leveraging the intermediate model checkpoints to initialize GCG, with each checkpoint acting as a stepping stone for the next one. We show this approach to be highly effective across state-of-the-art (SOTA) defenses and models. We further show our informed initialization to outperform other initialization methods and show a gradient-informed checkpoint selection strategy to greatly improve attack performance and efficiency. Importantly, we also show our method to successfully find universal adversarial suffixes -- single suffixes effective across diverse inputs. Our results show that, contrary to previous beliefs, effective adversarial suffixes do exist against SOTA alignment-based defenses, that these can be found by existing attack methods when adversaries exploit alignment knowledge, and that even universal suffixes exist. Taken together, our results highlight the brittleness of current alignment-based methods and the need to consider stronger threat models when testing the safety of LLMs.
DeSIA: Attribute Inference Attacks Against Limited Fixed Aggregate Statistics
Apr 25, 2025Empirical inference attacks are a popular approach for evaluating the privacy risk of data release mechanisms in practice. While an active attack literature exists to evaluate machine learning models or synthetic data release, we currently lack comparable methods for fixed aggregate statistics, in particular when only a limited number of statistics are released. We here propose an inference attack framework against fixed aggregate statistics and an attribute inference attack called DeSIA. We instantiate DeSIA against the U.S. Census PPMF dataset and show it to strongly outperform reconstruction-based attacks. In particular, we show DeSIA to be highly effective at identifying vulnerable users, achieving a true positive rate of 0.14 at a false positive rate of $10^{-3}$. We then show DeSIA to perform well against users whose attributes cannot be verified and when varying the number of aggregate statistics and level of noise addition. We also perform an extensive ablation study of DeSIA and show how DeSIA can be successfully adapted to the membership inference task. Overall, our results show that aggregation alone is not sufficient to protect privacy, even when a relatively small number of aggregates are being released, and emphasize the need for formal privacy mechanisms and testing before aggregate statistics are released.
Watermarking Training Data of Music Generation Models
Dec 12, 2024



Generative Artificial Intelligence (Gen-AI) models are increasingly used to produce content across domains, including text, images, and audio. While these models represent a major technical breakthrough, they gain their generative capabilities from being trained on enormous amounts of human-generated content, which often includes copyrighted material. In this work, we investigate whether audio watermarking techniques can be used to detect an unauthorized usage of content to train a music generation model. We compare outputs generated by a model trained on watermarked data to a model trained on non-watermarked data. We study factors that impact the model's generation behaviour: the watermarking technique, the proportion of watermarked samples in the training set, and the robustness of the watermarking technique against the model's tokenizer. Our results show that audio watermarking techniques, including some that are imperceptible to humans, can lead to noticeable shifts in the model's outputs. We also study the robustness of a state-of-the-art watermarking technique to removal techniques.
QueryCheetah: Fast Automated Discovery of Attribute Inference Attacks Against Query-Based Systems
Sep 03, 2024



Query-based systems (QBSs) are one of the key approaches for sharing data. QBSs allow analysts to request aggregate information from a private protected dataset. Attacks are a crucial part of ensuring QBSs are truly privacy-preserving. The development and testing of attacks is however very labor-intensive and unable to cope with the increasing complexity of systems. Automated approaches have been shown to be promising but are currently extremely computationally intensive, limiting their applicability in practice. We here propose QueryCheetah, a fast and effective method for automated discovery of privacy attacks against QBSs. We instantiate QueryCheetah on attribute inference attacks and show it to discover stronger attacks than previous methods while being 18 times faster than the state-of-the-art automated approach. We then show how QueryCheetah allows system developers to thoroughly evaluate the privacy risk, including for various attacker strengths and target individuals. We finally show how QueryCheetah can be used out-of-the-box to find attacks in larger syntaxes and workarounds around ad-hoc defenses.
Predicting the Popularity of Games on Steam
Oct 06, 2021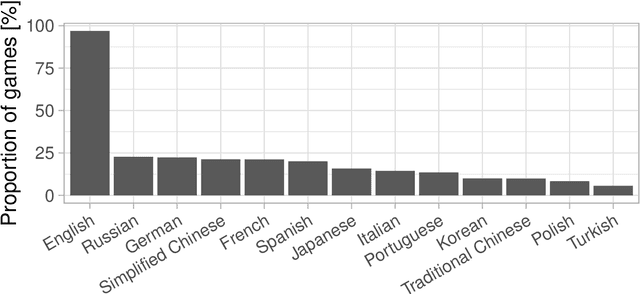

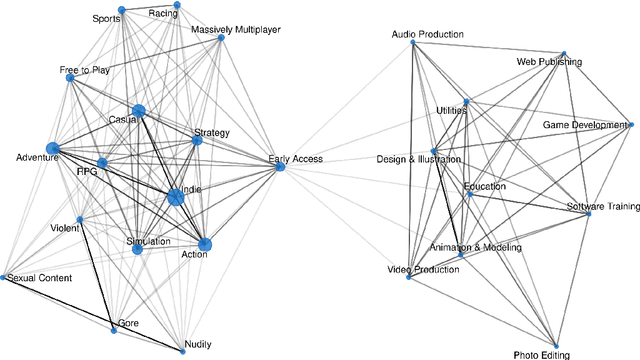
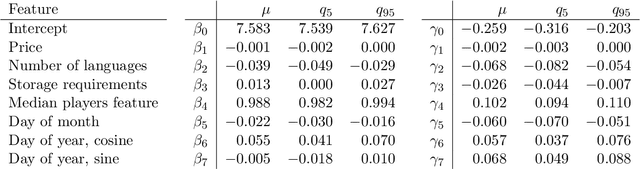
The video game industry has seen rapid growth over the last decade. Thousands of video games are released and played by millions of people every year, creating a large community of players. Steam is a leading gaming platform and social networking site, which allows its users to purchase and store games. A by-product of Steam is a large database of information about games, players, and gaming behavior. In this paper, we take recent video games released on Steam and aim to discover the relation between game popularity and a game's features that can be acquired through Steam. We approach this task by predicting the popularity of Steam games in the early stages after their release and we use a Bayesian approach to understand the influence of a game's price, size, supported languages, release date, and genres on its player count. We implement several models and discover that a genre-based hierarchical approach achieves the best performance. We further analyze the model and interpret its coefficients, which indicate that games released at the beginning of the month and games of certain genres correlate with game popularity.