 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBong-Jin Lee
Disentangled dimensionality reduction for noise-robust speaker diarisation
Oct 07, 2021
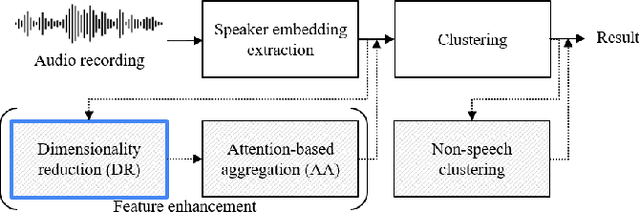
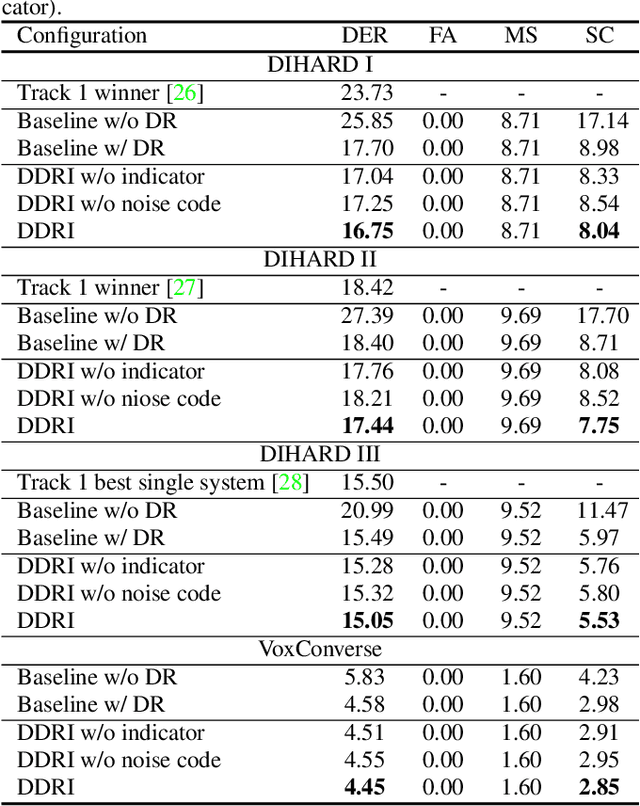
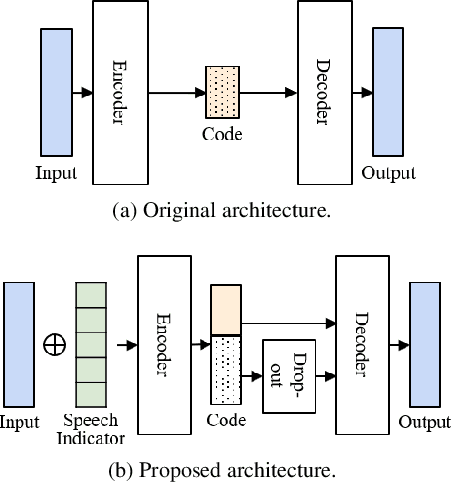

The objective of this work is to train noise-robust speaker embeddings for speaker diarisation. Speaker embeddings play a crucial role in the performance of diarisation systems, but they often capture spurious information such as noise and reverberation, adversely affecting performance. Our previous work have proposed an auto-encoder-based dimensionality reduction module to help remove the spurious information. However, they do not explicitly separate such information and have also been found to be sensitive to hyperparameter values. To this end, we propose two contributions to overcome these issues: (i) a novel dimensionality reduction framework that can disentangle spurious information from the speaker embeddings; (ii) the use of a speech/non-speech indicator to prevent the speaker code from learning from the background noise. Through a range of experiments conducted on four different datasets, our approach consistently demonstrates the state-of-the-art performance among models that do not adopt ensembles.
Multi-scale speaker embedding-based graph attention networks for speaker diarisation
Oct 07, 2021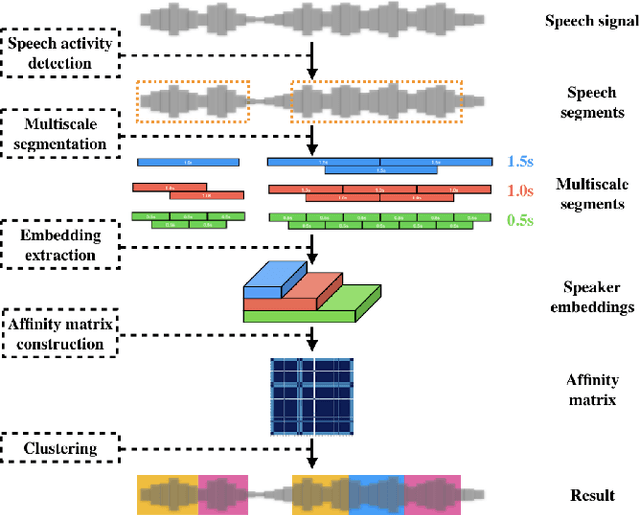
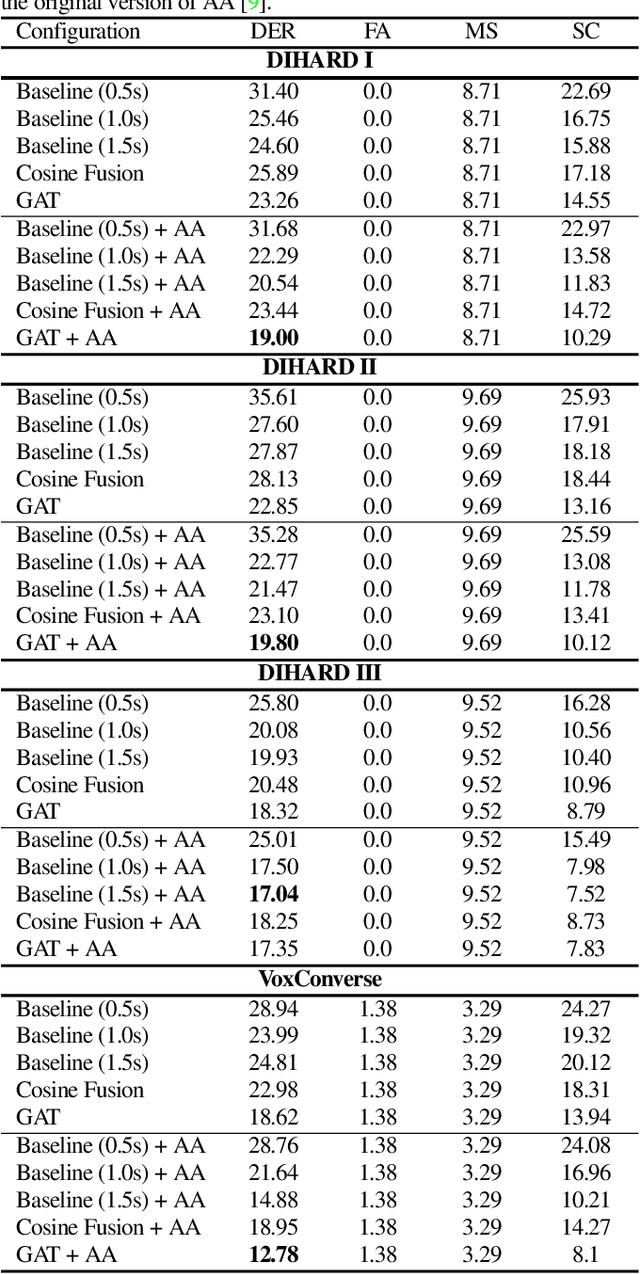
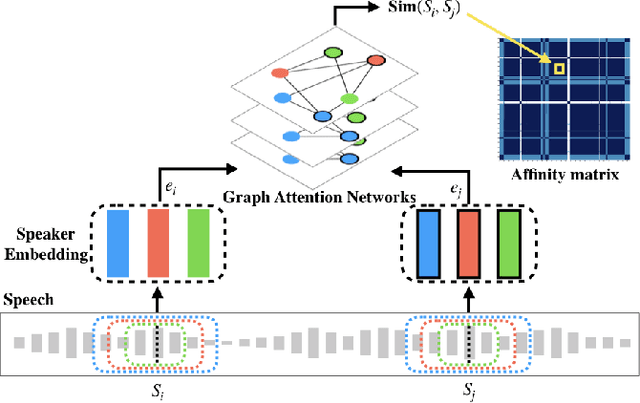
The objective of this work is effective speaker diarisation using multi-scale speaker embeddings. Typically, there is a trade-off between the ability to recognise short speaker segments and the discriminative power of the embedding, according to the segment length used for embedding extraction. To this end, recent works have proposed the use of multi-scale embeddings where segments with varying lengths are used. However, the scores are combined using a weighted summation scheme where the weights are fixed after the training phase, whereas the importance of segment lengths can differ with in a single session. To address this issue, we present three key contributions in this paper: (1) we propose graph attention networks for multi-scale speaker diarisation; (2) we design scale indicators to utilise scale information of each embedding; (3) we adapt the attention-based aggregation to utilise a pre-computed affinity matrix from multi-scale embeddings. We demonstrate the effectiveness of our method in various datasets where the speaker confusion which constitutes the primary metric drops over 10% in average relative compared to the baseline.
AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks
Oct 04, 2021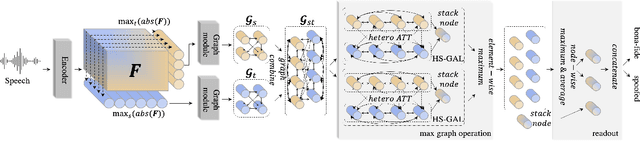

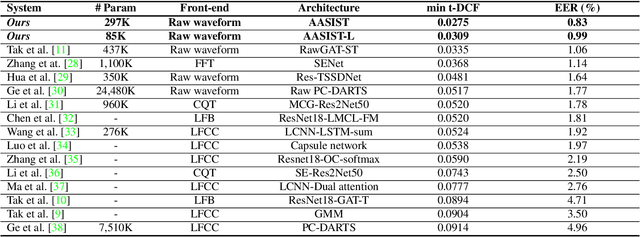
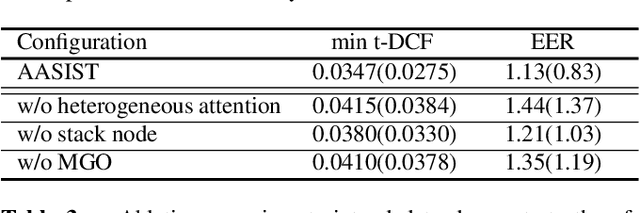
Artefacts that differentiate spoofed from bona-fide utterances can reside in spectral or temporal domains. Their reliable detection usually depends upon computationally demanding ensemble systems where each subsystem is tuned to some specific artefacts. We seek to develop an efficient, single system that can detect a broad range of different spoofing attacks without score-level ensembles. We propose a novel heterogeneous stacking graph attention layer which models artefacts spanning heterogeneous temporal and spectral domains with a heterogeneous attention mechanism and a stack node. With a new max graph operation that involves a competitive mechanism and an extended readout scheme, our approach, named AASIST, outperforms the current state-of-the-art by 20% relative. Even a lightweight variant, AASIST-L, with only 85K parameters, outperforms all competing systems.
Look Who's Talking: Active Speaker Detection in the Wild
Aug 17, 2021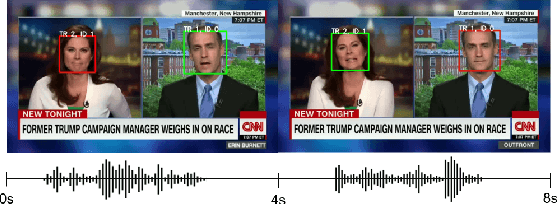
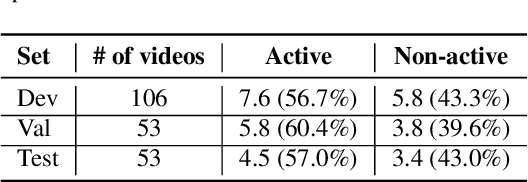
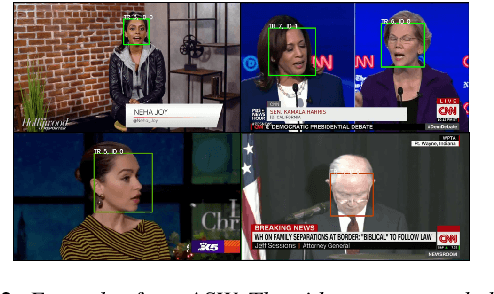
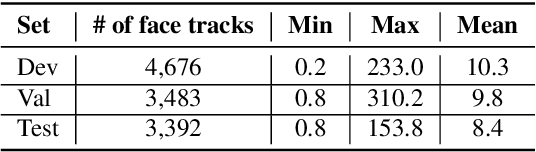
In this work, we present a novel audio-visual dataset for active speaker detection in the wild. A speaker is considered active when his or her face is visible and the voice is audible simultaneously. Although active speaker detection is a crucial pre-processing step for many audio-visual tasks, there is no existing dataset of natural human speech to evaluate the performance of active speaker detection. We therefore curate the Active Speakers in the Wild (ASW) dataset which contains videos and co-occurring speech segments with dense speech activity labels. Videos and timestamps of audible segments are parsed and adopted from VoxConverse, an existing speaker diarisation dataset that consists of videos in the wild. Face tracks are extracted from the videos and active segments are annotated based on the timestamps of VoxConverse in a semi-automatic way. Two reference systems, a self-supervised system and a fully supervised one, are evaluated on the dataset to provide the baseline performances of ASW. Cross-domain evaluation is conducted in order to show the negative effect of dubbed videos in the training data.
Adapting Speaker Embeddings for Speaker Diarisation
Apr 07, 2021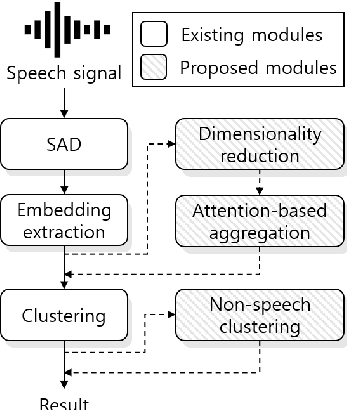
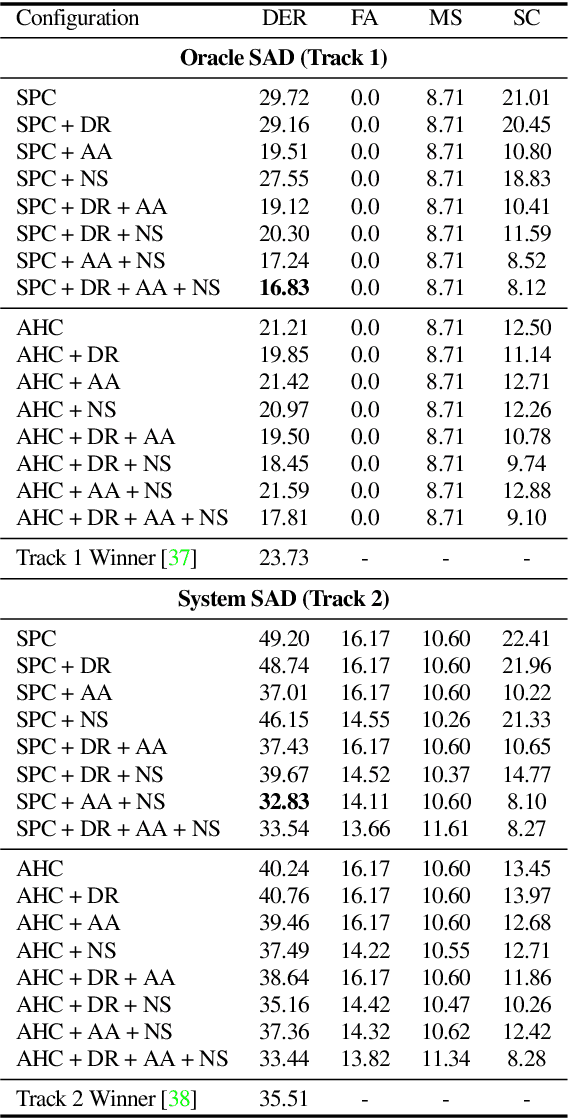
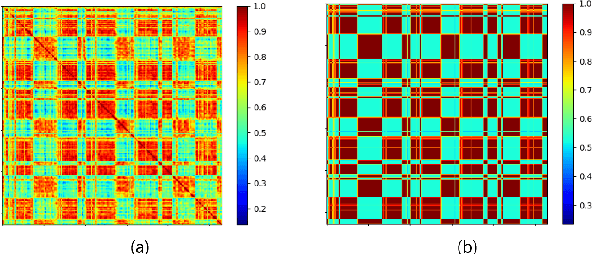
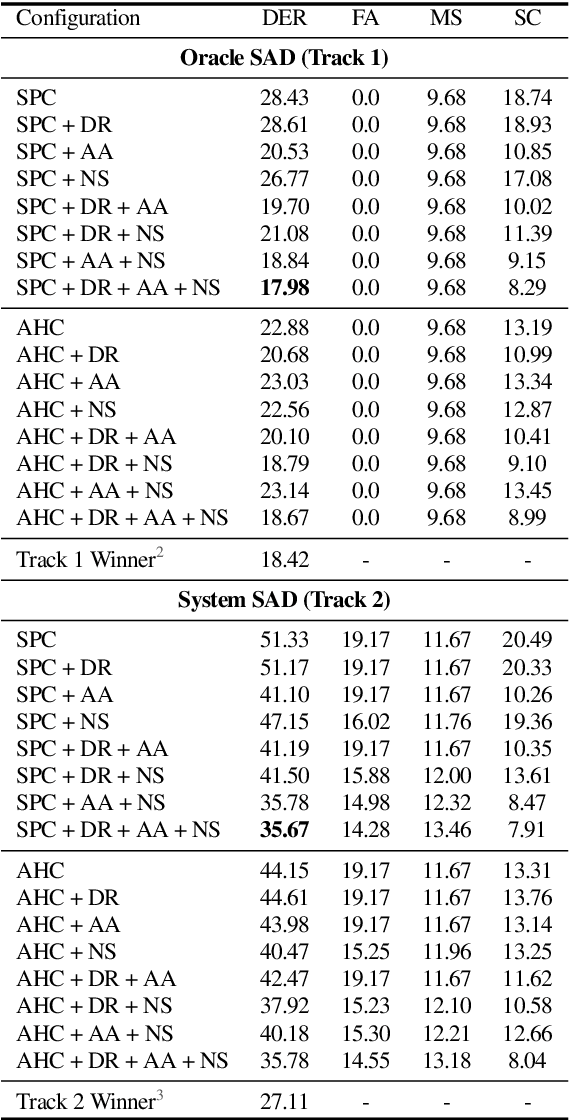
The goal of this paper is to adapt speaker embeddings for solving the problem of speaker diarisation. The quality of speaker embeddings is paramount to the performance of speaker diarisation systems. Despite this, prior works in the field have directly used embeddings designed only to be effective on the speaker verification task. In this paper, we propose three techniques that can be used to better adapt the speaker embeddings for diarisation: dimensionality reduction, attention-based embedding aggregation, and non-speech clustering. A wide range of experiments is performed on various challenging datasets. The results demonstrate that all three techniques contribute positively to the performance of the diarisation system achieving an average relative improvement of 25.07% in terms of diarisation error rate over the baseline.
Three-class Overlapped Speech Detection using a Convolutional Recurrent Neural Network
Apr 07, 2021
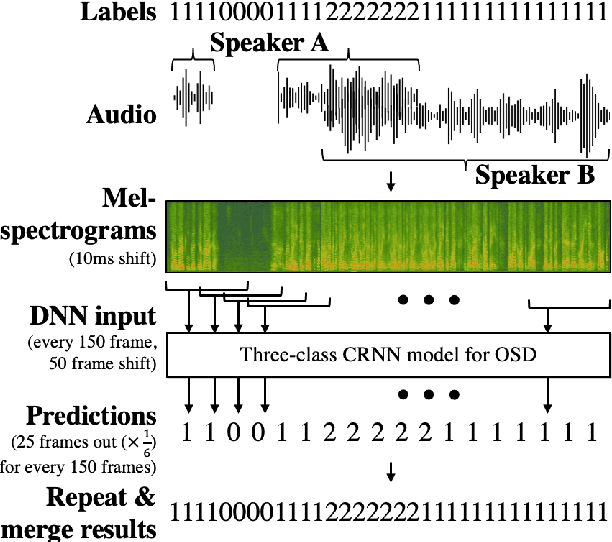
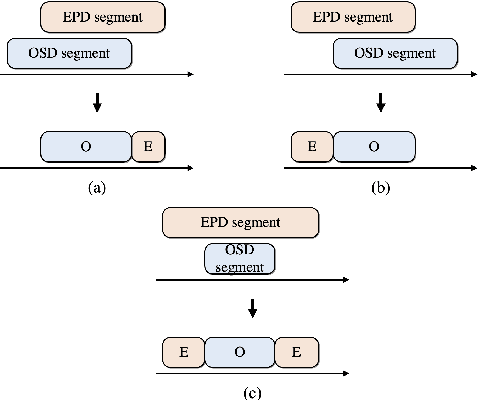
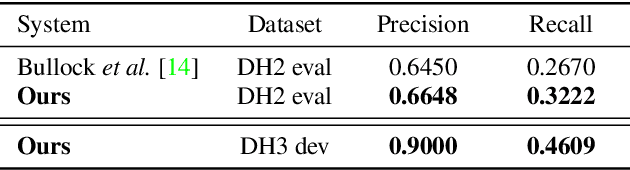
In this work, we propose an overlapped speech detection system trained as a three-class classifier. Unlike conventional systems that perform binary classification as to whether or not a frame contains overlapped speech, the proposed approach classifies into three classes: non-speech, single speaker speech, and overlapped speech. By training a network with the more detailed label definition, the model can learn a better notion on deciding the number of speakers included in a given frame. A convolutional recurrent neural network architecture is explored to benefit from both convolutional layer's capability to model local patterns and recurrent layer's ability to model sequential information. The proposed overlapped speech detection model establishes a state-of-the-art performance with a precision of 0.6648 and a recall of 0.3222 on the DIHARD II evaluation set, showing a 20% increase in recall along with higher precision. In addition, we also introduce a simple approach to utilize the proposed overlapped speech detection model for speaker diarization which ranked third place in the Track 1 of the DIHARD III challenge.
End-to-End Lip Synchronisation
May 18, 2020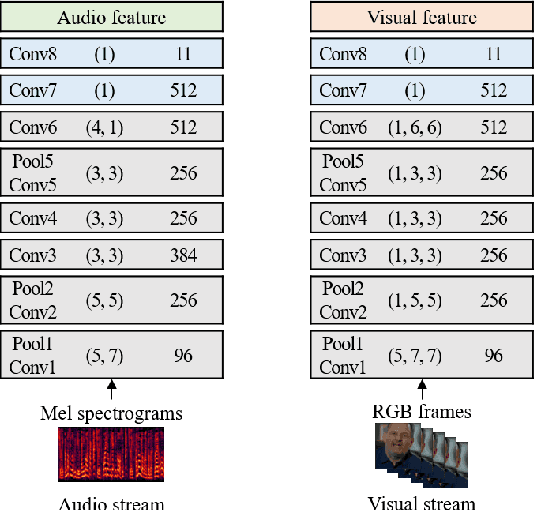
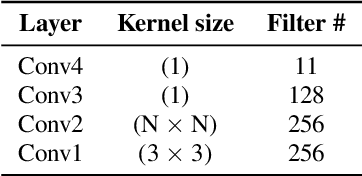
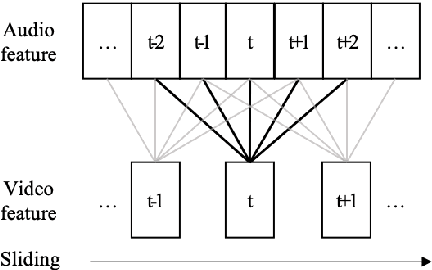
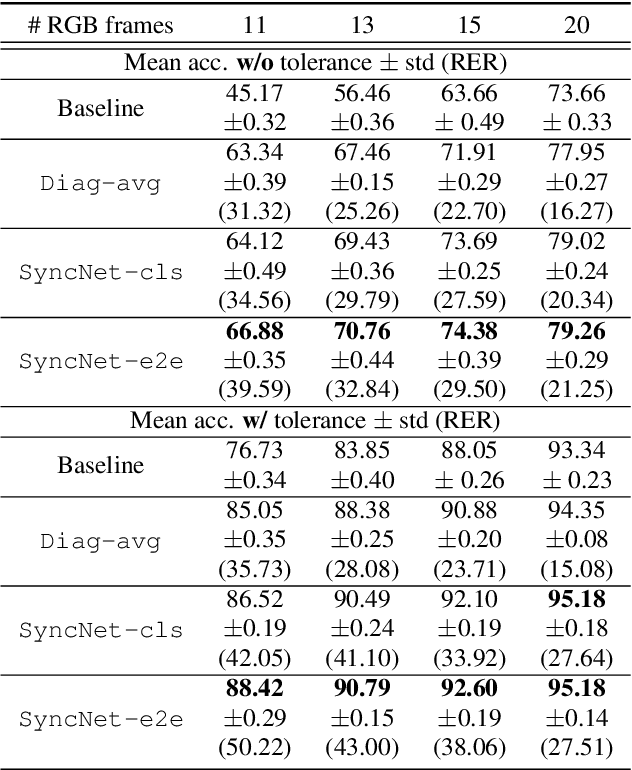
The goal of this work is to synchronise audio and video of a talking face using deep neural network models. Existing works have trained networks on proxy tasks such as cross-modal similarity learning, and then computed similarities between audio and video frames using a sliding window approach. While these methods demonstrate satisfactory performance, the networks are not trained directly on the task. To this end, we propose an end-to-end trained network that can directly predict the offset between an audio stream and the corresponding video stream. The similarity matrix between the two modalities is first computed from the features, then the inference of the offset can be considered to be a pattern recognition problem where the matrix is considered equivalent to an image. The feature extractor and the classifier are trained jointly. We demonstrate that the proposed approach outperforms the previous work by a large margin on LRS2 and LRS3 datasets.
Who said that?: Audio-visual speaker diarisation of real-world meetings
Jun 24, 2019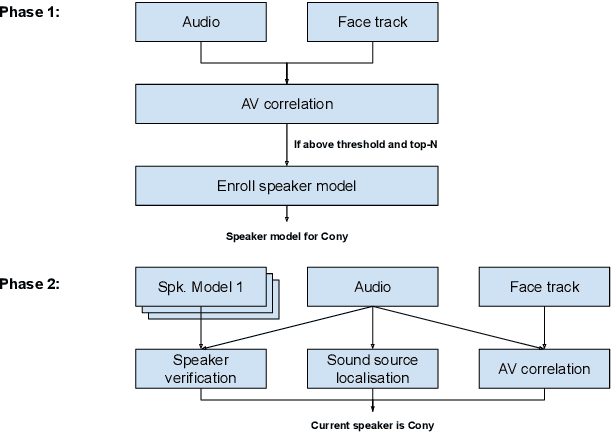


The goal of this work is to determine 'who spoke when' in real-world meetings. The method takes surround-view video and single or multi-channel audio as inputs, and generates robust diarisation outputs. To achieve this, we propose a novel iterative approach that first enrolls speaker models using audio-visual correspondence, then uses the enrolled models together with the visual information to determine the active speaker. We show strong quantitative and qualitative performance on a dataset of real-world meetings. The method is also evaluated on the public AMI meeting corpus, on which we demonstrate results that exceed all comparable methods. We also show that beamforming can be used together with the video to further improve the performance when multi-channel audio is available.