 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Analytics of Air Alerts in the Russian-Ukrainian War
Nov 21, 2024The paper considers exploratory data analysis and approaches in predictive analytics for air alerts during the Russian-Ukrainian war which broke out on Feb 24, 2022. The results illustrate that alerts in regions correlate with one another and have geospatial patterns which make it feasible to build a predictive model which predicts alerts that are expected to take place in a certain region within a specified time period. The obtained results show that the alert status in a particular region is highly dependable on the features of its adjacent regions. Seasonality features like hours, days of a week and months are also crucial in predicting the target variable. Some regions highly rely on the time feature which equals to a number of days from the initial date of the dataset. From this, we can deduce that the air alert pattern changes throughout the time.
Can Twitter Predict Royal Baby's Name ?
Oct 13, 2013
In this paper, we analyze the existence of possible correlation between public opinion of twitter users and the decision-making of persons who are influential in the society. We carry out this analysis on the example of the discussion of probable name of the British crown baby, born in July, 2013. In our study, we use the methods of quantitative processing of natural language, the theory of frequent sets, the algorithms of visual displaying of users' communities. We also analyzed the time dynamics of keyword frequencies. The analysis showed that the main predictable name was dominating in the spectrum of names before the official announcement. Using the theories of frequent sets, we showed that the full name consisting of three component names was the part of top 5 by the value of support. It was revealed that the structure of dynamically formed users' communities participating in the discussion is determined by only a few leaders who influence significantly the viewpoints of other users.
Forecasting of Events by Tweet Data Mining
Oct 13, 2013
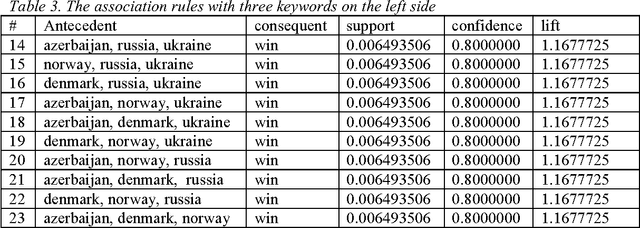

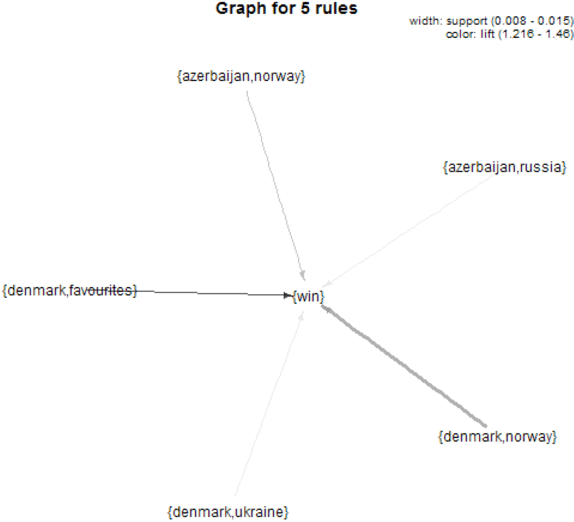
This paper describes the analysis of quantitative characteristics of frequent sets and association rules in the posts of Twitter microblogs related to different event discussions. For the analysis, we used a theory of frequent sets, association rules and a theory of formal concept analysis. We revealed the frequent sets and association rules which characterize the semantic relations between the concepts of analyzed subjects. The support of some frequent sets reaches its global maximum before the expected event but with some time delay. Such frequent sets may be considered as predictive markers that characterize the significance of expected events for blogosphere users. We showed that the time dynamics of confidence in some revealed association rules can also have predictive characteristics. Exceeding a certain threshold may be a signal for corresponding reaction in the society within the time interval between the maximum and the probable coming of an event. In this paper, we considered two types of events: the Olympic tennis tournament final in London, 2012 and the prediction of Eurovision 2013 winner.
Tweets Miner for Stock Market Analysis
May 30, 2013In this paper, we present a software package for the data mining of Twitter microblogs for the purpose of using them for the stock market analysis. The package is written in R langauge using apropriate R packages. The model of tweets has been considered. We have also compared stock market charts with frequent sets of keywords in Twitter microblogs messages.
Data Mining of the Concept "End of the World" in Twitter Microblogs
Feb 08, 2013

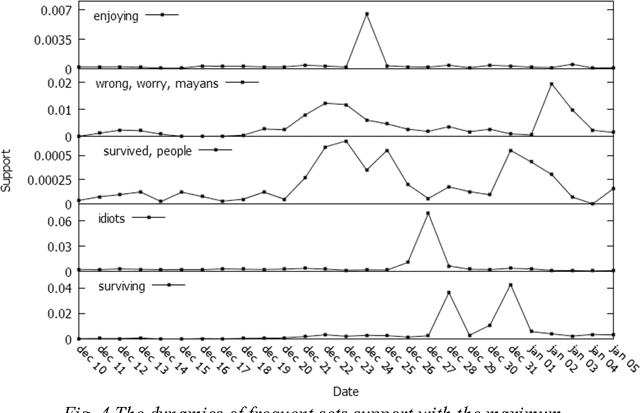
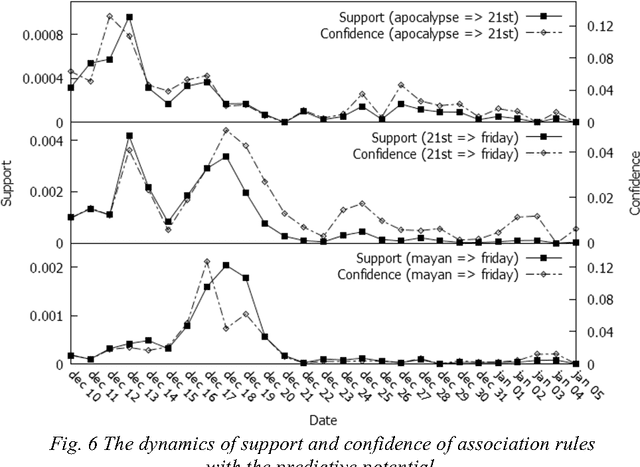
This paper describes the analysis of quantitative characteristics of frequent sets and association rules in the posts of Twitter microblogs, related to the discussion of "end of the world", which was allegedly predicted on December 21, 2012 due to the Mayan calendar. Discovered frequent sets and association rules characterize semantic relations between the concepts of analyzed subjects.The support for some fequent sets reaches the global maximum before the expected event with some time delay. Such frequent sets may be considered as predictive markers that characterize the significance of expected events for blogosphere users. It was shown that time dynamics of confidence of some revealed association rules can also have predictive characteristics. Exceeding a certain threshold, it may be a signal for the corresponding reaction in the society during the time interval between the maximum and probable coming of an event.
The Clustering of Author's Texts of English Fiction in the Vector Space of Semantic Fields
Dec 06, 2012


The clustering of text documents in the vector space of semantic fields and in the semantic space with orthogonal basis has been analysed. It is shown that using the vector space model with the basis of semantic fields is effective in the cluster analysis algorithms of author's texts in English fiction. The analysis of the author's texts distribution in cluster structure showed the presence of the areas of semantic space that represent the author's ideolects of individual authors. SVD factorization of the semantic fields matrix makes it possible to reduce significantly the dimension of the semantic space in the cluster analysis of author's texts.
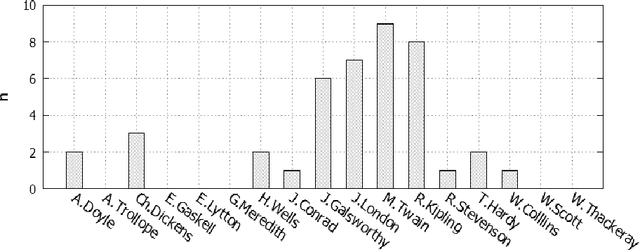
Genetic Optimization of Keywords Subset in the Classification Analysis of Texts Authorship
Nov 14, 2012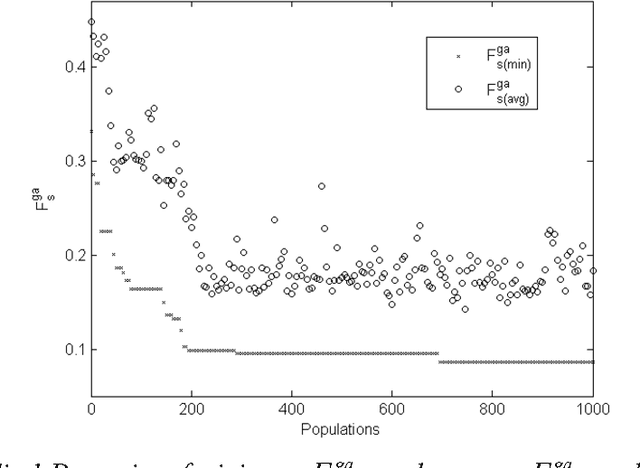
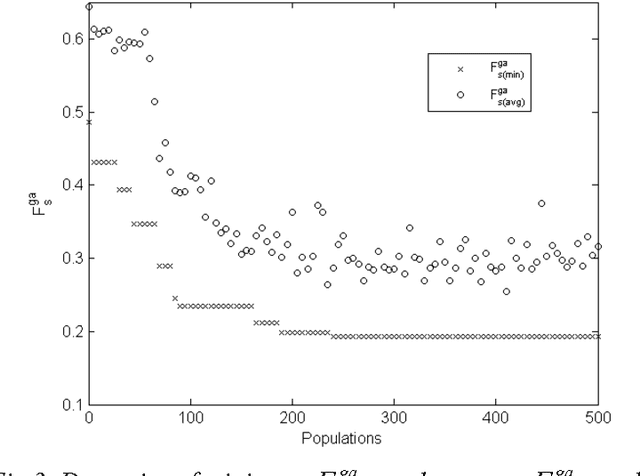
The genetic selection of keywords set, the text frequencies of which are considered as attributes in text classification analysis, has been analyzed. The genetic optimization was performed on a set of words, which is the fraction of the frequency dictionary with given frequency limits. The frequency dictionary was formed on the basis of analyzed text array of texts of English fiction. As the fitness function which is minimized by the genetic algorithm, the error of nearest k neighbors classifier was used. The obtained results show high precision and recall of texts classification by authorship categories on the basis of attributes of keywords set which were selected by the genetic algorithm from the frequency dictionary.
The Model of Semantic Concepts Lattice For Data Mining Of Microblogs
Oct 30, 2012The model of semantic concept lattice for data mining of microblogs has been proposed in this work. It is shown that the use of this model is effective for the semantic relations analysis and for the detection of associative rules of key words.
Classification Analysis Of Authorship Fiction Texts in The Space Of Semantic Fields
Oct 22, 2012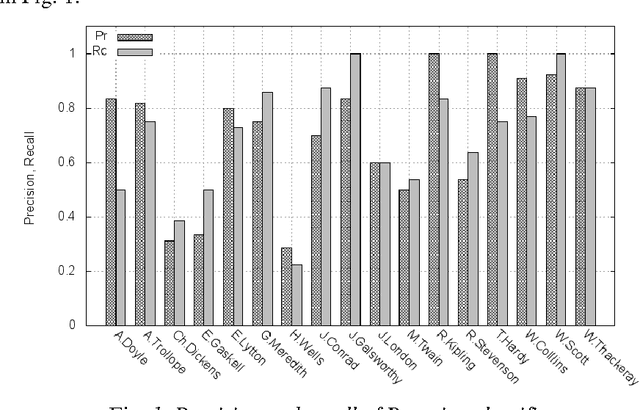
The use of naive Bayesian classifier (NB) and the classifier by the k nearest neighbors (kNN) in classification semantic analysis of authors' texts of English fiction has been analysed. The authors' works are considered in the vector space the basis of which is formed by the frequency characteristics of semantic fields of nouns and verbs. Highly precise classification of authors' texts in the vector space of semantic fields indicates about the presence of particular spheres of author's idiolect in this space which characterizes the individual author's style.