 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-Powered Elicitation Interview Script Generator for Requirements Engineering Training
Jun 17, 2024Elicitation interviews are the most common requirements elicitation technique, and proficiency in conducting these interviews is crucial for requirements elicitation. Traditional training methods, typically limited to textbook learning, may not sufficiently address the practical complexities of interviewing techniques. Practical training with various interview scenarios is important for understanding how to apply theoretical knowledge in real-world contexts. However, there is a shortage of educational interview material, as creating interview scripts requires both technical expertise and creativity. To address this issue, we develop a specialized GPT agent for auto-generating interview scripts. The GPT agent is equipped with a dedicated knowledge base tailored to the guidelines and best practices of requirements elicitation interview procedures. We employ a prompt chaining approach to mitigate the output length constraint of GPT to be able to generate thorough and detailed interview scripts. This involves dividing the interview into sections and crafting distinct prompts for each, allowing for the generation of complete content for each section. The generated scripts are assessed through standard natural language generation evaluation metrics and an expert judgment study, confirming their applicability in requirements engineering training.
Emerging Technologies in Requirements Elicitation Interview Training: Robotic and Virtual Tutors
Apr 28, 2023[Context] Requirements elicitation interviews are the most widely used elicitation technique. The interviewer's preparedness and communication skills play an important role in the quality of interaction, therefore, the interview's success. Students can develop their skills through practice interviews. [Problem] Arranging practice interviews for many students is not scalable, as the involvement of a stakeholder in each interview requires a lot of time and effort. [Principal Idea] To address this problem, we propose REIT, an extensible architecture for Requirements Elicitation Interview Trainer system based on emerging technologies for education. It has two separate phases. The first is the interview phase, where the student acts as an interviewer and the system as an interviewee. The second is the feedback phase, where the system evaluates the student's performance and provides contextual and behavioral feedback to enhance their interviewing skills. [Results/Contribution] We demonstrate the applicability of REIT by implementing two instances: RoREIT with an embodied physical robotic agent and VoREIT with a virtual voice-only agent. We empirically evaluated these two instances with a target user group consisting of graduate students. The results reveal that the students appreciated both systems. The participants demonstrated higher learning gain when trained with RoREIT, but they found VoREIT more engaging and easier to use. These findings indicate that each system has its distinct benefits and drawbacks, suggesting that our generic architecture REIT can be configured for various educational settings based on preferences and available resources.
RoboREIT: an Interactive Robotic Tutor with Instructive Feedback Component for Requirements Elicitation Interview Training
Apr 15, 2023[Context] Interviewing stakeholders is the most popular requirements elicitation technique among multiple methods. The success of an interview depends on the collaboration of the interviewee which can be fostered through the interviewer's preparedness and communication skills. Mastering these skills requires experience and practicing interviews. [Problem] Practical training is resource-heavy as it calls for the time and effort of a stakeholder for each student which may not be feasible for a large number of students. [Method] To address this scalability problem, this paper proposes RoboREIT, an interactive Robotic tutor for Requirements Elicitation Interview Training. The humanoid robotic component of RoboREIT responds to the questions of the interviewer, which the interviewer chooses from a set of predefined alternatives for a particular scenario. After the interview session, RoboREIT provides contextual feedback to the interviewer on their performance and allows the student to inspect their mistakes. RoboREIT is extensible with various scenarios. [Results] We performed an exploratory user study to evaluate RoboREIT and demonstrate its applicability in requirements elicitation interview training. The quantitative and qualitative analyses of the users' responses reveal the appreciation of RoboREIT and provide further suggestions about how to improve it. [Contribution] Our study is the first in the literature that utilizes a social robot in requirements elicitation interview education. RoboREIT's innovative design incorporates replaying faulty interview stages and allows the student to learn from mistakes by a second time practicing. All participants praised the feedback component, which is not present in the state-of-the-art, for being helpful in identifying the mistakes. A favorable response rate of 81% for the system's usefulness indicates the positive perception of the participants.
End-to-End Deep Imitation Learning: Robot Soccer Case Study
Jun 28, 2018


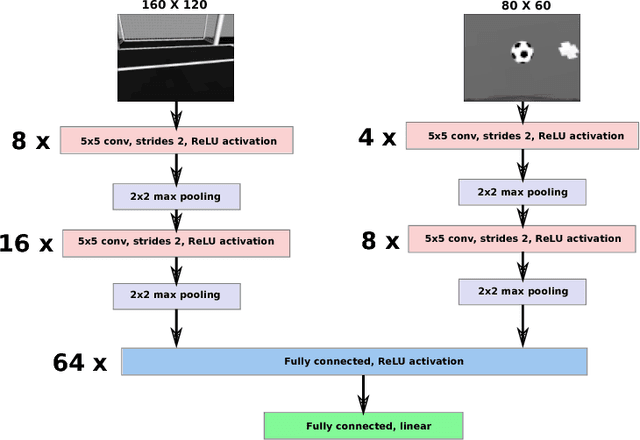
In imitation learning, behavior learning is generally done using the features extracted from the demonstration data. Recent deep learning algorithms enable the development of machine learning methods that can get high dimensional data as an input. In this work, we use imitation learning to teach the robot to dribble the ball to the goal. We use B-Human robot software to collect demonstration data and a deep convolutional network to represent the policies. We use top and bottom camera images of the robot as input and speed commands as outputs. The CNN policy learns the mapping between the series of images and speed commands. In 3D realistic robotics simulator experiments, we show that the robot is able to learn to search the ball and dribble the ball, but it struggles to align to the goal. The best-proposed policy model learns to score 4 goals out of 20 test episodes.