 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive fine-tuning of Transformers for Translation of low-resourced languages @LoResMT 2021
Aug 31, 2021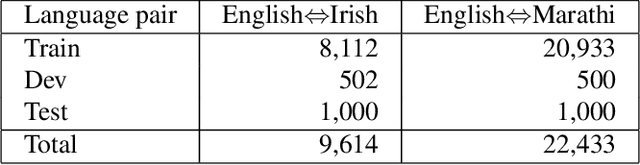
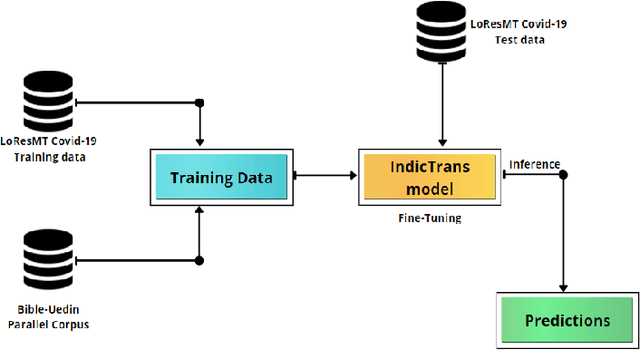
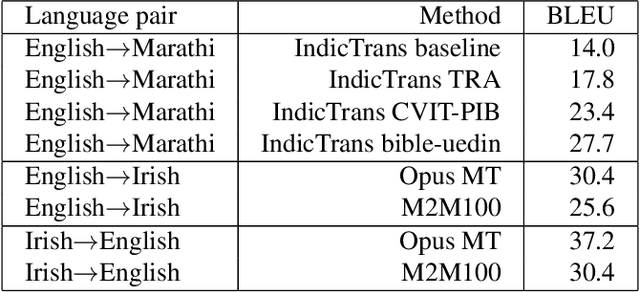
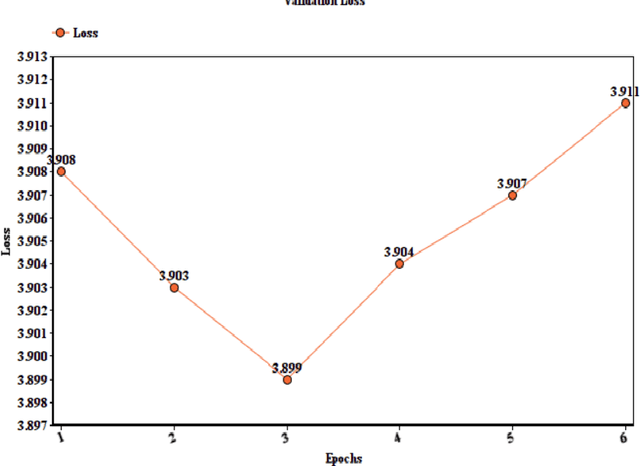
This paper reports the Machine Translation (MT) systems submitted by the IIITT team for the English->Marathi and English->Irish language pairs LoResMT 2021 shared task. The task focuses on getting exceptional translations for rather low-resourced languages like Irish and Marathi. We fine-tune IndicTrans, a pretrained multilingual NMT model for English->Marathi, using external parallel corpus as input for additional training. We have used a pretrained Helsinki-NLP Opus MT English->Irish model for the latter language pair. Our approaches yield relatively promising results on the BLEU metrics. Under the team name IIITT, our systems ranked 1, 1, and 2 in English->Marathi, Irish->English, and English->Irish, respectively.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021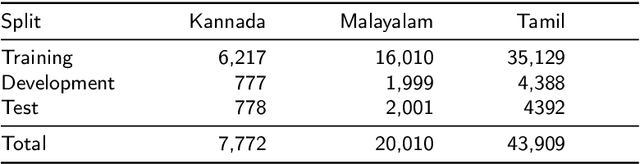
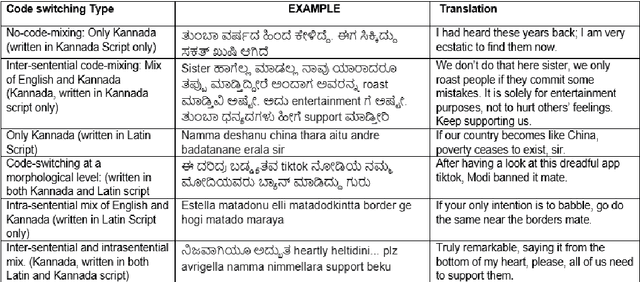

Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.
Hope Speech detection in under-resourced Kannada language
Aug 10, 2021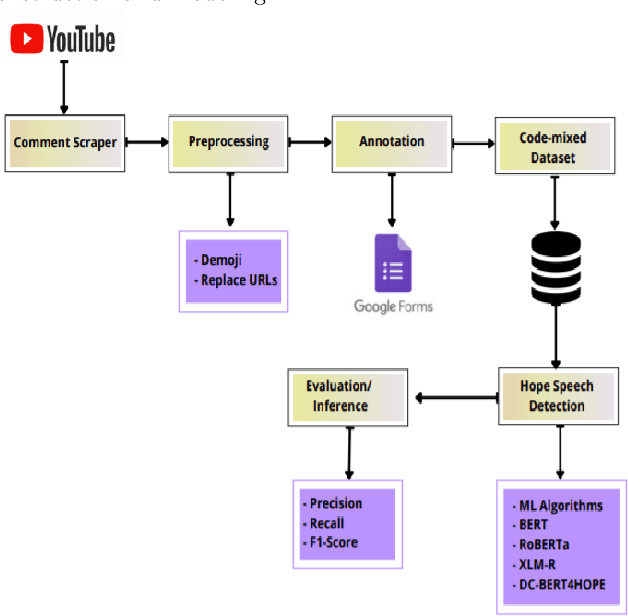
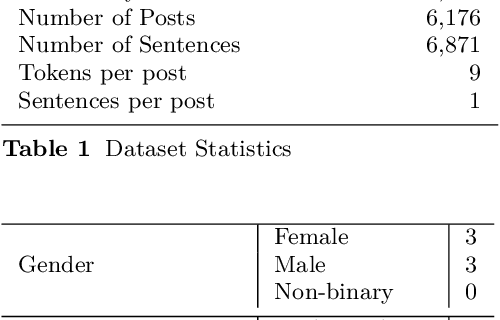
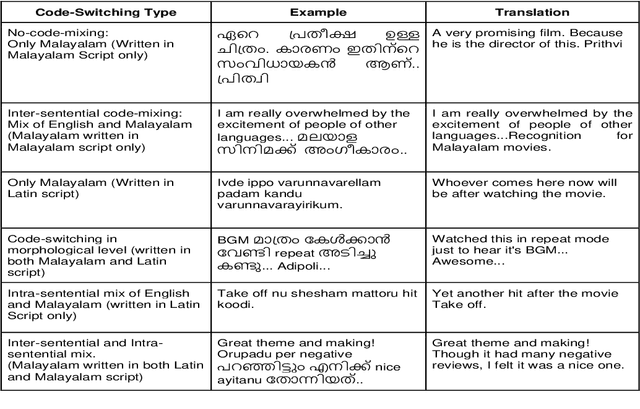
Numerous methods have been developed to monitor the spread of negativity in modern years by eliminating vulgar, offensive, and fierce comments from social media platforms. However, there are relatively lesser amounts of study that converges on embracing positivity, reinforcing supportive and reassuring content in online forums. Consequently, we propose creating an English-Kannada Hope speech dataset, KanHope and comparing several experiments to benchmark the dataset. The dataset consists of 6,176 user-generated comments in code mixed Kannada scraped from YouTube and manually annotated as bearing hope speech or Not-hope speech. In addition, we introduce DC-BERT4HOPE, a dual-channel model that uses the English translation of KanHope for additional training to promote hope speech detection. The approach achieves a weighted F1-score of 0.756, bettering other models. Henceforth, KanHope aims to instigate research in Kannada while broadly promoting researchers to take a pragmatic approach towards online content that encourages, positive, and supportive.
Do Images really do the Talking? Analysing the significance of Images in Tamil Troll meme classification
Aug 09, 2021

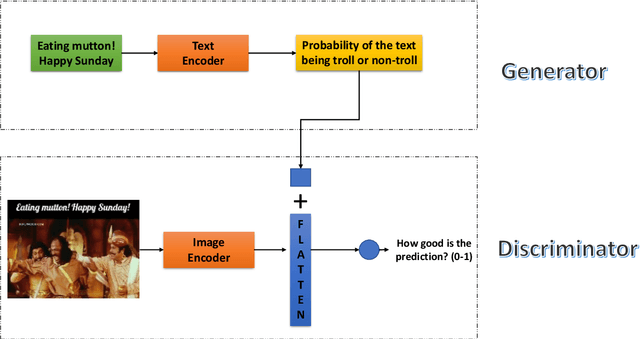
A meme is an part of media created to share an opinion or emotion across the internet. Due to its popularity, memes have become the new forms of communication on social media. However, due to its nature, they are being used in harmful ways such as trolling and cyberbullying progressively. Various data modelling methods create different possibilities in feature extraction and turning them into beneficial information. The variety of modalities included in data plays a significant part in predicting the results. We try to explore the significance of visual features of images in classifying memes. Memes are a blend of both image and text, where the text is embedded into the image. We try to incorporate the memes as troll and non-trolling memes based on the images and the text on them. However, the images are to be analysed and combined with the text to increase performance. Our work illustrates different textual analysis methods and contrasting multimodal methods ranging from simple merging to cross attention to utilising both worlds' - best visual and textual features. The fine-tuned cross-lingual language model, XLM, performed the best in textual analysis, and the multimodal transformer performs the best in multimodal analysis.
DravidianCodeMix: Sentiment Analysis and Offensive Language Identification Dataset for Dravidian Languages in Code-Mixed Text
Jun 17, 2021
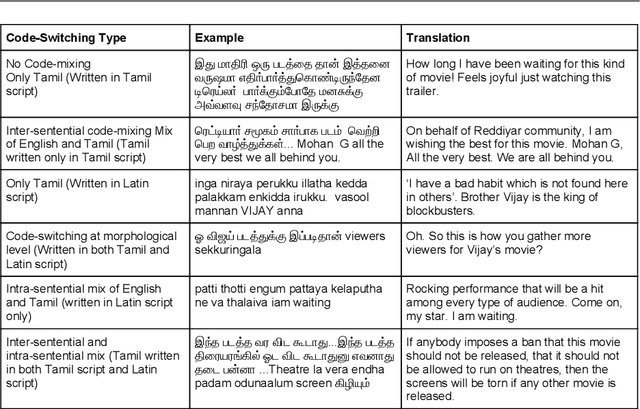
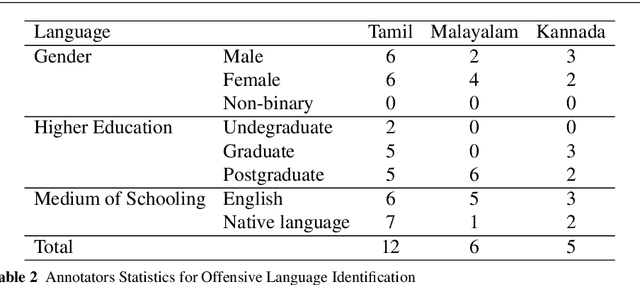
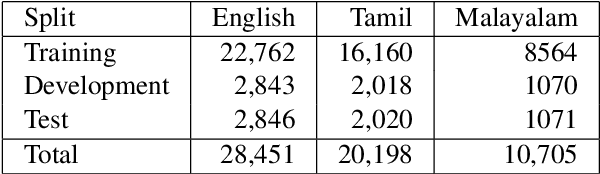
This paper describes the development of a multilingual, manually annotated dataset for three under-resourced Dravidian languages generated from social media comments. The dataset was annotated for sentiment analysis and offensive language identification for a total of more than 60,000 YouTube comments. The dataset consists of around 44,000 comments in Tamil-English, around 7,000 comments in Kannada-English, and around 20,000 comments in Malayalam-English. The data was manually annotated by volunteer annotators and has a high inter-annotator agreement in Krippendorff's alpha. The dataset contains all types of code-mixing phenomena since it comprises user-generated content from a multilingual country. We also present baseline experiments to establish benchmarks on the dataset using machine learning methods. The dataset is available on Github (https://github.com/bharathichezhiyan/DravidianCodeMix-Dataset) and Zenodo (https://zenodo.org/record/4750858\#.YJtw0SYo\_0M).
DravidianMultiModality: A Dataset for Multi-modal Sentiment Analysis in Tamil and Malayalam
Jun 09, 2021


Human communication is inherently multimodal and asynchronous. Analyzing human emotions and sentiment is an emerging field of artificial intelligence. We are witnessing an increasing amount of multimodal content in local languages on social media about products and other topics. However, there are not many multimodal resources available for under-resourced Dravidian languages. Our study aims to create a multimodal sentiment analysis dataset for the under-resourced Tamil and Malayalam languages. First, we downloaded product or movies review videos from YouTube for Tamil and Malayalam. Next, we created captions for the videos with the help of annotators. Then we labelled the videos for sentiment, and verified the inter-annotator agreement using Fleiss's Kappa. This is the first multimodal sentiment analysis dataset for Tamil and Malayalam by volunteer annotators.
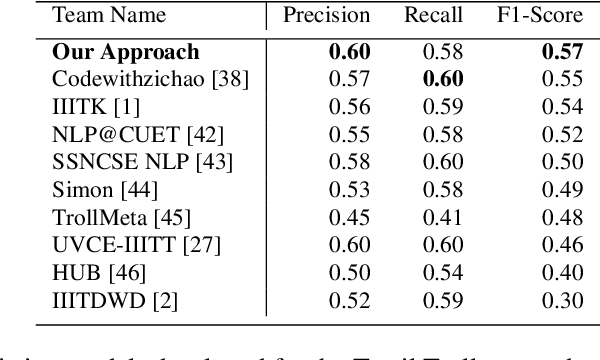
UVCE-IIITT@DravidianLangTech-EACL2021: Tamil Troll Meme Classification: You need to Pay more Attention
Apr 19, 2021
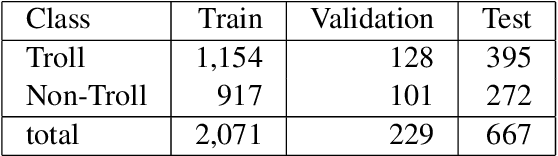
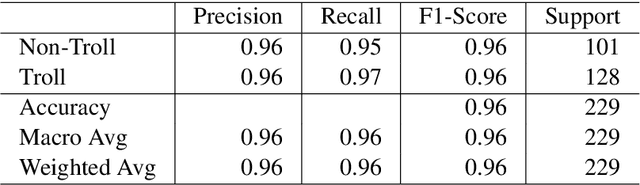
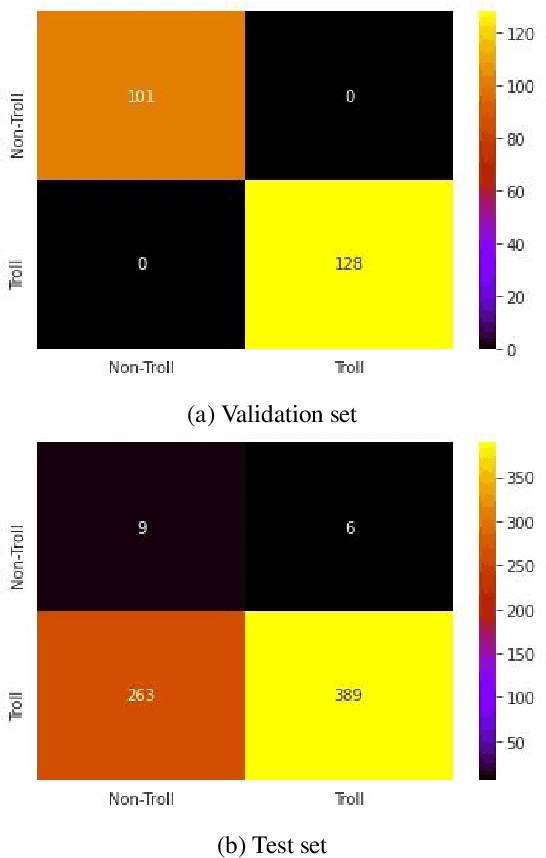
Tamil is a Dravidian language that is commonly used and spoken in the southern part of Asia. In the era of social media, memes have been a fun moment in the day-to-day life of people. Here, we try to analyze the true meaning of Tamil memes by categorizing them as troll and non-troll. We propose an ingenious model comprising of a transformer-transformer architecture that tries to attain state-of-the-art by using attention as its main component. The dataset consists of troll and non-troll images with their captions as text. The task is a binary classification task. The objective of the model is to pay more attention to the extracted features and to ignore the noise in both images and text.
IIITT@LT-EDI-EACL2021-Hope Speech Detection: There is always Hope in Transformers
Apr 19, 2021
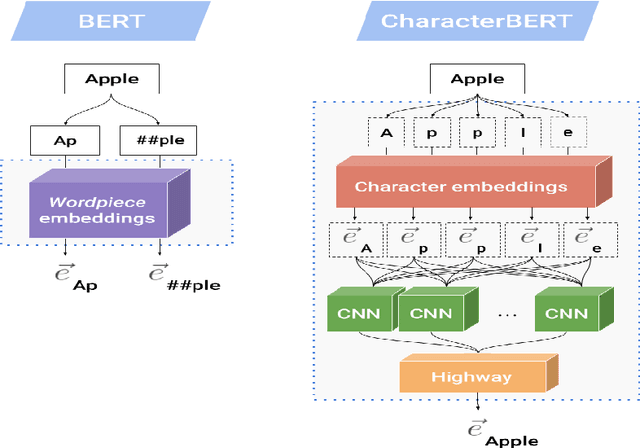
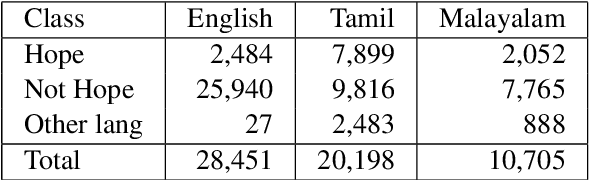
In a world filled with serious challenges like climate change, religious and political conflicts, global pandemics, terrorism, and racial discrimination, an internet full of hate speech, abusive and offensive content is the last thing we desire for. In this paper, we work to identify and promote positive and supportive content on these platforms. We work with several transformer-based models to classify social media comments as hope speech or not-hope speech in English, Malayalam and Tamil languages. This paper portrays our work for the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion at LT-EDI 2021- EACL 2021.
DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language
Dec 28, 2020
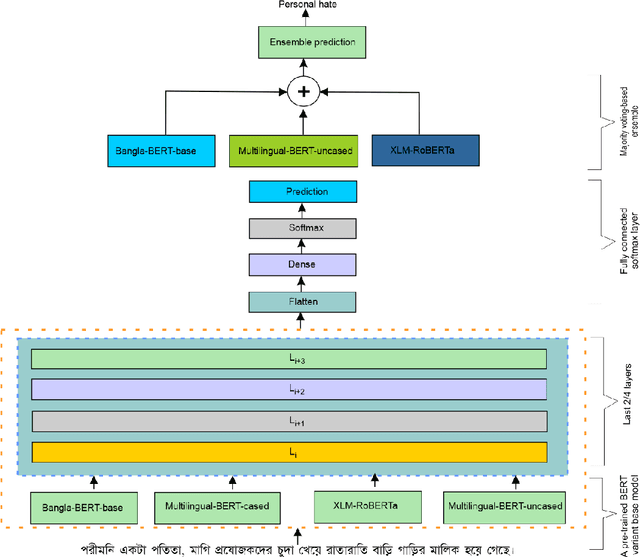
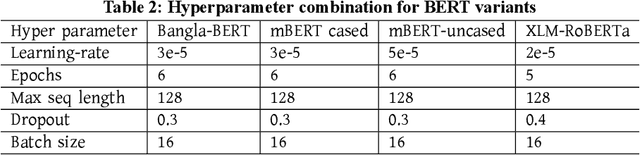
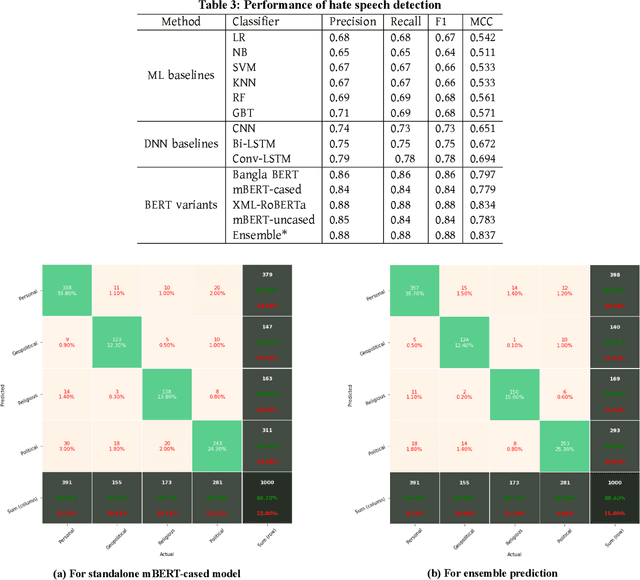
Exponential growths of social media and micro-blogging sites not only provide platforms for empowering freedom of expressions and individual voices, but also enables people to express anti-social behavior like online harassment, cyberbullying, and hate speech. Numerous works have been proposed to utilize these data for social and anti-social behavior analysis, by predicting the contexts mostly for highly-resourced languages like English. However, some languages such as Bengali are under-resourced that lack of computational resources for natural language processing(NLP). In this paper, we propose an explainable approach for hate speech detection from under-resourced Bengali language, which we called DeepHateExplainer. In our approach, Bengali texts are first comprehensively preprocessed, before classifying them into political, personal, geopolitical, and religious hates, by employing neural ensemble of different transformer-based neural architectures(i.e., monolingual Bangla BERT-base, multilingual BERT-cased and uncased, and XLM-RoBERTa), followed by identifying important terms with sensitivity analysis and layer-wise relevance propagation(LRP) to provide human-interpretable explanations. Evaluations against several machine learning~(linear and tree-based models) and deep neural networks (i.e., CNN, Bi-LSTM, and Conv-LSTM with word embeddings) baselines yield F1 scores of 84%, 90%, 88%, and 88%, for political, personal, geopolitical, and religious hates, respectively, during 3-fold cross-validation tests.
Aspects of Terminological and Named Entity Knowledge within Rule-Based Machine Translation Models for Under-Resourced Neural Machine Translation Scenarios
Sep 28, 2020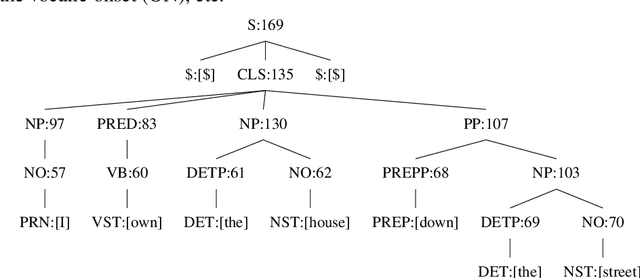
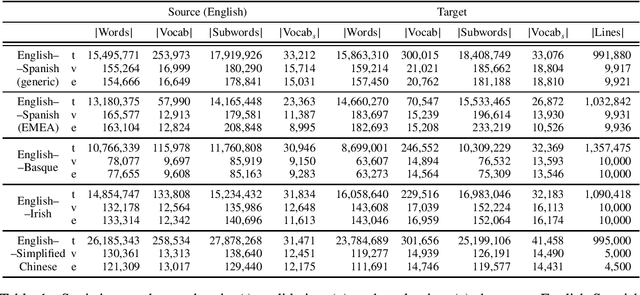
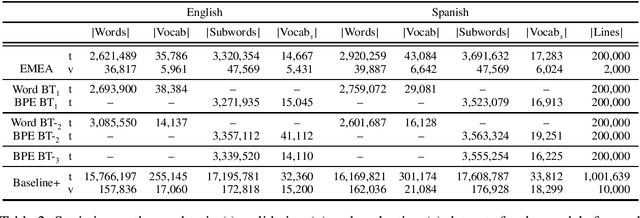

Rule-based machine translation is a machine translation paradigm where linguistic knowledge is encoded by an expert in the form of rules that translate text from source to target language. While this approach grants extensive control over the output of the system, the cost of formalising the needed linguistic knowledge is much higher than training a corpus-based system, where a machine learning approach is used to automatically learn to translate from examples. In this paper, we describe different approaches to leverage the information contained in rule-based machine translation systems to improve a corpus-based one, namely, a neural machine translation model, with a focus on a low-resource scenario. Three different kinds of information were used: morphological information, named entities and terminology. In addition to evaluating the general performance of the system, we systematically analysed the performance of the proposed approaches when dealing with the targeted phenomena. Our results suggest that the proposed models have limited ability to learn from external information, and most approaches do not significantly alter the results of the automatic evaluation, but our preliminary qualitative evaluation shows that in certain cases the hypothesis generated by our system exhibit favourable behaviour such as keeping the use of passive voice.