 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Detection and Analysis on Social Media
Jan 24, 2019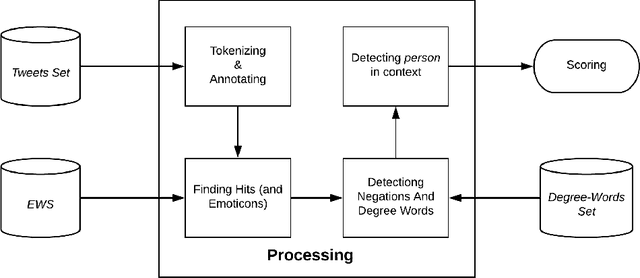
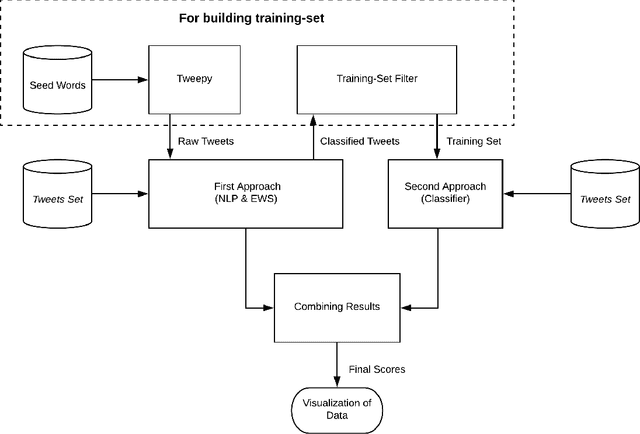
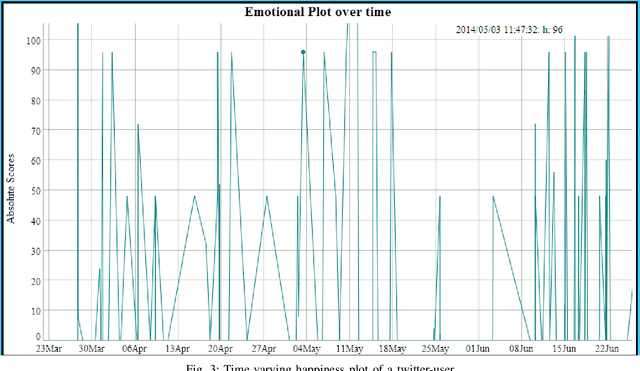
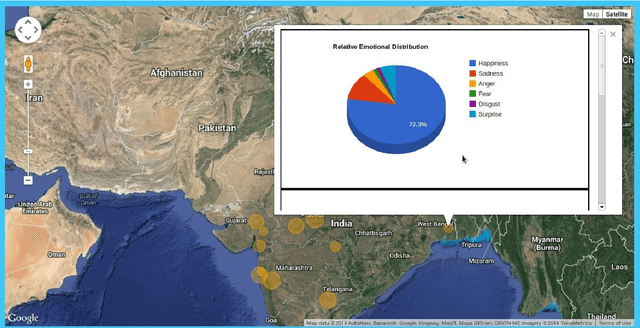
In this paper, we address the problem of detection, classification and quantification of emotions of text in any form. We consider English text collected from social media like Twitter, which can provide information having utility in a variety of ways, especially opinion mining. Social media like Twitter and Facebook is full of emotions, feelings and opinions of people all over the world. However, analyzing and classifying text on the basis of emotions is a big challenge and can be considered as an advanced form of Sentiment Analysis. This paper proposes a method to classify text into six different Emotion-Categories: Happiness, Sadness, Fear, Anger, Surprise and Disgust. In our model, we use two different approaches and combine them to effectively extract these emotions from text. The first approach is based on Natural Language Processing, and uses several textual features like emoticons, degree words and negations, Parts Of Speech and other grammatical analysis. The second approach is based on Machine Learning classification algorithms. We have also successfully devised a method to automate the creation of the training-set itself, so as to eliminate the need of manual annotation of large datasets. Moreover, we have managed to create a large bag of emotional words, along with their emotion-intensities. On testing, it is shown that our model provides significant accuracy in classifying tweets taken from Twitter.
Hybrid NER System for Multi-Source Offer Feeds
Jan 24, 2019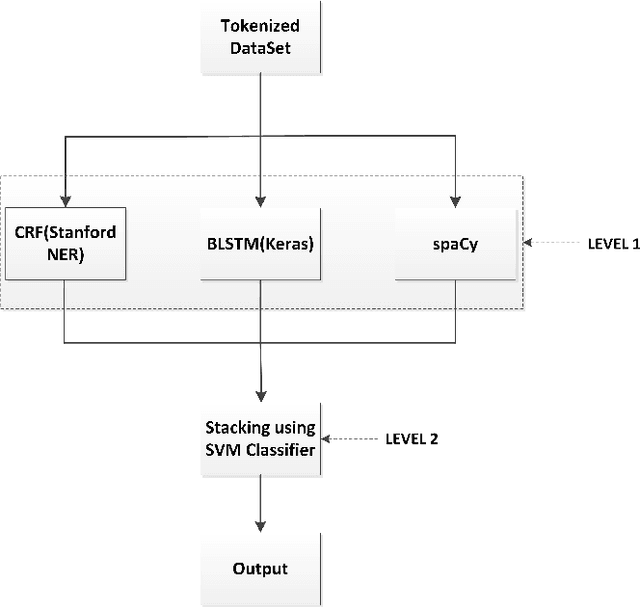
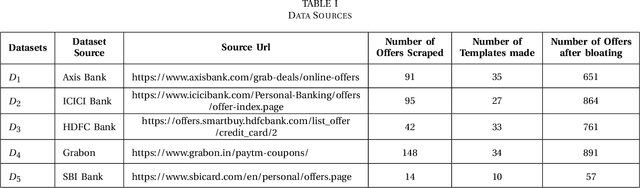
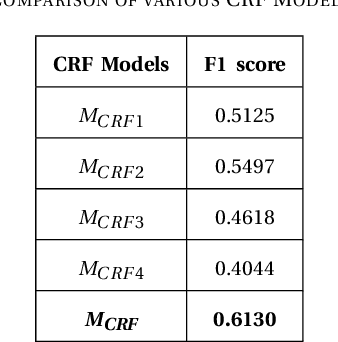
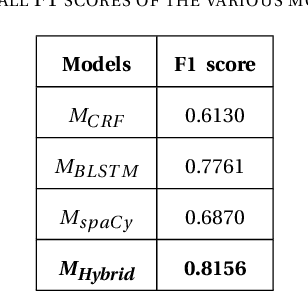
Data available across the web is largely unstructured. Offers published by multiple sources like banks, digital wallets, merchants, etc., are one of the most accessed advertising data in today's world. This data gets accessed by millions of people on a daily basis and is easily interpreted by humans, but since it is largely unstructured and diverse, using an algorithmic way to extract meaningful information out of these offers is hard. Identifying the essential offer entities (for instance, its amount, the product on which the offer is applicable, the merchant providing the offer, etc.) from these offers plays a vital role in targeting the right customers to improve sales. This work presents and evaluates various existing Named Entity Recognizer (NER) models which can identify the required entities from offer feeds. We also propose a novel Hybrid NER model constructed by two-level stacking of Conditional Random Field, Bidirectional LSTM and Spacy models at the first level and an SVM classifier at the second. The proposed hybrid model has been tested on offer feeds collected from multiple sources and has shown better performance in the offer domain when compared to the existing models.