 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery and Counterfactual Explanations for Personalized Student Learning
Sep 18, 2023



The paper focuses on identifying the causes of student performance to provide personalized recommendations for improving pass rates. We introduce the need to move beyond predictive models and instead identify causal relationships. We propose using causal discovery techniques to achieve this. The study's main contributions include using causal discovery to identify causal predictors of student performance and applying counterfactual analysis to provide personalized recommendations. The paper describes the application of causal discovery methods, specifically the PC algorithm, to real-life student performance data. It addresses challenges such as sample size limitations and emphasizes the role of domain knowledge in causal discovery. The results reveal the identified causal relationships, such as the influence of earlier test grades and mathematical ability on final student performance. Limitations of this study include the reliance on domain expertise for accurate causal discovery, and the necessity of larger sample sizes for reliable results. The potential for incorrect causal structure estimations is acknowledged. A major challenge remains, which is the real-time implementation and validation of counterfactual recommendations. In conclusion, the paper demonstrates the value of causal discovery for understanding student performance and providing personalized recommendations. It highlights the challenges, benefits, and limitations of using causal inference in an educational context, setting the stage for future studies to further explore and refine these methods.
Evaluating counterfactual explanations using Pearl's counterfactual method
Jan 06, 2023Counterfactual explanations (CEs) are methods for generating an alternative scenario that produces a different desirable outcome. For example, if a student is predicted to fail a course, then counterfactual explanations can provide the student with alternate ways so that they would be predicted to pass. The applications are many. However, CEs are currently generated from machine learning models that do not necessarily take into account the true causal structure in the data. By doing this, bias can be introduced into the CE quantities. I propose in this study to test the CEs using Judea Pearl's method of computing counterfactuals which has thus far, surprisingly, not been seen in the counterfactual explanation (CE) literature. I furthermore evaluate these CEs on three different causal structures to show how the true underlying causal structure affects the CEs that are generated. This study presented a method of evaluating CEs using Pearl's method and it showed, (although using a limited sample size), that thirty percent of the CEs conflicted with those computed by Pearl's method. This shows that we cannot simply trust CEs and it is vital for us to know the true causal structure before we blindly compute counterfactuals using the original machine learning model.
Predicting treatment effects from observational studies using machine learning methods: A simulation study
Dec 20, 2021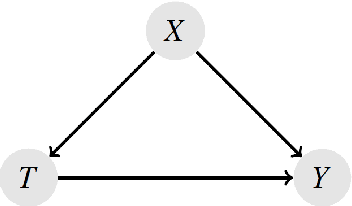

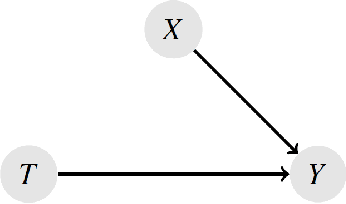
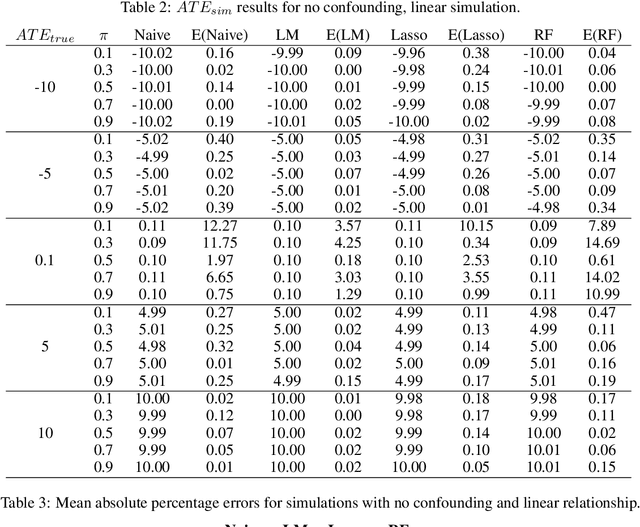
Measuring treatment effects in observational studies is challenging because of confounding bias. Confounding occurs when a variable affects both the treatment and the outcome. Traditional methods such as propensity score matching estimate treatment effects by conditioning on the confounders. Recent literature has presented new methods that use machine learning to predict the counterfactuals in observational studies which then allow for estimating treatment effects. These studies however, have been applied to real world data where the true treatment effects have not been known. This study aimed to study the effectiveness of this counterfactual prediction method by simulating two main scenarios: with and without confounding. Each type also included linear and non-linear relationships between input and output data. The key item in the simulations was that we generated known true causal effects. Linear regression, lasso regression and random forest models were used to predict the counterfactuals and treatment effects. These were compared these with the true treatment effect as well as a naive treatment effect. The results show that the most important factor in whether this machine learning method performs well, is the degree of non-linearity in the data. Surprisingly, for both non-confounding \textit{and} confounding, the machine learning models all performed well on the linear dataset. However, when non-linearity was introduced, the models performed very poorly. Therefore under the conditions of this simulation study, the machine learning method performs well under conditions of linearity, even if confounding is present, but at this stage should not be trusted when non-linearity is introduced.