 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Accuracy of CRNNs for Line-Based OCR: A Multi-Parameter Evaluation
Aug 06, 2020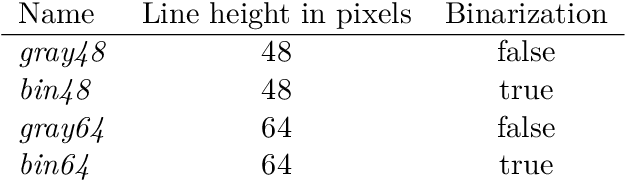



We investigate how to train a high quality optical character recognition (OCR) model for difficult historical typefaces on degraded paper. Through extensive grid searches, we obtain a neural network architecture and a set of optimal data augmentation settings. We discuss the influence of factors such as binarization, input line height, network width, network depth, and other network training parameters such as dropout. Implementing these findings into a practical model, we are able to obtain a 0.44% character error rate (CER) model from only 10,000 lines of training data, outperforming currently available pretrained models that were trained on more than 20 times the amount of data. We show ablations for all components of our training pipeline, which relies on the open source framework Calamari.
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Apr 15, 2020



One important and particularly challenging step in the optical character recognition (OCR) of historical documents with complex layouts, such as newspapers, is the separation of text from non-text content (e.g. page borders or illustrations). This step is commonly referred to as page segmentation. While various rule-based algorithms have been proposed, the applicability of Deep Neural Networks (DNNs) for this task recently has gained a lot of attention. In this paper, we perform a systematic evaluation of 11 different published DNN backbone architectures and 9 different tiling and scaling configurations for separating text, tables or table column lines. We also show the influence of the number of labels and the number of training pages on the segmentation quality, which we measure using the Matthews Correlation Coefficient. Our results show that (depending on the task) Inception-ResNet-v2 and EfficientNet backbones work best, vertical tiling is generally preferable to other tiling approaches, and training data that comprises 30 to 40 pages will be sufficient most of the time.