 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching Maximal Information Extraction in Low-Signal Regimes via Multiple Instance Learning
Aug 09, 2025In this work, we propose a new machine learning (ML) methodology to obtain more precise predictions for some parameters of interest in a given hypotheses testing problem. Our proposed method also allows ML models to have more discriminative power in cases where it is extremely challenging for state-of-the-art classifiers to have any level of accurate predictions. This method can also allow us to systematically decrease the error from ML models in their predictions. In this paper, we provide a mathematical motivation why Multiple Instance Learning (MIL) would have more predictive power over their single-instance counterparts. We support our theoretical claims by analyzing the behavior of the MIL models through their scaling behaviors with respect to the number of instances on which the model makes predictions. As a concrete application, we constrain Wilson coefficients of the Standard Model Effective Field Theory (SMEFT) using kinematic information from subatomic particle collision events at the Large Hadron Collider (LHC). We show that under certain circumstances, it might be possible to extract the theoretical maximum Fisher Information latent in a dataset.
CaloDVAE : Discrete Variational Autoencoders for Fast Calorimeter Shower Simulation
Oct 14, 2022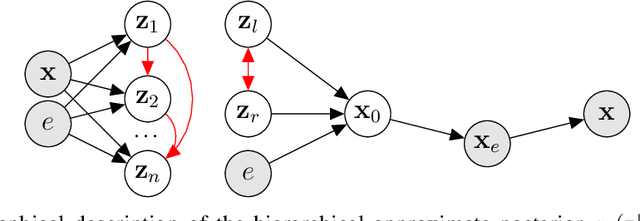

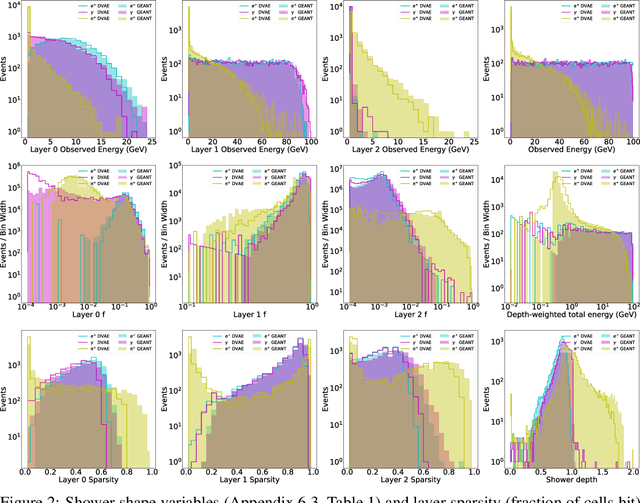

Calorimeter simulation is the most computationally expensive part of Monte Carlo generation of samples necessary for analysis of experimental data at the Large Hadron Collider (LHC). The High-Luminosity upgrade of the LHC would require an even larger amount of such samples. We present a technique based on Discrete Variational Autoencoders (DVAEs) to simulate particle showers in Electromagnetic Calorimeters. We discuss how this work paves the way towards exploration of quantum annealing processors as sampling devices for generation of simulated High Energy Physics datasets.