 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Influence of Machine Translation on Language Origin Obfuscation
Jun 24, 2021


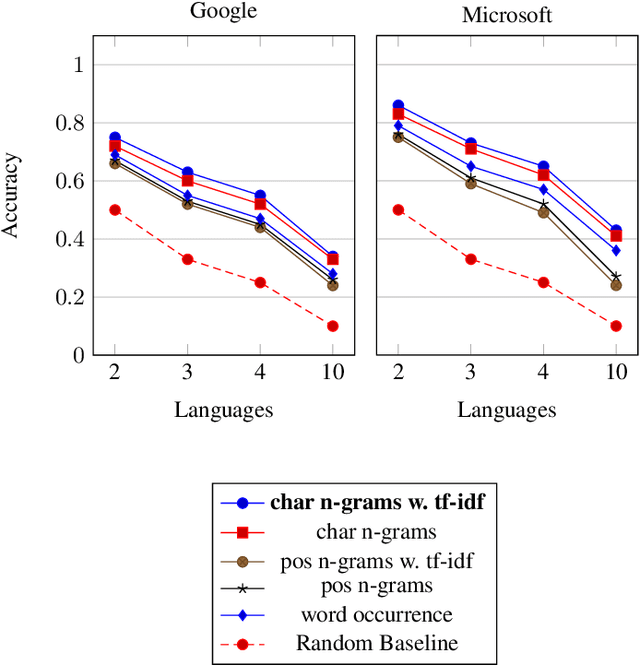
In the last decade, machine translation has become a popular means to deal with multilingual digital content. By providing higher quality translations, obfuscating the source language of a text becomes more attractive. In this paper, we analyze the ability to detect the source language from the translated output of two widely used commercial machine translation systems by utilizing machine-learning algorithms with basic textual features like n-grams. Evaluations show that the source language can be reconstructed with high accuracy for documents that contain a sufficient amount of translated text. In addition, we analyze how the document size influences the performance of the prediction, as well as how limiting the set of possible source languages improves the classification accuracy.
DT-grams: Structured Dependency Grammar Stylometry for Cross-Language Authorship Attribution
Jun 10, 2021

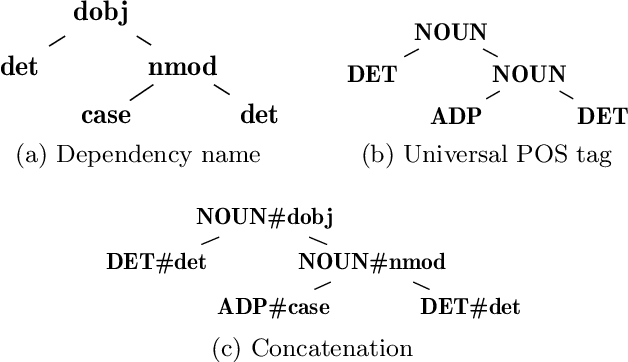

Cross-language authorship attribution problems rely on either translation to enable the use of single-language features, or language-independent feature extraction methods. Until recently, the lack of datasets for this problem hindered the development of the latter, and single-language solutions were performed on machine-translated corpora. In this paper, we present a novel language-independent feature for authorship analysis based on dependency graphs and universal part of speech tags, called DT-grams (dependency tree grams), which are constructed by selecting specific sub-parts of the dependency graph of sentences. We evaluate DT-grams by performing cross-language authorship attribution on untranslated datasets of bilingual authors, showing that, on average, they achieve a macro-averaged F1 score of 0.081 higher than previous methods across five different language pairs. Additionally, by providing results for a diverse set of features for comparison, we provide a baseline on the previously undocumented task of untranslated cross-language authorship attribution.