 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired, Task-Free Continual Learning through Activity Regularization
Dec 08, 2022The ability to sequentially learn multiple tasks without forgetting is a key skill of biological brains, whereas it represents a major challenge to the field of deep learning. To avoid catastrophic forgetting, various continual learning (CL) approaches have been devised. However, these usually require discrete task boundaries. This requirement seems biologically implausible and often limits the application of CL methods in the real world where tasks are not always well defined. Here, we take inspiration from neuroscience, where sparse, non-overlapping neuronal representations have been suggested to prevent catastrophic forgetting. As in the brain, we argue that these sparse representations should be chosen on the basis of feed forward (stimulus-specific) as well as top-down (context-specific) information. To implement such selective sparsity, we use a bio-plausible form of hierarchical credit assignment known as Deep Feedback Control (DFC) and combine it with a winner-take-all sparsity mechanism. In addition to sparsity, we introduce lateral recurrent connections within each layer to further protect previously learned representations. We evaluate the new sparse-recurrent version of DFC on the split-MNIST computer vision benchmark and show that only the combination of sparsity and intra-layer recurrent connections improves CL performance with respect to standard backpropagation. Our method achieves similar performance to well-known CL methods, such as Elastic Weight Consolidation and Synaptic Intelligence, without requiring information about task boundaries. Overall, we showcase the idea of adopting computational principles from the brain to derive new, task-free learning algorithms for CL.
Meta-Learning via Classifier(-free) Guidance
Oct 17, 2022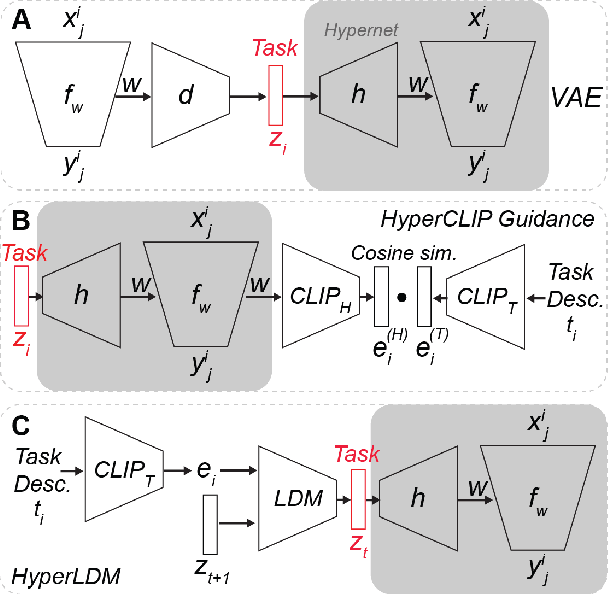
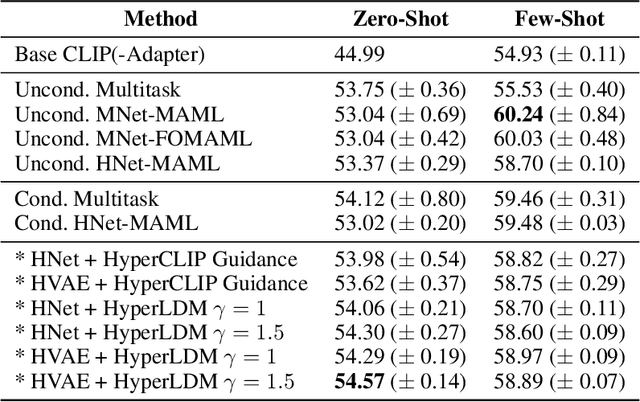


State-of-the-art meta-learning techniques do not optimize for zero-shot adaptation to unseen tasks, a setting in which humans excel. On the contrary, meta-learning algorithms learn hyperparameters and weight initializations that explicitly optimize for few-shot learning performance. In this work, we take inspiration from recent advances in generative modeling and language-conditioned image synthesis to propose meta-learning techniques that use natural language guidance to achieve higher zero-shot performance compared to the state-of-the-art. We do so by recasting the meta-learning problem as a multi-modal generative modeling problem: given a task, we consider its adapted neural network weights and its natural language description as equivalent multi-modal task representations. We first train an unconditional generative hypernetwork model to produce neural network weights; then we train a second "guidance" model that, given a natural language task description, traverses the hypernetwork latent space to find high-performance task-adapted weights in a zero-shot manner. We explore two alternative approaches for latent space guidance: "HyperCLIP"-based classifier guidance and a conditional Hypernetwork Latent Diffusion Model ("HyperLDM"), which we show to benefit from the classifier-free guidance technique common in image generation. Finally, we demonstrate that our approaches outperform existing meta-learning methods with zero-shot learning experiments on our Meta-VQA dataset, which we specifically constructed to reflect the multi-modal meta-learning setting.
Homomorphism Autoencoder -- Learning Group Structured Representations from Observed Transitions
Jul 25, 2022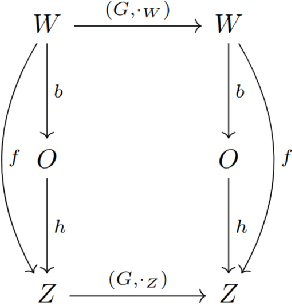

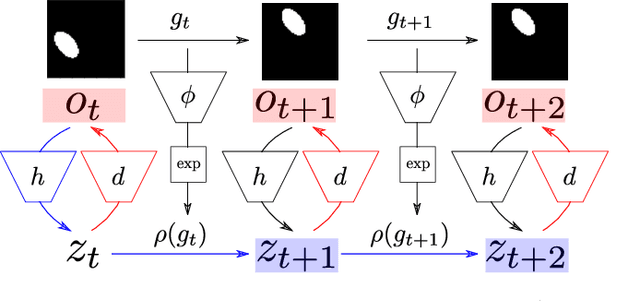

How can we acquire world models that veridically represent the outside world both in terms of what is there and in terms of how our actions affect it? Can we acquire such models by interacting with the world, and can we state mathematical desiderata for their relationship with a hypothetical reality existing outside our heads? As machine learning is moving towards representations containing not just observational but also interventional knowledge, we study these problems using tools from representation learning and group theory. Under the assumption that our actuators act upon the world, we propose methods to learn internal representations of not just sensory information but also of actions that modify our sensory representations in a way that is consistent with the actions and transitions in the world. We use an autoencoder equipped with a group representation linearly acting on its latent space, trained on 2-step reconstruction such as to enforce a suitable homomorphism property on the group representation. Compared to existing work, our approach makes fewer assumptions on the group representation and on which transformations the agent can sample from the group. We motivate our method theoretically, and demonstrate empirically that it can learn the correct representation of the groups and the topology of the environment. We also compare its performance in trajectory prediction with previous methods.
Minimizing Control for Credit Assignment with Strong Feedback
Apr 14, 2022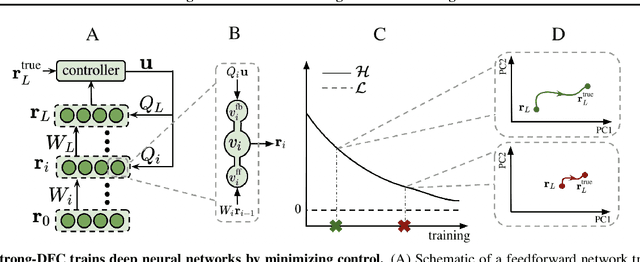

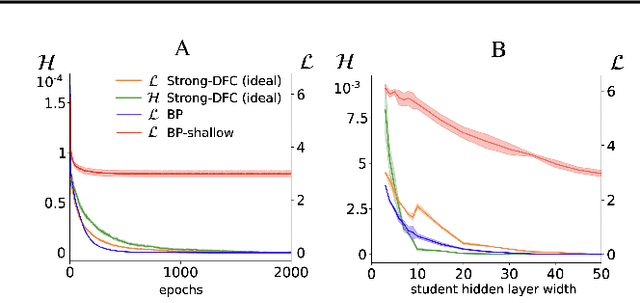
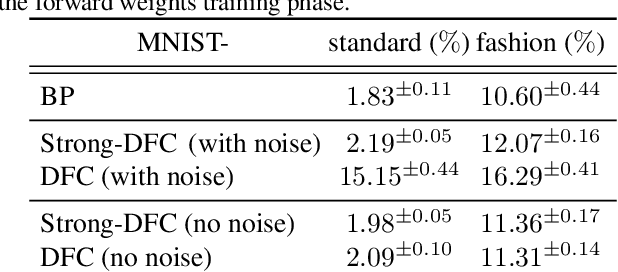
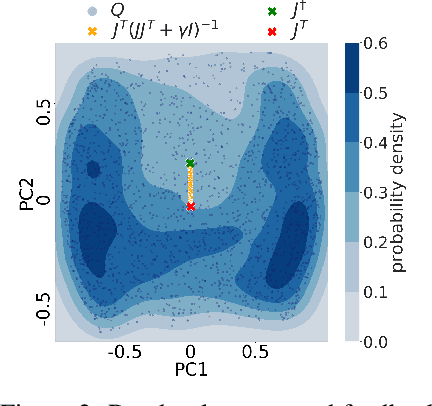
The success of deep learning attracted interest in whether the brain learns hierarchical representations using gradient-based learning. However, current biologically plausible methods for gradient-based credit assignment in deep neural networks need infinitesimally small feedback signals, which is problematic in biologically realistic noisy environments and at odds with experimental evidence in neuroscience showing that top-down feedback can significantly influence neural activity. Building upon deep feedback control (DFC), a recently proposed credit assignment method, we combine strong feedback influences on neural activity with gradient-based learning and show that this naturally leads to a novel view on neural network optimization. Instead of gradually changing the network weights towards configurations with low output loss, weight updates gradually minimize the amount of feedback required from a controller that drives the network to the supervised output label. Moreover, we show that the use of strong feedback in DFC allows learning forward and feedback connections simultaneously, using a learning rule fully local in space and time. We complement our theoretical results with experiments on standard computer-vision benchmarks, showing competitive performance to backpropagation as well as robustness to noise. Overall, our work presents a fundamentally novel view of learning as control minimization, while sidestepping biologically unrealistic assumptions.
Uncertainty estimation under model misspecification in neural network regression
Nov 23, 2021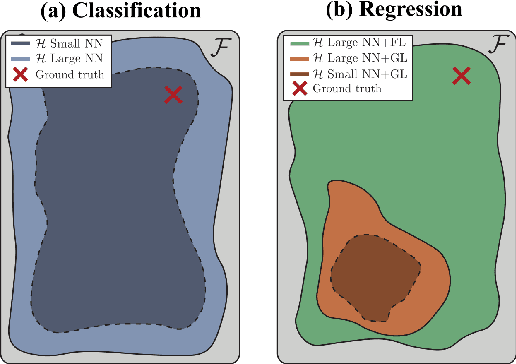
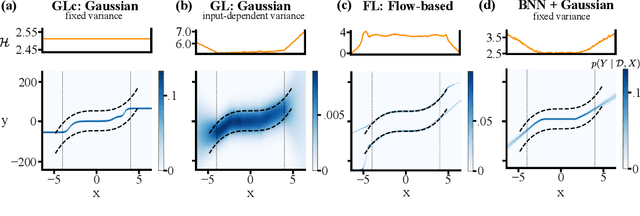
Although neural networks are powerful function approximators, the underlying modelling assumptions ultimately define the likelihood and thus the hypothesis class they are parameterizing. In classification, these assumptions are minimal as the commonly employed softmax is capable of representing any categorical distribution. In regression, however, restrictive assumptions on the type of continuous distribution to be realized are typically placed, like the dominant choice of training via mean-squared error and its underlying Gaussianity assumption. Recently, modelling advances allow to be agnostic to the type of continuous distribution to be modelled, granting regression the flexibility of classification models. While past studies stress the benefit of such flexible regression models in terms of performance, here we study the effect of the model choice on uncertainty estimation. We highlight that under model misspecification, aleatoric uncertainty is not properly captured, and that a Bayesian treatment of a misspecified model leads to unreliable epistemic uncertainty estimates. Overall, our study provides an overview on how modelling choices in regression may influence uncertainty estimation and thus any downstream decision making process.
Are Bayesian neural networks intrinsically good at out-of-distribution detection?
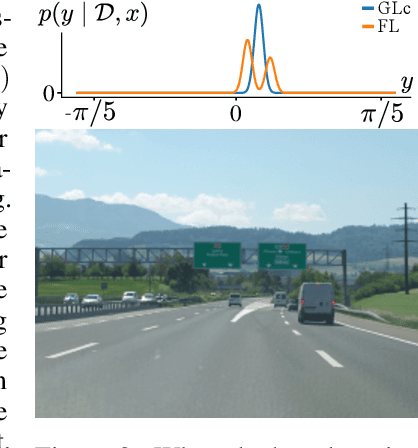
Jul 26, 2021
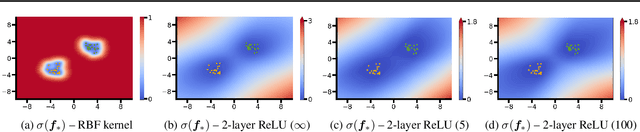
The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNN) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and provide empirical evidence that proper Bayesian inference with common neural network architectures does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact considering the corresponding Gaussian process. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Finally, we study finite-width networks using HMC, and observe OOD behavior that is consistent with the infinite-width case. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
Credit Assignment in Neural Networks through Deep Feedback Control
Jun 15, 2021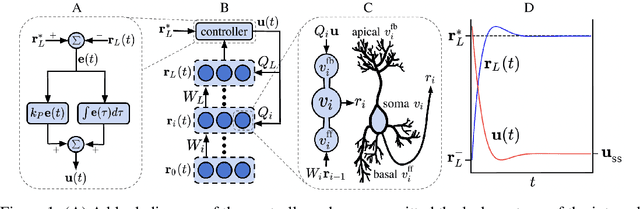
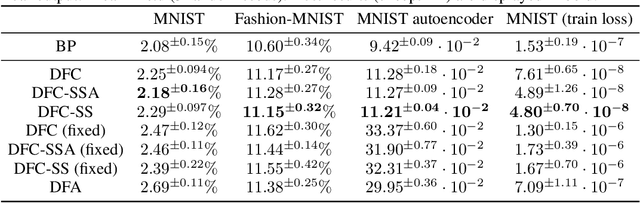
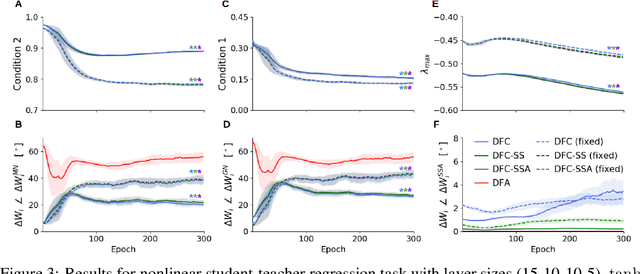
The success of deep learning sparked interest in whether the brain learns by using similar techniques for assigning credit to each synaptic weight for its contribution to the network output. However, the majority of current attempts at biologically-plausible learning methods are either non-local in time, require highly specific connectivity motives, or have no clear link to any known mathematical optimization method. Here, we introduce Deep Feedback Control (DFC), a new learning method that uses a feedback controller to drive a deep neural network to match a desired output target and whose control signal can be used for credit assignment. The resulting learning rule is fully local in space and time and approximates Gauss-Newton optimization for a wide range of feedback connectivity patterns. To further underline its biological plausibility, we relate DFC to a multi-compartment model of cortical pyramidal neurons with a local voltage-dependent synaptic plasticity rule, consistent with recent theories of dendritic processing. By combining dynamical system theory with mathematical optimization theory, we provide a strong theoretical foundation for DFC that we corroborate with detailed results on toy experiments and standard computer-vision benchmarks.
Posterior Meta-Replay for Continual Learning
Mar 01, 2021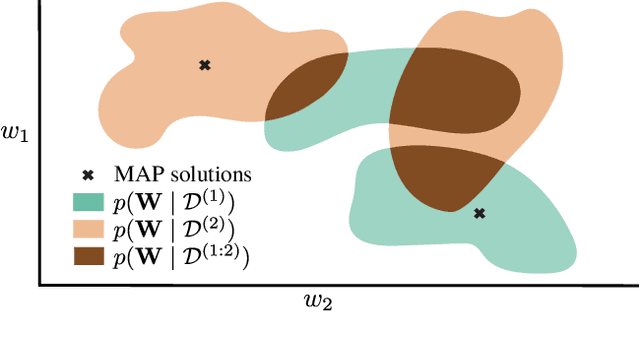
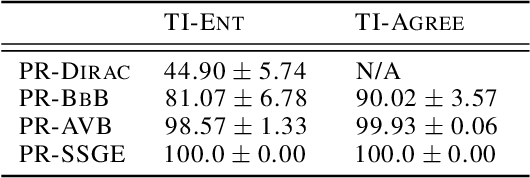
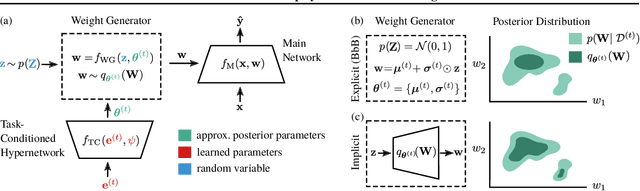
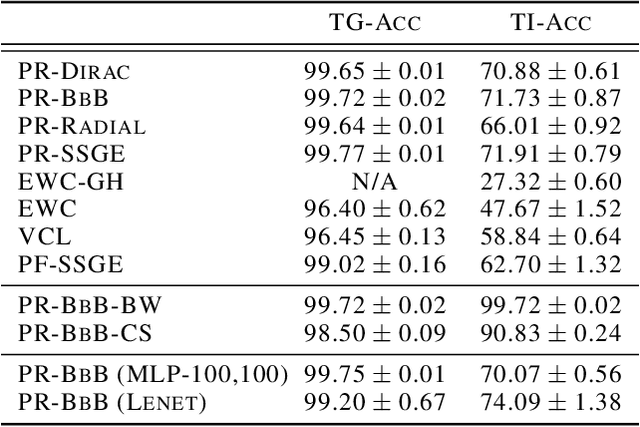
Continual Learning (CL) algorithms have recently received a lot of attention as they attempt to overcome the need to train with an i.i.d. sample from some unknown target data distribution. Building on prior work, we study principled ways to tackle the CL problem by adopting a Bayesian perspective and focus on continually learning a task-specific posterior distribution via a shared meta-model, a task-conditioned hypernetwork. This approach, which we term Posterior-replay CL, is in sharp contrast to most Bayesian CL approaches that focus on the recursive update of a single posterior distribution. The benefits of our approach are (1) an increased flexibility to model solutions in weight space and therewith less susceptibility to task dissimilarity, (2) access to principled task-specific predictive uncertainty estimates, that can be used to infer task identity during test time and to detect task boundaries during training, and (3) the ability to revisit and update task-specific posteriors in a principled manner without requiring access to past data. The proposed framework is versatile, which we demonstrate using simple posterior approximations (such as Gaussians) as well as powerful, implicit distributions modelled via a neural network. We illustrate the conceptual advance of our framework on low-dimensional problems and show performance gains on computer vision benchmarks.
Economical ensembles with hypernetworks
Jul 25, 2020


Averaging the predictions of many independently trained neural networks is a simple and effective way of improving generalization in deep learning. However, this strategy rapidly becomes costly, as the number of trainable parameters grows linearly with the size of the ensemble. Here, we propose a new method to learn economical ensembles, where the number of trainable parameters and iterations over the data is comparable to that of a single model. Our neural networks are parameterized by hypernetworks, which learn to embed weights in low-dimensional spaces. In a late training phase, we generate an ensemble by randomly initializing an additional number of weight embeddings in the vicinity of each other. We then exploit the inherent randomness in stochastic gradient descent to induce ensemble diversity. Experiments with wide residual networks on the CIFAR and Fashion-MNIST datasets show that our algorithm yields models that are more accurate and less overconfident on unseen data, while learning as efficiently as a single network.
A Theoretical Framework for Target Propagation
Jun 25, 2020
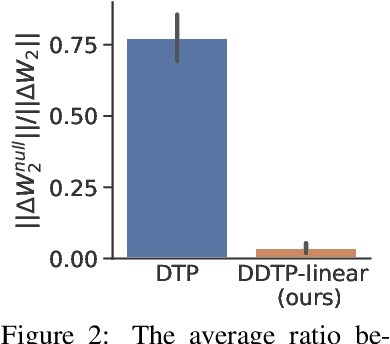
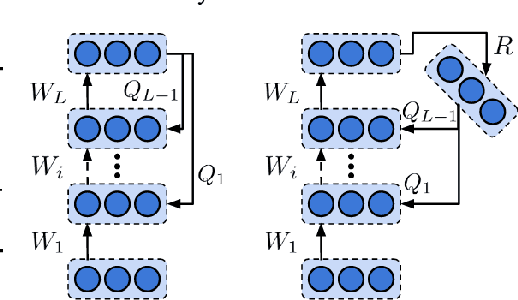
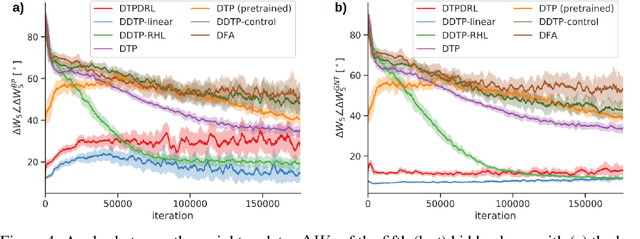
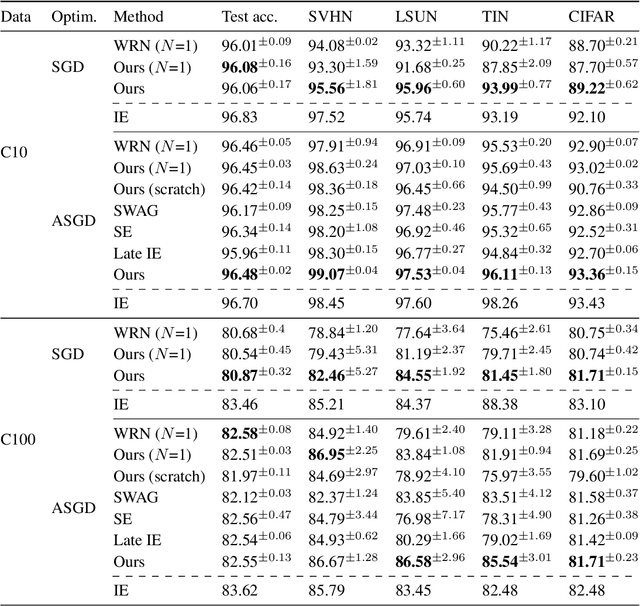
The success of deep learning, a brain-inspired form of AI, has sparked interest in understanding how the brain could similarly learn across multiple layers of neurons. However, the majority of biologically-plausible learning algorithms have not yet reached the performance of backpropagation (BP), nor are they built on strong theoretical foundations. Here, we analyze target propagation (TP), a popular but not yet fully understood alternative to BP, from the standpoint of mathematical optimization. Our theory shows that TP is closely related to Gauss-Newton optimization and thus substantially differs from BP. Furthermore, our analysis reveals a fundamental limitation of difference target propagation (DTP), a well-known variant of TP, in the realistic scenario of non-invertible neural networks. We provide a first solution to this problem through a novel reconstruction loss that improves feedback weight training, while simultaneously introducing architectural flexibility by allowing for direct feedback connections from the output to each hidden layer. Our theory is corroborated by experimental results that show significant improvements in performance and in the alignment of forward weight updates with loss gradients, compared to DTP.