 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecatch22: CAnonical Time-series CHaracteristics
Jan 30, 2019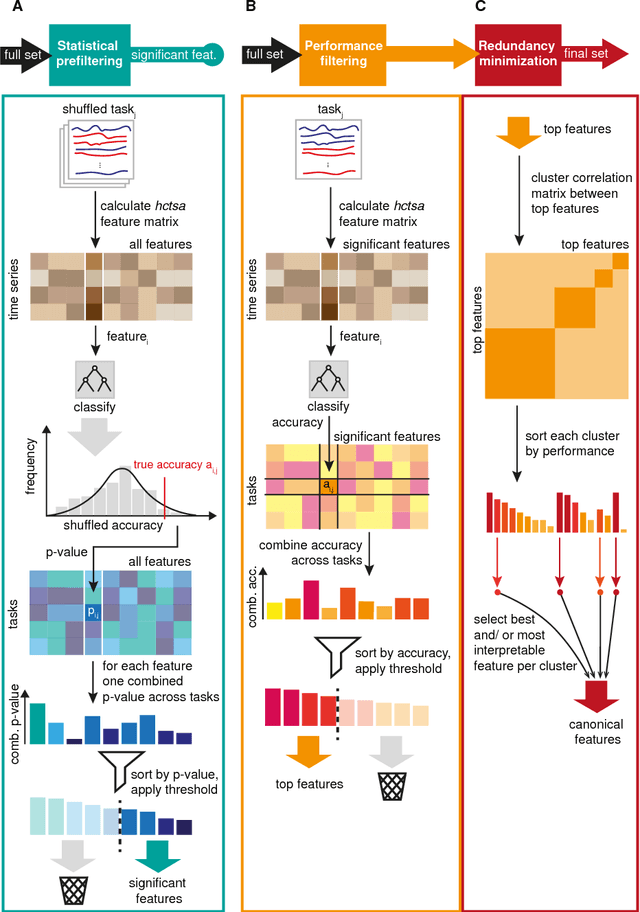

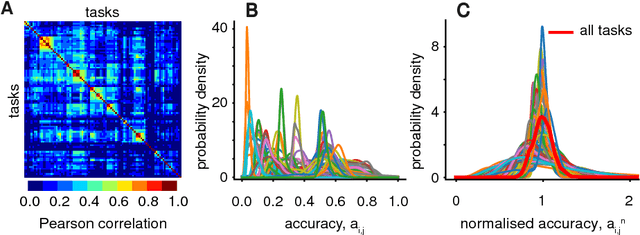
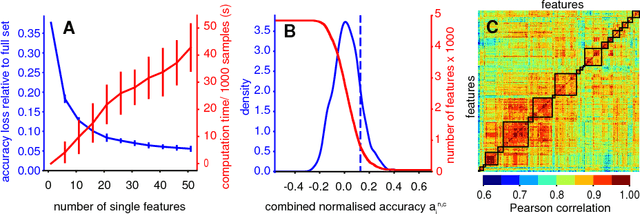
Capturing the dynamical properties of time series concisely as interpretable feature vectors can enable efficient clustering and classification for time-series applications across science and industry. Selecting an appropriate feature-based representation of time series for a given application can be achieved through systematic comparison across a comprehensive time-series feature library, such as those in the hctsa toolbox. However, this approach is computationally expensive and involves evaluating many similar features, limiting the widespread adoption of feature-based representations of time series for real-world applications. In this work, we introduce a method to infer small sets of time-series features that (i) exhibit strong classification performance across a given collection of time-series problems, and (ii) are minimally redundant. Applying our method to a set of 93 time-series classification datasets (containing over 147000 time series) and using a filtered version of the hctsa feature library (4791 features), we introduce a generically useful set of 22 CAnonical Time-series CHaracteristics, catch22. This dimensionality reduction, from 4791 to 22, is associated with an approximately 1000-fold reduction in computation time and near linear scaling with time-series length, despite an average reduction in classification accuracy of just 7%. catch22 captures a diverse and interpretable signature of time series in terms of their properties, including linear and non-linear autocorrelation, successive differences, value distributions and outliers, and fluctuation scaling properties. We provide an efficient implementation of catch22, accessible from many programming environments, that facilitates feature-based time-series analysis for scientific, industrial, financial and medical applications using a common language of interpretable time-series properties.
Automatic time-series phenotyping using massive feature extraction
Dec 15, 2016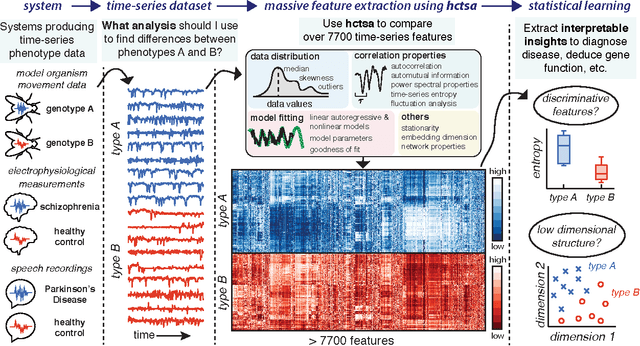
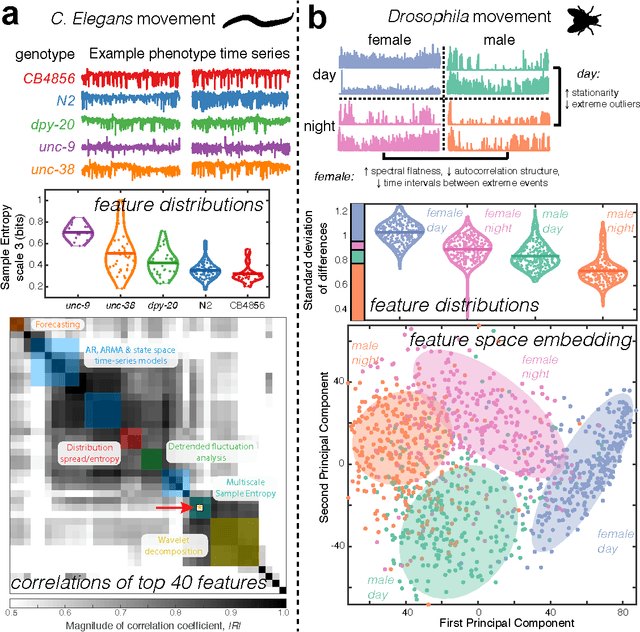
Across a far-reaching diversity of scientific and industrial applications, a general key problem involves relating the structure of time-series data to a meaningful outcome, such as detecting anomalous events from sensor recordings, or diagnosing patients from physiological time-series measurements like heart rate or brain activity. Currently, researchers must devote considerable effort manually devising, or searching for, properties of their time series that are suitable for the particular analysis problem at hand. Addressing this non-systematic and time-consuming procedure, here we introduce a new tool, hctsa, that selects interpretable and useful properties of time series automatically, by comparing implementations over 7700 time-series features drawn from diverse scientific literatures. Using two exemplar biological applications, we show how hctsa allows researchers to leverage decades of time-series research to quantify and understand informative structure in their time-series data.