 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSCATeR: Sparse Scatter-Based Convolution Algorithm with Temporal Data Recycling for Real-Time 3D Object Detection in LiDAR Point Clouds
Dec 19, 2025This work leverages the continuous sweeping motion of LiDAR scanning to concentrate object detection efforts on specific regions that receive a change in point data from one frame to another. We achieve this by using a sliding time window with short strides and consider the temporal dimension by storing convolution results between passes. This allows us to ignore unchanged regions, significantly reducing the number of convolution operations per forward pass without sacrificing accuracy. This data reuse scheme introduces extreme sparsity to detection data. To exploit this sparsity, we extend our previous work on scatter-based convolutions to allow for data reuse, and as such propose Sparse Scatter-Based Convolution Algorithm with Temporal Data Recycling (SSCATeR). This operation treats incoming LiDAR data as a continuous stream and acts only on the changing parts of the point cloud. By doing so, we achieve the same results with as much as a 6.61-fold reduction in processing time. Our test results show that the feature maps output by our method are identical to those produced by traditional sparse convolution techniques, whilst greatly increasing the computational efficiency of the network.
Experimentally realized in situ backpropagation for deep learning in nanophotonic neural networks
May 17, 2022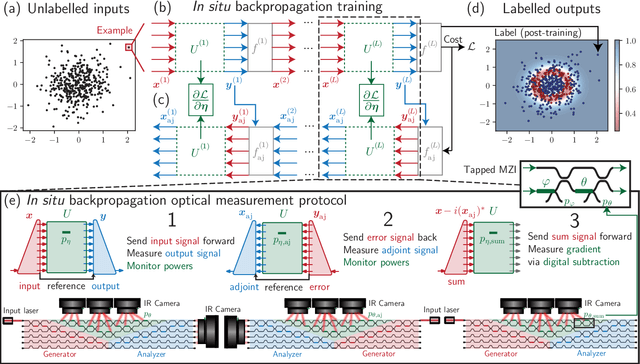
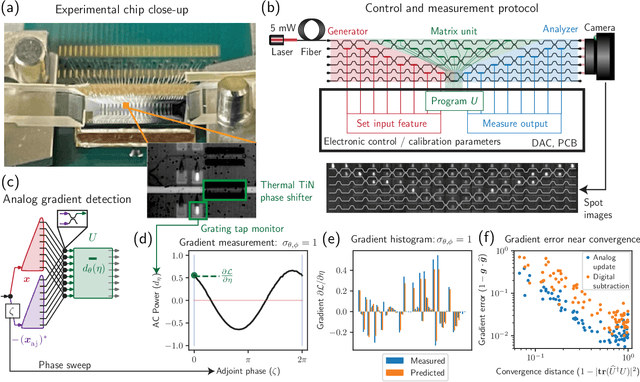
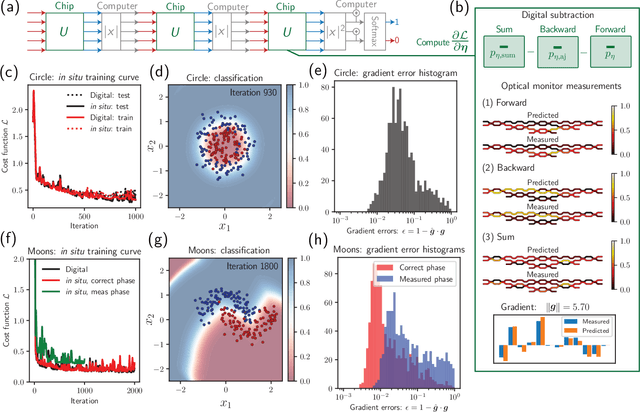
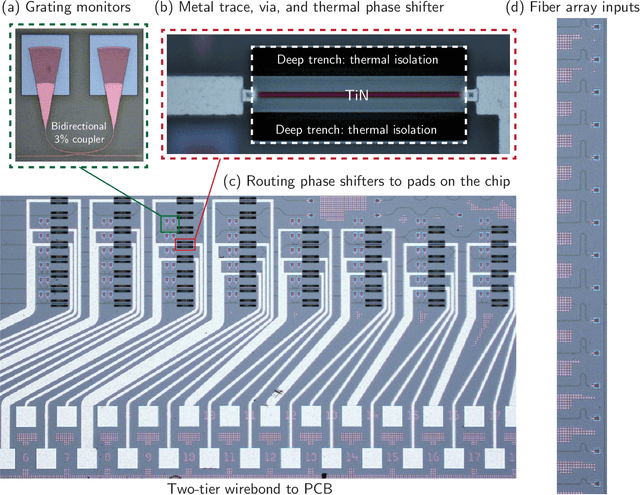
Neural networks are widely deployed models across many scientific disciplines and commercial endeavors ranging from edge computing and sensing to large-scale signal processing in data centers. The most efficient and well-entrenched method to train such networks is backpropagation, or reverse-mode automatic differentiation. To counter an exponentially increasing energy budget in the artificial intelligence sector, there has been recent interest in analog implementations of neural networks, specifically nanophotonic neural networks for which no analog backpropagation demonstration exists. We design mass-manufacturable silicon photonic neural networks that alternately cascade our custom designed "photonic mesh" accelerator with digitally implemented nonlinearities. These reconfigurable photonic meshes program computationally intensive arbitrary matrix multiplication by setting physical voltages that tune the interference of optically encoded input data propagating through integrated Mach-Zehnder interferometer networks. Here, using our packaged photonic chip, we demonstrate in situ backpropagation for the first time to solve classification tasks and evaluate a new protocol to keep the entire gradient measurement and update of physical device voltages in the analog domain, improving on past theoretical proposals. Our method is made possible by introducing three changes to typical photonic meshes: (1) measurements at optical "grating tap" monitors, (2) bidirectional optical signal propagation automated by fiber switch, and (3) universal generation and readout of optical amplitude and phase. After training, our classification achieves accuracies similar to digital equivalents even in presence of systematic error. Our findings suggest a new training paradigm for photonics-accelerated artificial intelligence based entirely on a physical analog of the popular backpropagation technique.
Reprogrammable Electro-Optic Nonlinear Activation Functions for Optical Neural Networks
Mar 12, 2019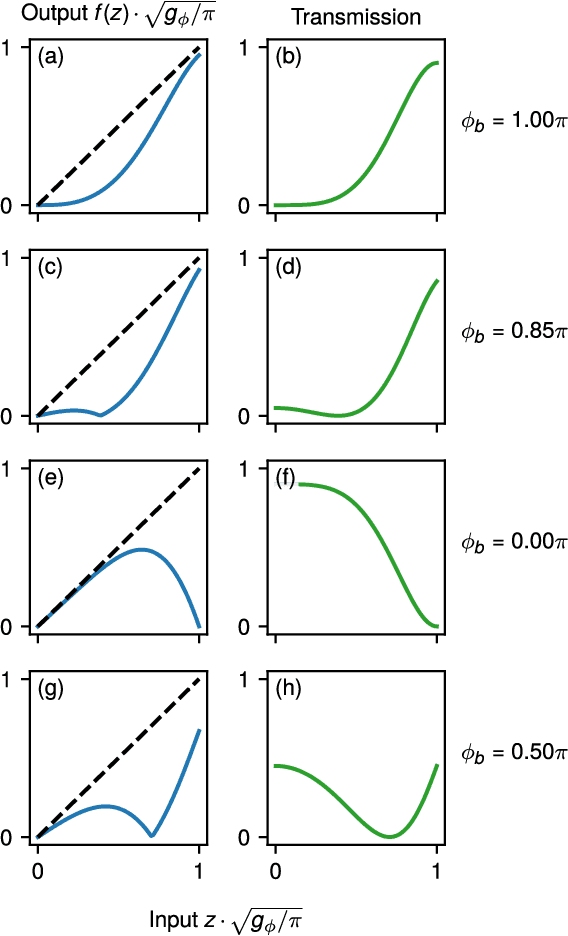
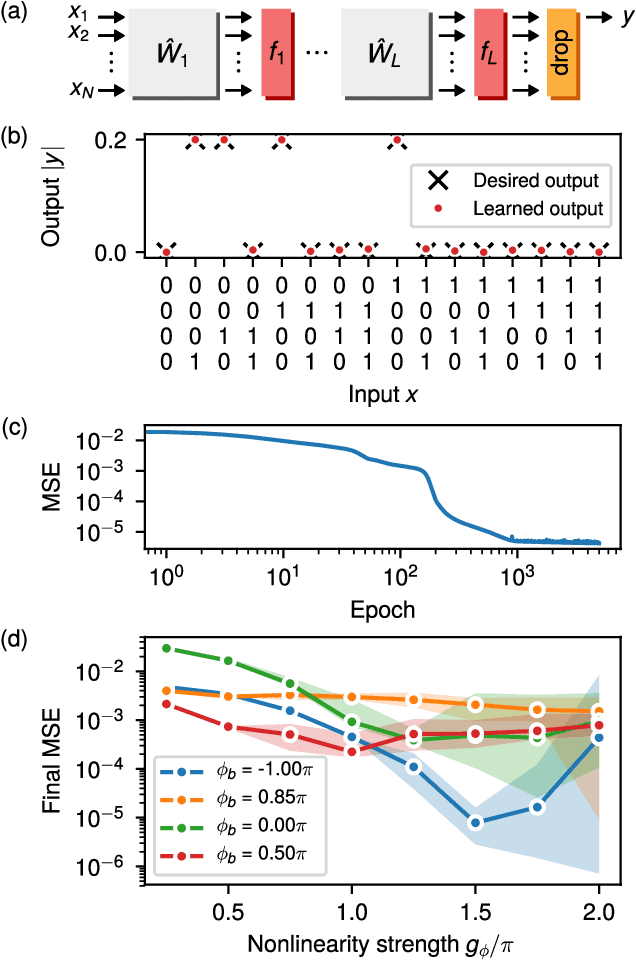
We introduce an electro-optic hardware platform for nonlinear activation functions in optical neural networks. The optical-to-optical nonlinearity operates by converting a small portion of the input optical signal into an analog electric signal, which is used to intensity-modulate the original optical signal with no reduction in operating speed. This scheme allows for complete nonlinear on-off contrast in transmission at relatively low optical power thresholds and eliminates the requirement of having additional optical sources between each layer of the network. Moreover, the activation function is reconfigurable via electrical bias, allowing it to be programmed or trained to synthesize a variety of nonlinear responses. Using numerical simulations, we demonstrate that this activation function significantly improves the expressiveness of optical neural networks, allowing them to perform well on two benchmark machine learning tasks: learning a multi-input exclusive-OR (XOR) logic function and classification of images of handwritten numbers from the MNIST dataset. The addition of the nonlinear activation function improves test accuracy on the MNIST task from 85% to 94%.
Matrix optimization on universal unitary photonic devices
Aug 02, 2018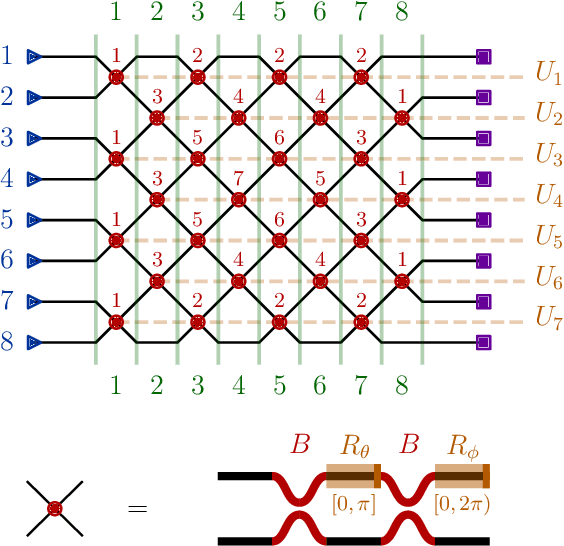
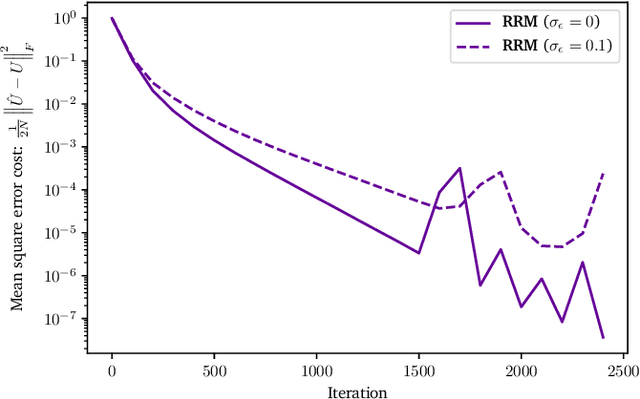
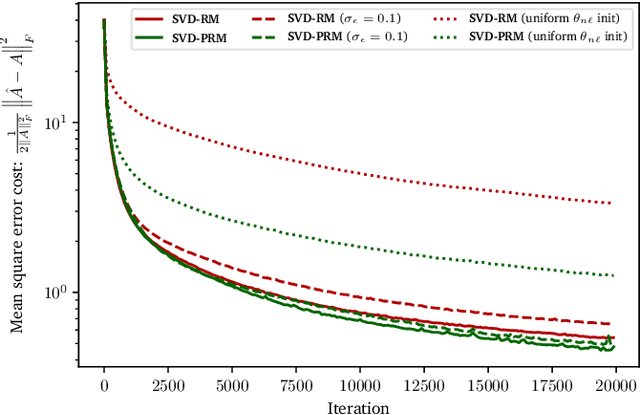
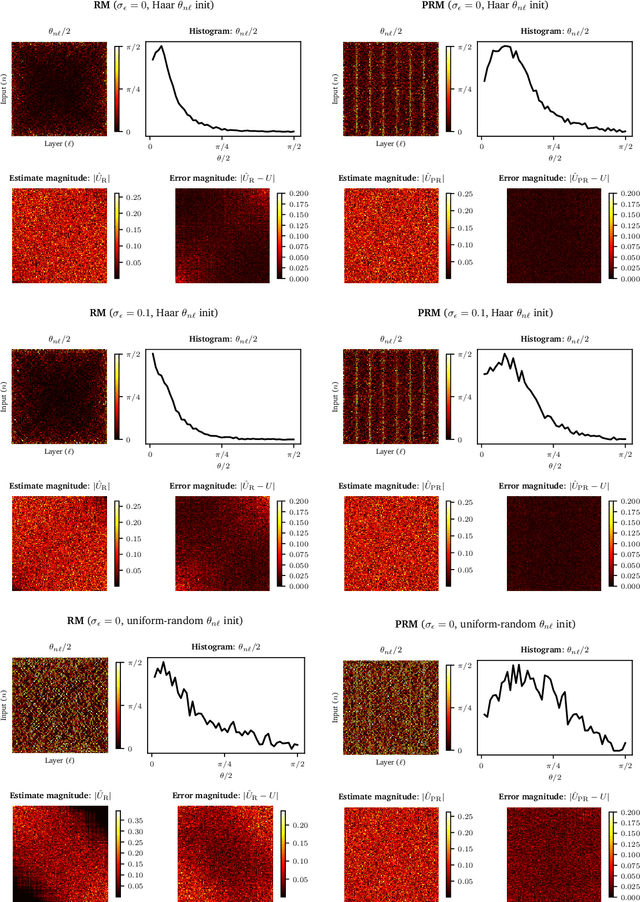
Universal unitary photonic devices are capable of applying arbitrary unitary transformations to multi-port coherent light inputs and provide a promising hardware platform for fast and energy-efficient machine learning. We address the problem of training universal photonic devices composed of meshes of tunable beamsplitters to learn unknown unitary matrices. The locally-interacting nature of the mesh components limits the fidelity of the learned matrices if phase shifts are randomly initialized. We propose an initialization procedure derived from the Haar measure over unitary matrices that overcomes this limitation. We also embed various model architectures within a standard rectangular mesh "canvas," and our numerical experiments show significantly improved scalability and training speed, even in the presence of fabrication errors.