 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and external validation of a multimodal artificial intelligence mortality prediction model of critically ill patients using multicenter data
Dec 15, 2025Early prediction of in-hospital mortality in critically ill patients can aid clinicians in optimizing treatment. The objective was to develop a multimodal deep learning model, using structured and unstructured clinical data, to predict in-hospital mortality risk among critically ill patients after their initial 24 hour intensive care unit (ICU) admission. We used data from MIMIC-III, MIMIC-IV, eICU, and HiRID. A multimodal model was developed on the MIMIC datasets, featuring time series components occurring within the first 24 hours of ICU admission and predicting risk of subsequent inpatient mortality. Inputs included time-invariant variables, time-variant variables, clinical notes, and chest X-ray images. External validation occurred in a temporally separated MIMIC population, HiRID, and eICU datasets. A total of 203,434 ICU admissions from more than 200 hospitals between 2001 to 2022 were included, in which mortality rate ranged from 5.2% to 7.9% across the four datasets. The model integrating structured data points had AUROC, AUPRC, and Brier scores of 0.92, 0.53, and 0.19, respectively. We externally validated the model on eight different institutions within the eICU dataset, demonstrating AUROCs ranging from 0.84-0.92. When including only patients with available clinical notes and imaging data, inclusion of notes and imaging into the model, the AUROC, AUPRC, and Brier score improved from 0.87 to 0.89, 0.43 to 0.48, and 0.37 to 0.17, respectively. Our findings highlight the importance of incorporating multiple sources of patient information for mortality prediction and the importance of external validation.
Prediction of Blood Lactate Values in Critically Ill Patients: A Retrospective Multi-center Cohort Study
Jul 07, 2021
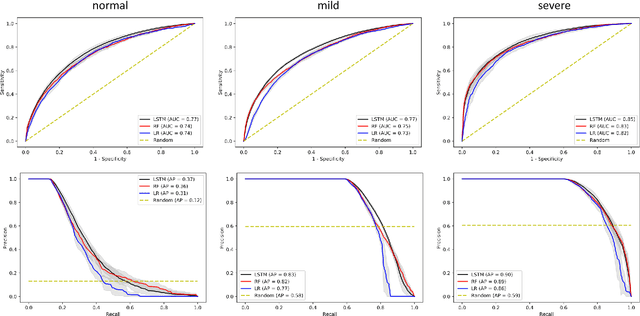
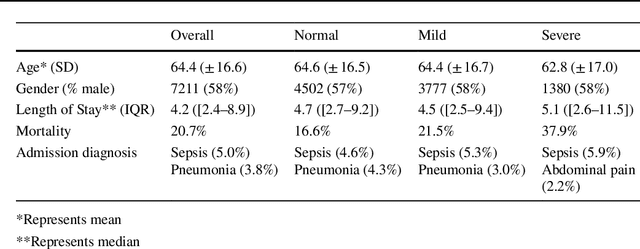
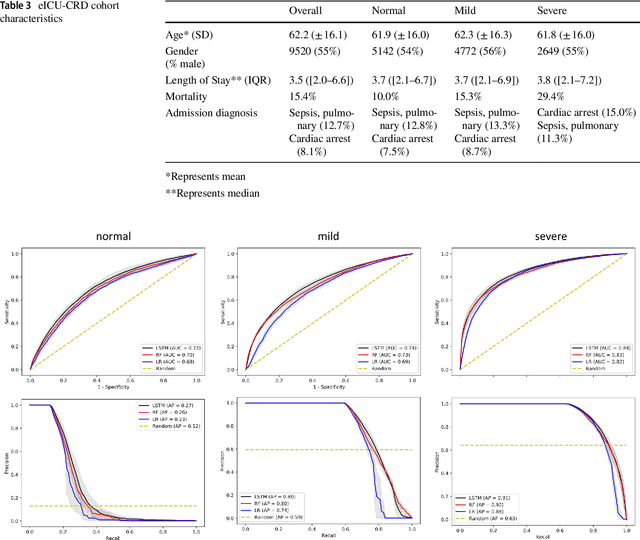
Purpose. Elevations in initially obtained serum lactate levels are strong predictors of mortality in critically ill patients. Identifying patients whose serum lactate levels are more likely to increase can alert physicians to intensify care and guide them in the frequency of tending the blood test. We investigate whether machine learning models can predict subsequent serum lactate changes. Methods. We investigated serum lactate change prediction using the MIMIC-III and eICU-CRD datasets in internal as well as external validation of the eICU cohort on the MIMIC-III cohort. Three subgroups were defined based on the initial lactate levels: i) normal group (<2 mmol/L), ii) mild group (2-4 mmol/L), and iii) severe group (>4 mmol/L). Outcomes were defined based on increase or decrease of serum lactate levels between the groups. We also performed sensitivity analysis by defining the outcome as lactate change of >10% and furthermore investigated the influence of the time interval between subsequent lactate measurements on predictive performance. Results. The LSTM models were able to predict deterioration of serum lactate values of MIMIC-III patients with an AUC of 0.77 (95% CI 0.762-0.771) for the normal group, 0.77 (95% CI 0.768-0.772) for the mild group, and 0.85 (95% CI 0.840-0.851) for the severe group, with a slightly lower performance in the external validation. Conclusion. The LSTM demonstrated good discrimination of patients who had deterioration in serum lactate levels. Clinical studies are needed to evaluate whether utilization of a clinical decision support tool based on these results could positively impact decision-making and patient outcomes.
* 15 pages, 6 Appendices
Blood lactate concentration prediction in critical care patients: handling missing values
Oct 03, 2019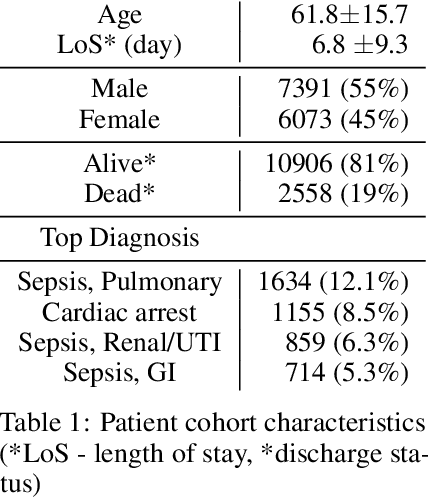
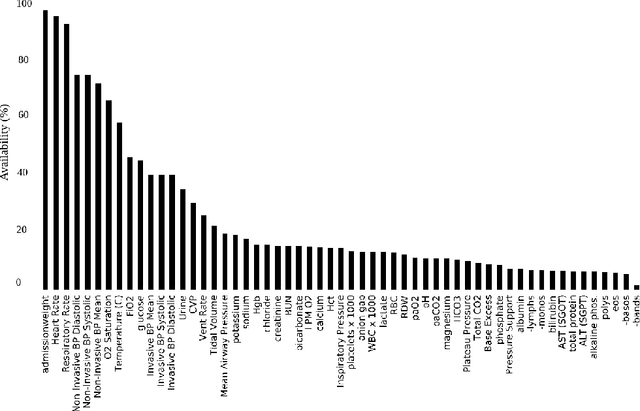
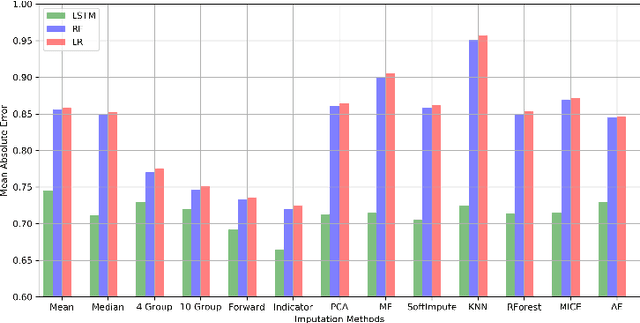
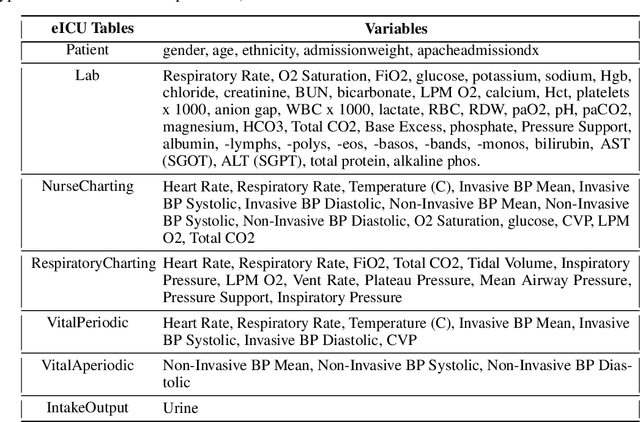
Blood lactate concentration is a strong indicator of mortality risk in critically ill patients. While frequent lactate measurements are necessary to assess patient's health state, the measurement is an invasive procedure that can increase risk of hospital-acquired infections. For this reason we formally define the problem of lactate prediction as a clinically relevant benchmark problem for machine learning community so as to assist clinical decision making in blood lactate testing. Accordingly, we demonstrate the relevant challenges of the problem and its data in addition to the adopted solutions. Also, we evaluate the performance of different prediction algorithms on a large dataset of ICU patients from the multi-centre eICU database. More specifically, we focus on investigating the impact of missing value imputation methods in lactate prediction for each algorithm. The experimental analysis shows promising prediction results that encourages further investigation of this problem.