 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering, Hamming Embedding, Generalized LSH and the Max Norm
May 13, 2014We study the convex relaxation of clustering and hamming embedding, focusing on the asymmetric case (co-clustering and asymmetric hamming embedding), understanding their relationship to LSH as studied by (Charikar 2002) and to the max-norm ball, and the differences between their symmetric and asymmetric versions.
Sparse Matrix Factorization
May 13, 2014We investigate the problem of factorizing a matrix into several sparse matrices and propose an algorithm for this under randomness and sparsity assumptions. This problem can be viewed as a simplification of the deep learning problem where finding a factorization corresponds to finding edges in different layers and values of hidden units. We prove that under certain assumptions for a sparse linear deep network with $n$ nodes in each layer, our algorithm is able to recover the structure of the network and values of top layer hidden units for depths up to $\tilde O(n^{1/6})$. We further discuss the relation among sparse matrix factorization, deep learning, sparse recovery and dictionary learning.
The Power of Asymmetry in Binary Hashing
Nov 29, 2013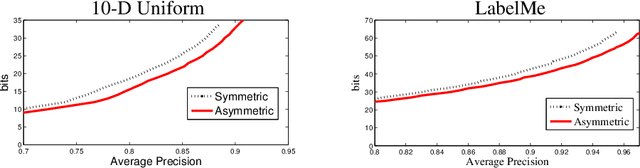
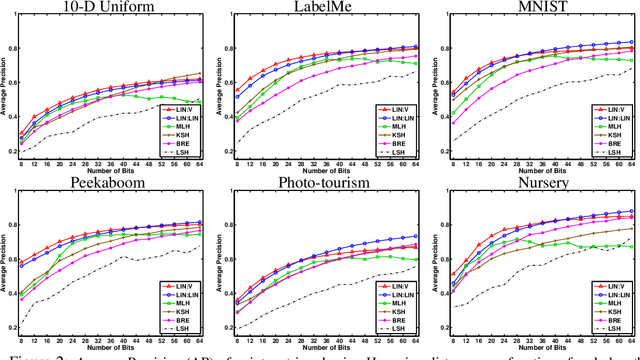
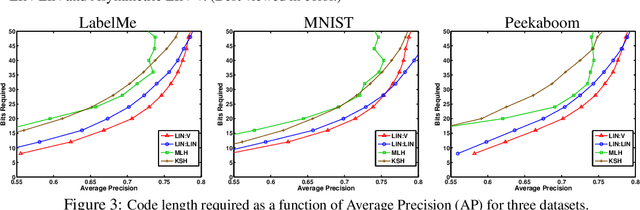
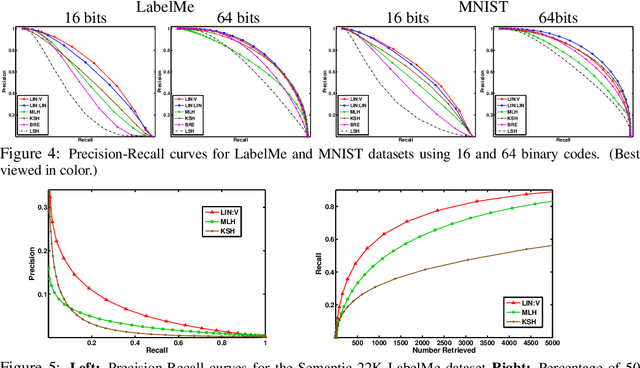
When approximating binary similarity using the hamming distance between short binary hashes, we show that even if the similarity is symmetric, we can have shorter and more accurate hashes by using two distinct code maps. I.e. by approximating the similarity between $x$ and $x'$ as the hamming distance between $f(x)$ and $g(x')$, for two distinct binary codes $f,g$, rather than as the hamming distance between $f(x)$ and $f(x')$.