 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Approach for Online Decision Mining and Decision Drift Analysis in Process-Aware Information Systems: Extended Version
Mar 07, 2023Decision mining enables the discovery of decision rules from event logs or streams, and constitutes an important part of in-depth analysis and optimisation of business processes. So far, decision mining has been merely applied in an ex-post way resulting in a snapshot of decision rules for the given chunk of log data. Online decision mining, by contrast, enables continuous monitoring of decision rule evolution and decision drift. Hence this paper presents an end-to-end approach for the discovery as well as monitoring of decision points and the corresponding decision rules during runtime, bridging the gap between online control flow discovery and decision mining. The approach provides automatic decision support for process-aware information systems with efficient decision drift discovery and monitoring. For monitoring, not only the performance, in terms of accuracy, of decision rules is taken into account, but also the occurrence of data elements and changes in branching frequency. The paper provides two algorithms, which are evaluated on four synthetic and one real-life data set, showing feasibility and applicability of the approach. Overall, the approach fosters the understanding of decisions in business processes and hence contributes to an improved human-process interaction.
Comparing decision mining approaches with regard to the meaningfulness of their results
Sep 15, 2021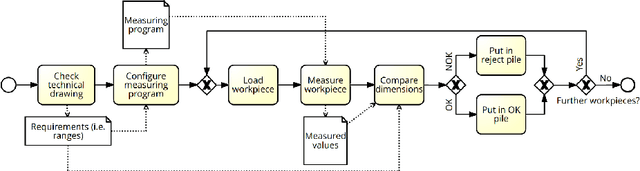
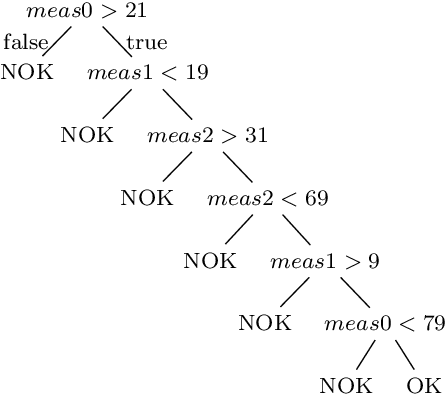
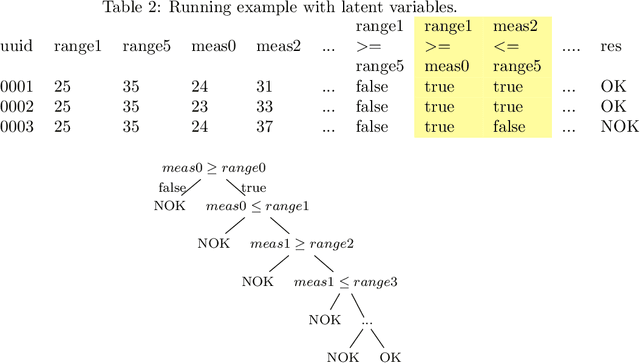
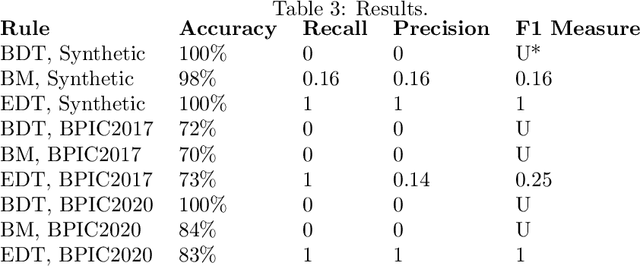
Decisions and the underlying rules are indispensable for driving process execution during runtime, i.e., for routing process instances at alternative branches based on the values of process data. Decision rules can comprise unary data conditions, e.g., age > 40, binary data conditions where the relation between two or more variables is relevant, e.g. temperature1 < temperature2, and more complex conditions that refer to, for example, parts of a medical image. Decision discovery aims at automatically deriving decision rules from process event logs. Existing approaches focus on the discovery of unary, or in some instances binary data conditions. The discovered decision rules are usually evaluated using accuracy, but not with regards to their semantics and meaningfulness, although this is crucial for validation and the subsequent implementation/adaptation of the decision rules. Hence, this paper compares three decision mining approaches, i.e., two existing ones and one newly described approach, with respect to the meaningfulness of their results. For comparison, we use one synthetic data set for a realistic manufacturing case and the two real-world BPIC 2017/2020 logs. The discovered rules are discussed with regards to their semantics and meaningfulness.