 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Infection Spread Model Based Group Testing
Jan 21, 2022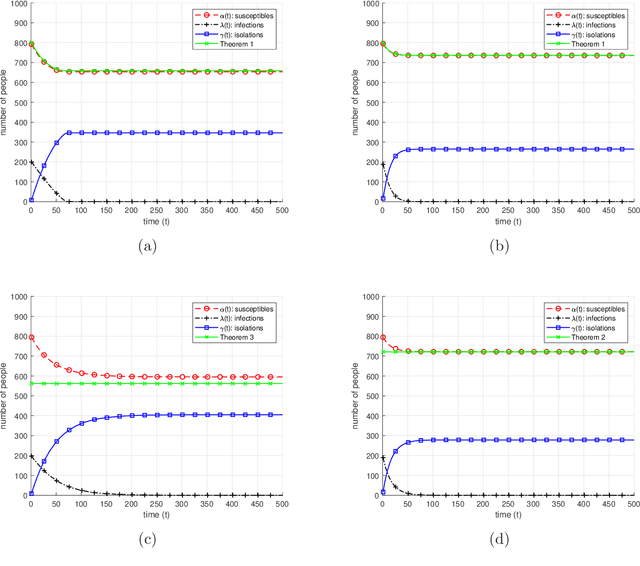
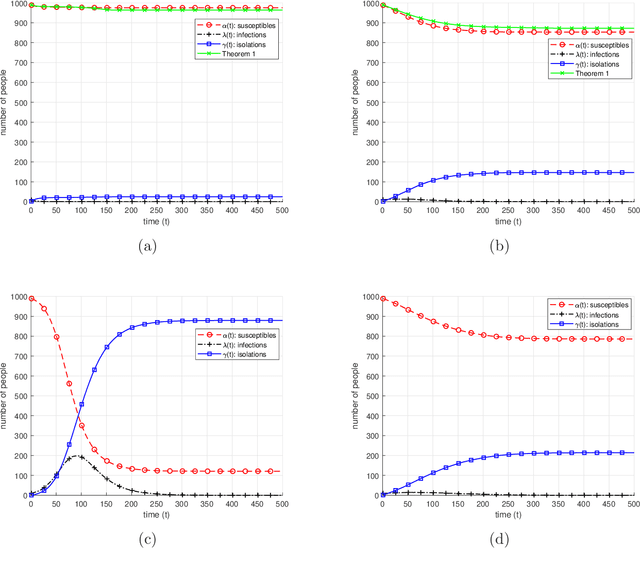
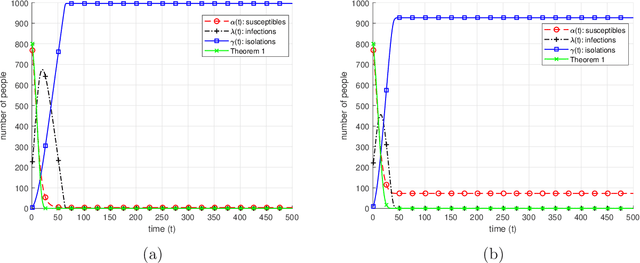
We study a dynamic infection spread model, inspired by the discrete time SIR model, where infections are spread via non-isolated infected individuals. While infection keeps spreading over time, a limited capacity testing is performed at each time instance as well. In contrast to the classical, static, group testing problem, the objective in our setup is not to find the minimum number of required tests to identify the infection status of every individual in the population, but to control the infection spread by detecting and isolating the infections over time by using the given, limited number of tests. In order to analyze the performance of the proposed algorithms, we focus on the mean-sense analysis of the number of individuals that remain non-infected throughout the process of controlling the infection. We propose two dynamic algorithms that both use given limited number of tests to identify and isolate the infections over time, while the infection spreads. While the first algorithm is a dynamic randomized individual testing algorithm, in the second algorithm we employ the group testing approach similar to the original work of Dorfman. By considering weak versions of our algorithms, we obtain lower bounds for the performance of our algorithms. Finally, we implement our algorithms and run simulations to gather numerical results and compare our algorithms and theoretical approximation results under different sets of system parameters.
Group Testing with a Graph Infection Spread Model
Jan 14, 2021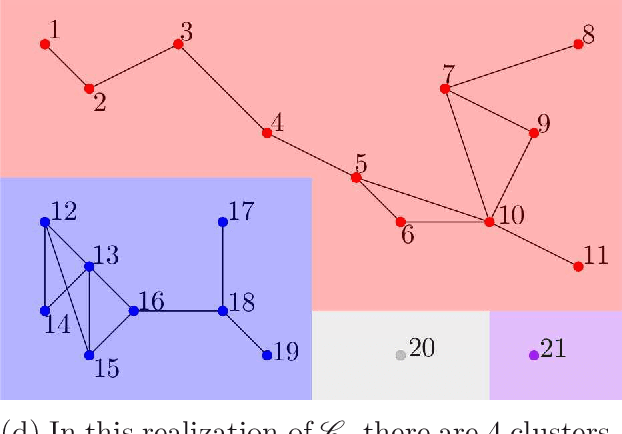
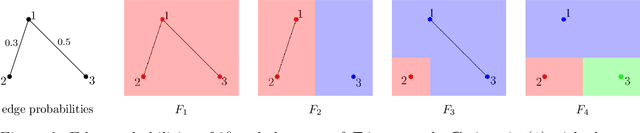
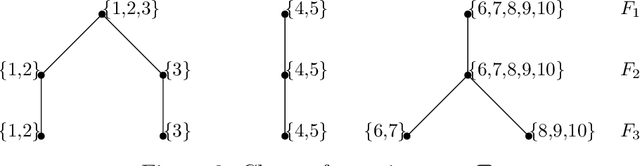
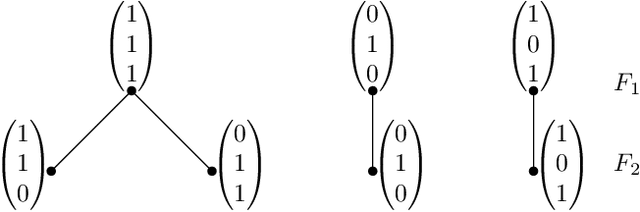
We propose a novel infection spread model based on a random connection graph which represents connections between $n$ individuals. Infection spreads via connections between individuals and this results in a probabilistic cluster formation structure as well as a non-i.i.d. (correlated) infection status for individuals. We propose a class of two-step sampled group testing algorithms where we exploit the known probabilistic infection spread model. We investigate the metrics associated with two-step sampled group testing algorithms. To demonstrate our results, for analytically tractable exponentially split cluster formation trees, we calculate the required number of tests and the expected number of false classifications in terms of the system parameters, and identify the trade-off between them. For such exponentially split cluster formation trees, for zero-error construction, we prove that the required number of tests is $O(\log_2n)$. Thus, for such cluster formation trees, our algorithm outperforms any zero-error non-adaptive group test, binary splitting algorithm, and Hwang's generalized binary splitting algorithm. Our results imply that, by exploiting probabilistic information on the connections of individuals, group testing can be used to reduce the number of required tests significantly even when infection rate is high, contrasting the prevalent belief that group testing is useful only when infection rate is low.