 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Argumentation-based Reasoning Tasks for Benchmarking Generative Language Models
May 02, 2025Generative large language models as tools in the legal domain have the potential to improve the justice system. However, the reasoning behavior of current generative models is brittle and poorly understood, hence cannot be responsibly applied in the domains of law and evidence. In this paper, we introduce an approach for creating benchmarks that can be used to evaluate the reasoning capabilities of generative language models. These benchmarks are dynamically varied, scalable in their complexity, and have formally unambiguous interpretations. In this study, we illustrate the approach on the basis of witness testimony, focusing on the underlying argument attack structure. We dynamically generate both linear and non-linear argument attack graphs of varying complexity and translate these into reasoning puzzles about witness testimony expressed in natural language. We show that state-of-the-art large language models often fail in these reasoning puzzles, already at low complexity. Obvious mistakes are made by the models, and their inconsistent performance indicates that their reasoning capabilities are brittle. Furthermore, at higher complexity, even state-of-the-art models specifically presented for reasoning capabilities make mistakes. We show the viability of using a parametrized benchmark with varying complexity to evaluate the reasoning capabilities of generative language models. As such, the findings contribute to a better understanding of the limitations of the reasoning capabilities of generative models, which is essential when designing responsible AI systems in the legal domain.
Discovering the Rationale of Decisions: Experiments on Aligning Learning and Reasoning
May 14, 2021



In AI and law, systems that are designed for decision support should be explainable when pursuing justice. In order for these systems to be fair and responsible, they should make correct decisions and make them using a sound and transparent rationale. In this paper, we introduce a knowledge-driven method for model-agnostic rationale evaluation using dedicated test cases, similar to unit-testing in professional software development. We apply this new method in a set of machine learning experiments aimed at extracting known knowledge structures from artificial datasets from fictional and non-fictional legal settings. We show that our method allows us to analyze the rationale of black-box machine learning systems by assessing which rationale elements are learned or not. Furthermore, we show that the rationale can be adjusted using tailor-made training data based on the results of the rationale evaluation.
Strong Admissibility for Abstract Dialectical Frameworks
Dec 10, 2020
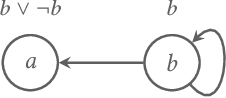
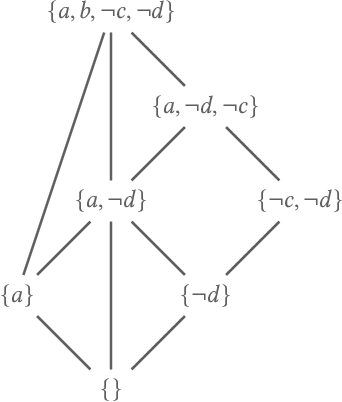
Abstract dialectical frameworks (ADFs) have been introduced as a formalism for modeling and evaluating argumentation allowing general logical satisfaction conditions. Different criteria used to settle the acceptance of arguments are called semantics. Semantics of ADFs have so far mainly been defined based on the concept of admissibility. However, the notion of strongly admissible semantics studied for abstract argumentation frameworks has not yet been introduced for ADFs. In the current work we present the concept of strong admissibility of interpretations for ADFs. Further, we show that strongly admissible interpretations of ADFs form a lattice with the grounded interpretation as top element.
On the existence and multiplicity of extensions in dialectical argumentation
Jul 17, 2002In the present paper, the existence and multiplicity problems of extensions are addressed. The focus is on extension of the stable type. The main result of the paper is an elegant characterization of the existence and multiplicity of extensions in terms of the notion of dialectical justification, a close cousin of the notion of admissibility. The characterization is given in the context of the particular logic for dialectical argumentation DEFLOG. The results are of direct relevance for several well-established models of defeasible reasoning (like default logic, logic programming and argumentation frameworks), since elsewhere dialectical argumentation has been shown to have close formal connections with these models.
* 10 pages; 9th International Workshop on Non-Monotonic Reasoning (NMR'2002)