 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDueling Bandits with Dependent Arms
Jun 15, 2017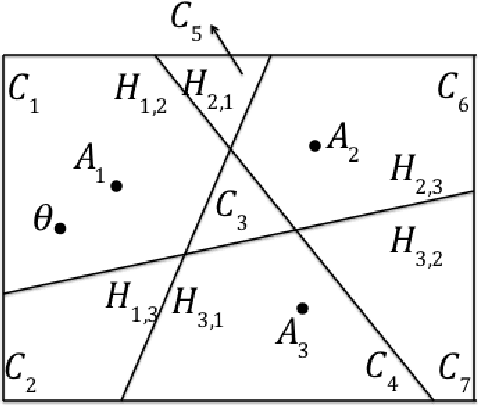
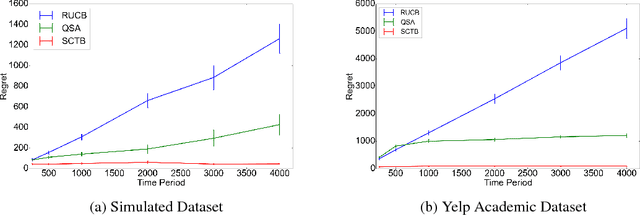
We study dueling bandits with weak utility-based regret when preferences over arms have a total order and carry observable feature vectors. The order is assumed to be determined by these feature vectors, an unknown preference vector, and a known utility function. This structure introduces dependence between preferences for pairs of arms, and allows learning about the preference over one pair of arms from the preference over another pair of arms. We propose an algorithm for this setting called Comparing The Best (CTB), which we show has constant expected cumulative weak utility-based regret. We provide a Bayesian interpretation for CTB, an implementation appropriate for a small number of arms, and an alternate implementation for many arms that can be used when the input parameters satisfy a decomposability condition. We demonstrate through numerical experiments that CTB with appropriate input parameters outperforms all benchmarks considered.
Dueling Bandits With Weak Regret
Jun 14, 2017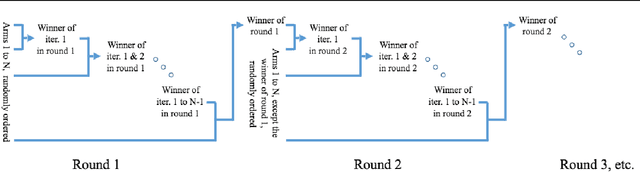
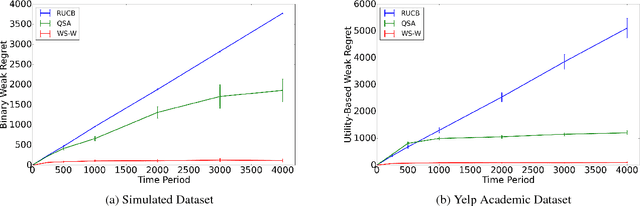
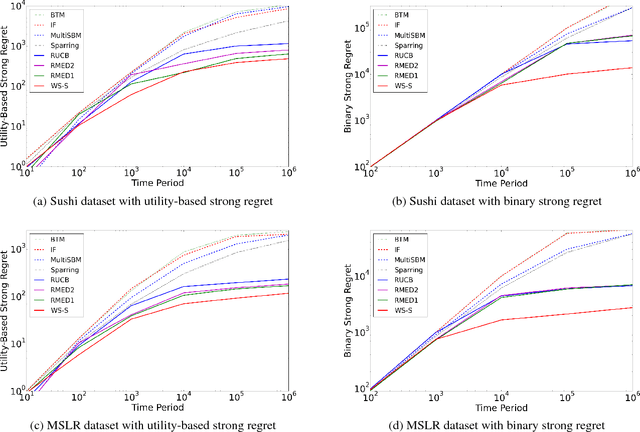
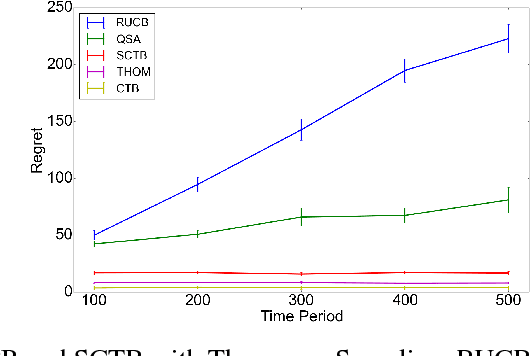
We consider online content recommendation with implicit feedback through pairwise comparisons, formalized as the so-called dueling bandit problem. We study the dueling bandit problem in the Condorcet winner setting, and consider two notions of regret: the more well-studied strong regret, which is 0 only when both arms pulled are the Condorcet winner; and the less well-studied weak regret, which is 0 if either arm pulled is the Condorcet winner. We propose a new algorithm for this problem, Winner Stays (WS), with variations for each kind of regret: WS for weak regret (WS-W) has expected cumulative weak regret that is $O(N^2)$, and $O(N\log(N))$ if arms have a total order; WS for strong regret (WS-S) has expected cumulative strong regret of $O(N^2 + N \log(T))$, and $O(N\log(N)+N\log(T))$ if arms have a total order. WS-W is the first dueling bandit algorithm with weak regret that is constant in time. WS is simple to compute, even for problems with many arms, and we demonstrate through numerical experiments on simulated and real data that WS has significantly smaller regret than existing algorithms in both the weak- and strong-regret settings.
The Bayesian Linear Information Filtering Problem
Oct 22, 2016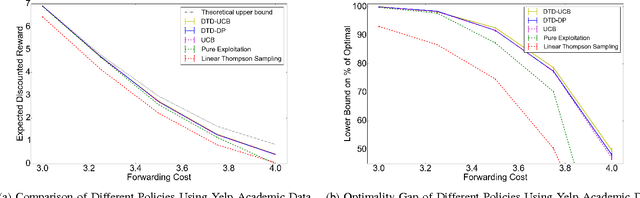
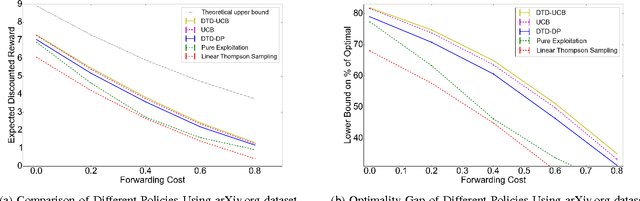
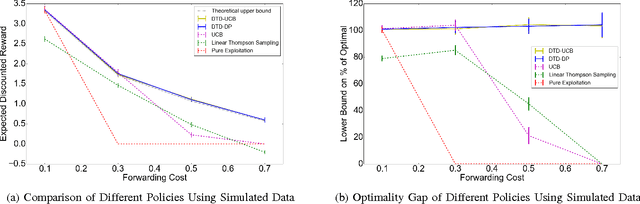
We present a Bayesian sequential decision-making formulation of the information filtering problem, in which an algorithm presents items (news articles, scientific papers, tweets) arriving in a stream, and learns relevance from user feedback on presented items. We model user preferences using a Bayesian linear model, similar in spirit to a Bayesian linear bandit. We compute a computational upper bound on the value of the optimal policy, which allows computing an optimality gap for implementable policies. We then use this analysis as motivation in introducing a pair of new Decompose-Then-Decide (DTD) heuristic policies, DTD-Dynamic-Programming (DTD-DP) and DTD-Upper-Confidence-Bound (DTD-UCB). We compare DTD-DP and DTD-UCB against several benchmarks on real and simulated data, demonstrating significant improvement, and show that the achieved performance is close to the upper bound.