 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Nets for Multiple Text Corpora
Dec 25, 2017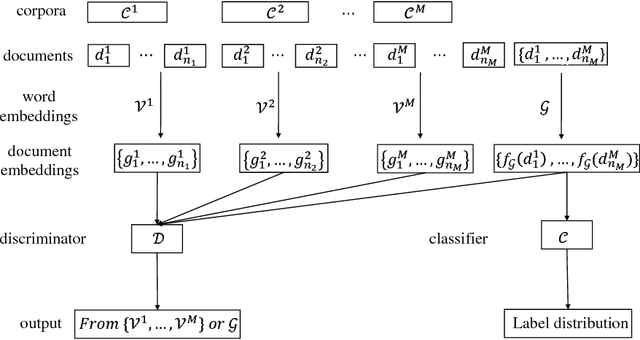
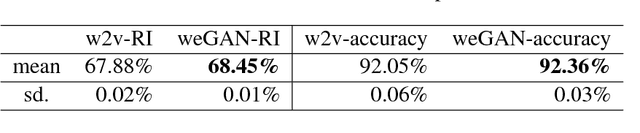
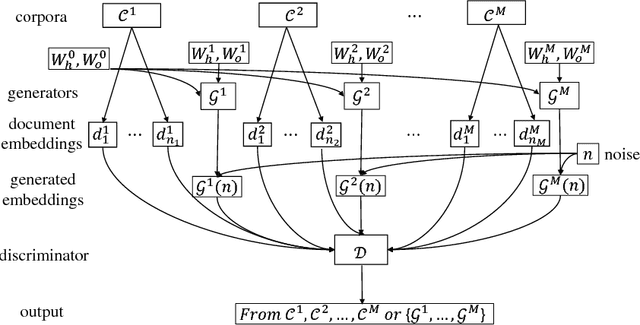
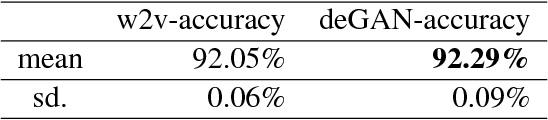
Generative adversarial nets (GANs) have been successfully applied to the artificial generation of image data. In terms of text data, much has been done on the artificial generation of natural language from a single corpus. We consider multiple text corpora as the input data, for which there can be two applications of GANs: (1) the creation of consistent cross-corpus word embeddings given different word embeddings per corpus; (2) the generation of robust bag-of-words document embeddings for each corpora. We demonstrate our GAN models on real-world text data sets from different corpora, and show that embeddings from both models lead to improvements in supervised learning problems.
An Attention-Based Deep Net for Learning to Rank
Dec 10, 2017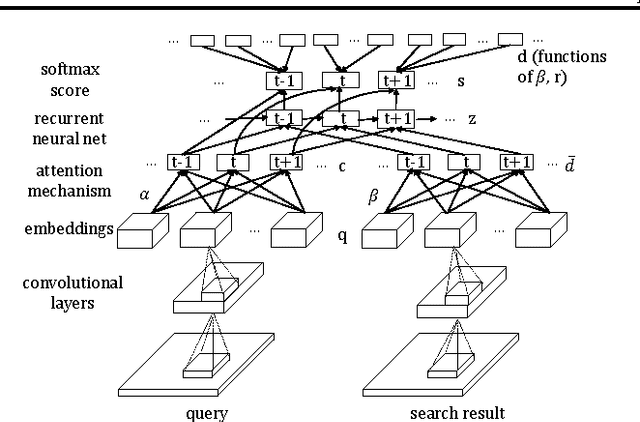
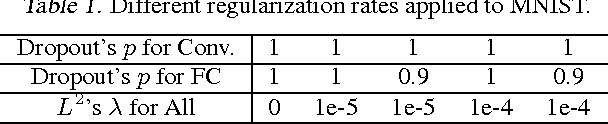
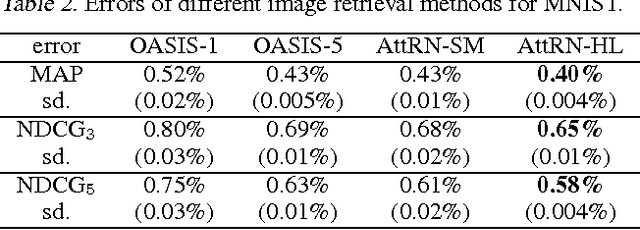
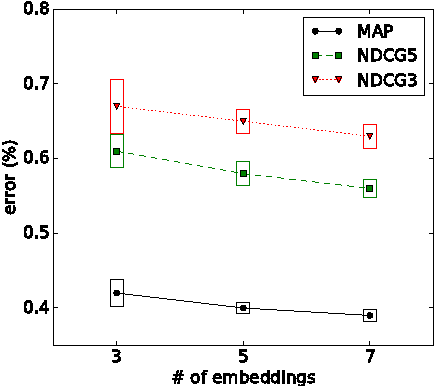
In information retrieval, learning to rank constructs a machine-based ranking model which given a query, sorts the search results by their degree of relevance or importance to the query. Neural networks have been successfully applied to this problem, and in this paper, we propose an attention-based deep neural network which better incorporates different embeddings of the queries and search results with an attention-based mechanism. This model also applies a decoder mechanism to learn the ranks of the search results in a listwise fashion. The embeddings are trained with convolutional neural networks or the word2vec model. We demonstrate the performance of this model with image retrieval and text querying data sets.
Regularization for Unsupervised Deep Neural Nets
Feb 17, 2017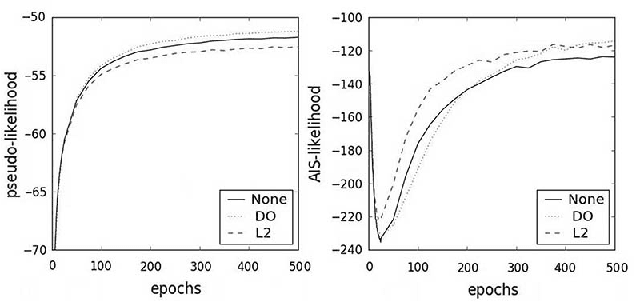
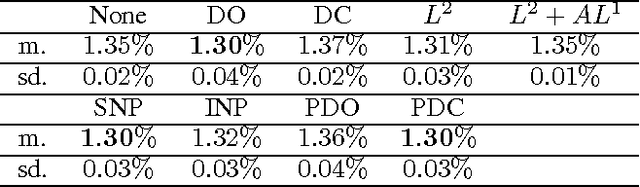
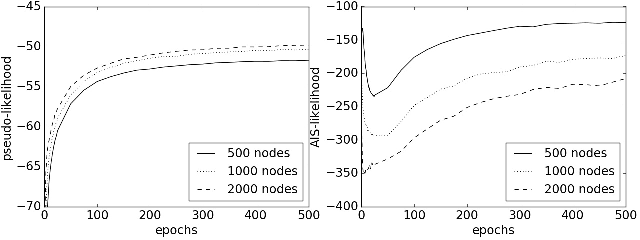
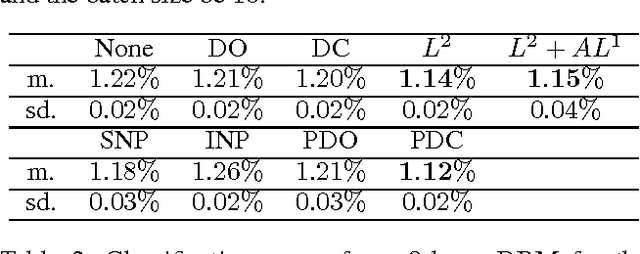
Unsupervised neural networks, such as restricted Boltzmann machines (RBMs) and deep belief networks (DBNs), are powerful tools for feature selection and pattern recognition tasks. We demonstrate that overfitting occurs in such models just as in deep feedforward neural networks, and discuss possible regularization methods to reduce overfitting. We also propose a "partial" approach to improve the efficiency of Dropout/DropConnect in this scenario, and discuss the theoretical justification of these methods from model convergence and likelihood bounds. Finally, we compare the performance of these methods based on their likelihood and classification error rates for various pattern recognition data sets.
Temporal Topic Analysis with Endogenous and Exogenous Processes
Jul 04, 2016
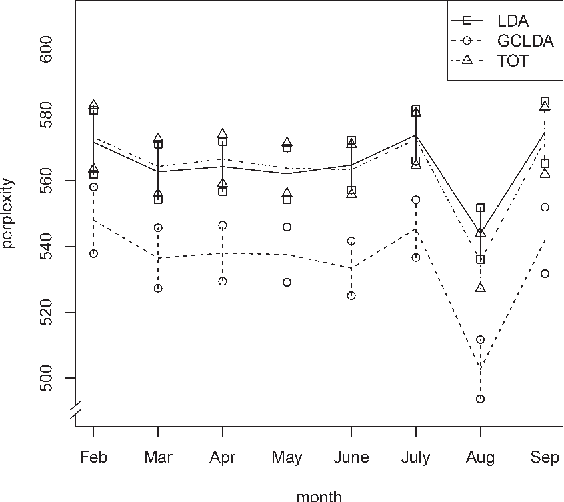


We consider the problem of modeling temporal textual data taking endogenous and exogenous processes into account. Such text documents arise in real world applications, including job advertisements and economic news articles, which are influenced by the fluctuations of the general economy. We propose a hierarchical Bayesian topic model which imposes a "group-correlated" hierarchical structure on the evolution of topics over time incorporating both processes, and show that this model can be estimated from Markov chain Monte Carlo sampling methods. We further demonstrate that this model captures the intrinsic relationships between the topic distribution and the time-dependent factors, and compare its performance with latent Dirichlet allocation (LDA) and two other related models. The model is applied to two collections of documents to illustrate its empirical performance: online job advertisements from DirectEmployers Association and journalists' postings on BusinessInsider.com.