 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Estimation of Long Memory Stochastic Processes with Deep Neural Networks
Oct 03, 2024



We present a purely deep neural network-based approach for estimating long memory parameters of time series models that incorporate the phenomenon of long-range dependence. Parameters, such as the Hurst exponent, are critical in characterizing the long-range dependence, roughness, and self-similarity of stochastic processes. The accurate and fast estimation of these parameters holds significant importance across various scientific disciplines, including finance, physics, and engineering. We harnessed efficient process generators to provide high-quality synthetic training data, enabling the training of scale-invariant 1D Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) models. Our neural models outperform conventional statistical methods, even those augmented with neural networks. The precision, speed, consistency, and robustness of our estimators are demonstrated through experiments involving fractional Brownian motion (fBm), the Autoregressive Fractionally Integrated Moving Average (ARFIMA) process, and the fractional Ornstein-Uhlenbeck (fOU) process. We believe that our work will inspire further research in the field of stochastic process modeling and parameter estimation using deep learning techniques.
LlamBERT: Large-scale low-cost data annotation in NLP
Mar 23, 2024Large Language Models (LLMs), such as GPT-4 and Llama 2, show remarkable proficiency in a wide range of natural language processing (NLP) tasks. Despite their effectiveness, the high costs associated with their use pose a challenge. We present LlamBERT, a hybrid approach that leverages LLMs to annotate a small subset of large, unlabeled databases and uses the results for fine-tuning transformer encoders like BERT and RoBERTa. This strategy is evaluated on two diverse datasets: the IMDb review dataset and the UMLS Meta-Thesaurus. Our results indicate that the LlamBERT approach slightly compromises on accuracy while offering much greater cost-effectiveness.
Deep learning the Hurst parameter of linear fractional processes and assessing its reliability
Jan 03, 2024This research explores the reliability of deep learning, specifically Long Short-Term Memory (LSTM) networks, for estimating the Hurst parameter in fractional stochastic processes. The study focuses on three types of processes: fractional Brownian motion (fBm), fractional Ornstein-Uhlenbeck (fOU) process, and linear fractional stable motions (lfsm). The work involves a fast generation of extensive datasets for fBm and fOU to train the LSTM network on a large volume of data in a feasible time. The study analyses the accuracy of the LSTM network's Hurst parameter estimation regarding various performance measures like RMSE, MAE, MRE, and quantiles of the absolute and relative errors. It finds that LSTM outperforms the traditional statistical methods in the case of fBm and fOU processes; however, it has limited accuracy on lfsm processes. The research also delves into the implications of training length and valuation sequence length on the LSTM's performance. The methodology is applied by estimating the Hurst parameter in Li-ion battery degradation data and obtaining confidence bounds for the estimation. The study concludes that while deep learning methods show promise in parameter estimation of fractional processes, their effectiveness is contingent on the process type and the quality of training data.
Dilated Convolutional Neural Networks for Lightweight Diacritics Restoration
Jan 18, 2022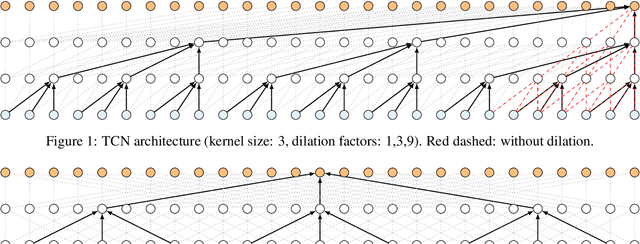
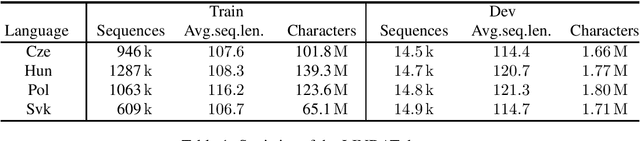

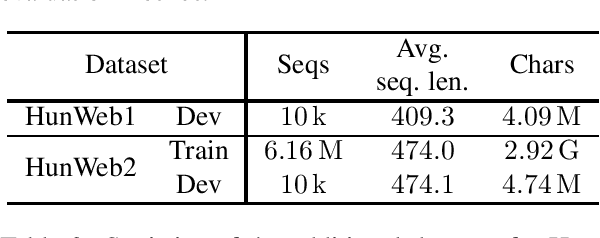
Diacritics restoration has become a ubiquitous task in the Latin-alphabet-based English-dominated Internet language environment. In this paper, we describe a small footprint 1D dilated convolution-based approach which operates on a character-level. We find that solutions based on 1D dilated convolutional neural networks are competitive alternatives to models based on recursive neural networks or linguistic modeling for the task of diacritics restoration. Our solution surpasses the performance of similarly sized models and is also competitive with larger models. A special feature of our solution is that it even runs locally in a web browser. We also provide a working example of this browser-based implementation. Our model is evaluated on different corpora, with emphasis on the Hungarian language. We performed comparative measurements about the generalization power of the model in relation to three Hungarian corpora. We also analyzed the errors to understand the limitation of corpus-based self-supervised training.