 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic clothing: hybrid recommendation, from street-style-to-shop
Nov 12, 2017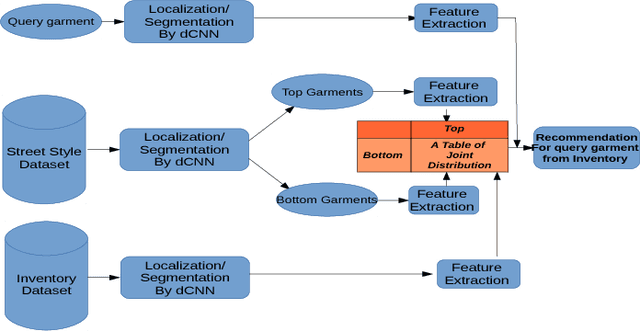
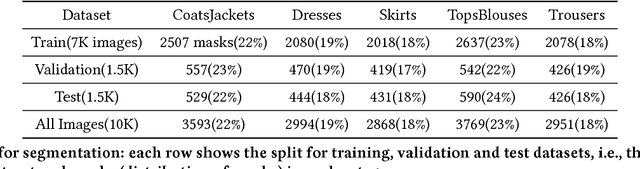
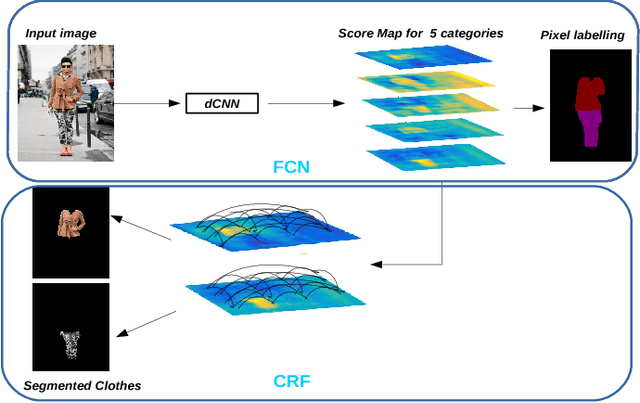
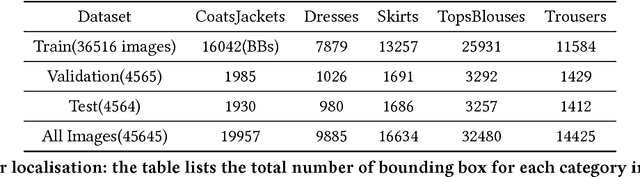
In this paper we detail Cortexica's (https://www.cortexica.com) recommendation framework -- particularly, we describe how a hybrid visual recommender system can be created by combining conditional random fields for segmentation and deep neural networks for object localisation and feature representation. The recommendation system that is built after localisation, segmentation and classification has two properties -- first, it is knowledge based in the sense that it learns pairwise preference/occurrence matrix by utilising knowledge from experts (images from fashion blogs) and second, it is content-based as it utilises a deep learning based framework for learning feature representation. Such a construct is especially useful when there is a scarcity of user preference data, that forms the foundation of many collaborative recommendation algorithms.
Deep Tensor Encoding
Nov 12, 2017
Learning an encoding of feature vectors in terms of an over-complete dictionary or a information geometric (Fisher vectors) construct is wide-spread in statistical signal processing and computer vision. In content based information retrieval using deep-learning classifiers, such encodings are learnt on the flattened last layer, without adherence to the multi-linear structure of the underlying feature tensor. We illustrate a variety of feature encodings incl. sparse dictionary coding and Fisher vectors along with proposing that a structured tensor factorization scheme enables us to perform retrieval that can be at par, in terms of average precision, with Fisher vector encoded image signatures. In short, we illustrate how structural constraints increase retrieval fidelity.
Differential Geometric Retrieval of Deep Features
Nov 12, 2017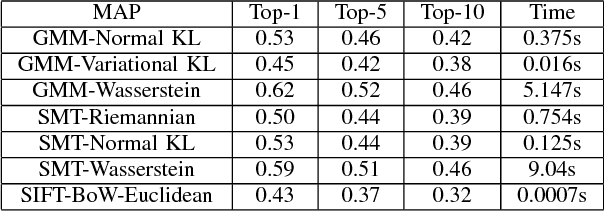
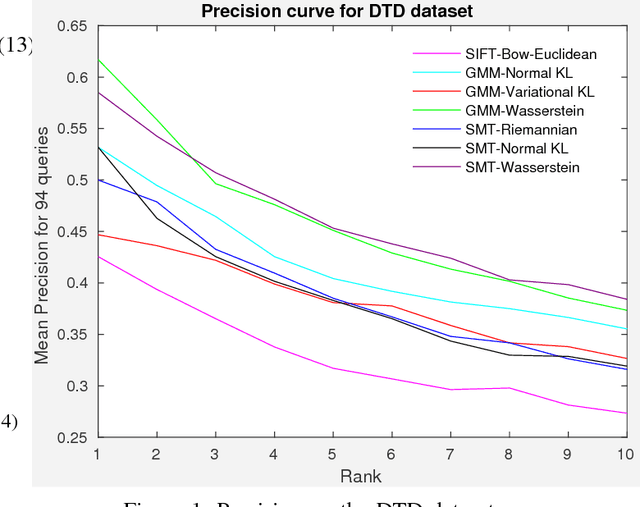

Comparing images to recommend items from an image-inventory is a subject of continued interest. Added with the scalability of deep-learning architectures the once `manual' job of hand-crafting features have been largely alleviated, and images can be compared according to features generated from a deep convolutional neural network. In this paper, we compare distance metrics (and divergences) to rank features generated from a neural network, for content-based image retrieval. Specifically, after modelling individual images using approximations of mixture models or sparse covariance estimators, we resort to their information-theoretic and Riemann geometric comparisons. We show that using approximations of mixture models enable us to compute a distance measure based on the Wasserstein metric that requires less effort than other computationally intensive optimal transport plans; finally, an affine invariant metric is used to compare the optimal transport metric to its Riemann geometric counterpart -- we conclude that although expensive, retrieval metric based on Wasserstein geometry is more suitable than information theoretic comparison of images. In short, we combine GPU scalability in learning deep feature vectors with statistically efficient metrics that we foresee being utilised in a commercial setting.
Large-scale image analysis using docker sandboxing
Mar 07, 2017
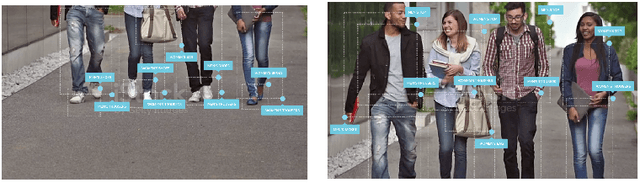


With the advent of specialized hardware such as Graphics Processing Units (GPUs), large scale image localization, classification and retrieval have seen increased prevalence. Designing scalable software architecture that co-evolves with such specialized hardware is a challenge in the commercial setting. In this paper, we describe one such architecture (\textit{Cortexica}) that leverages scalability of GPUs and sandboxing offered by docker containers. This allows for the flexibility of mixing different computer architectures as well as computational algorithms with the security of a trusted environment. We illustrate the utility of this framework in a commercial setting i.e., searching for multiple products in an image by combining image localisation and retrieval.