 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Reviewers Assignment to a Research Paper Based on Allied References and Publications Weight
Jun 26, 2025Everyday, a vast stream of research documents is submitted to conferences, anthologies, journals, newsletters, annual reports, daily papers, and various periodicals. Many such publications use independent external specialists to review submissions. This process is called peer review, and the reviewers are called referees. However, it is not always possible to pick the best referee for reviewing. Moreover, new research fields are emerging in every sector, and the number of research papers is increasing dramatically. To review all these papers, every journal assigns a small team of referees who may not be experts in all areas. For example, a research paper in communication technology should be reviewed by an expert from the same field. Thus, efficiently selecting the best reviewer or referee for a research paper is a big challenge. In this research, we propose and implement program that uses a new strategy to automatically select the best reviewers for a research paper. Every research paper contains references at the end, usually from the same area. First, we collect the references and count authors who have at least one paper in the references. Then, we automatically browse the web to extract research topic keywords. Next, we search for top researchers in the specific topic and count their h-index, i10-index, and citations for the first n authors. Afterward, we rank the top n authors based on a score and automatically browse their homepages to retrieve email addresses. We also check their co-authors and colleagues online and discard them from the list. The remaining top n authors, generally professors, are likely the best referees for reviewing the research paper.
* IEEE Conference Proceedings (5 Pages)
The Influences of Pre-birth Factors in Early Assessment of Child Mortality using Machine Learning Techniques
Nov 18, 2020
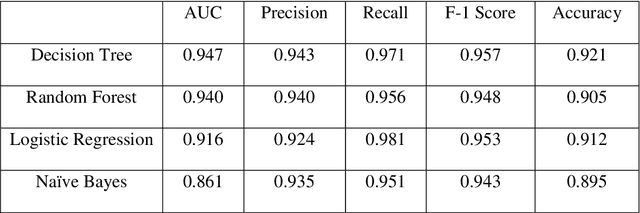
Analysis of child mortality is crucial as it pertains to the policy and programs of a country. The early assessment of patterns and trends in causes of child mortality help decision-makers assess needs, prioritize interventions, and monitor progress. Post-birth factors of the child, such as real-time clinical data, health data of the child, etc. are frequently used in child mortality studies. However, in the early assessment of child mortality, pre-birth factors would be more practical and beneficial than the post-birth factors. This study aims at incorporating pre-birth factors, such as birth history, maternal history, reproduction history, socioeconomic condition, etc. for classifying child mortality. To assess the relative importance of the features, Information Gain (IG) attribute evaluator is employed. For classifying child mortality, four machine learning algorithms are evaluated. Results show that the proposed approach achieved an AUC score of 0.947 in classifying child mortality which outperformed the clinical standards. In terms of accuracy, precision, recall, and f-1 score, the results are also notable and uniform. In developing countries like Bangladesh, the early assessment of child mortality using pre-birth factors would be effective and feasible as it avoids the uncertainty of the post-birth factors.