 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trust in AI-Generated Health Advice (TAIGHA) Scale and Short Version (TAIGHA-S): Development and Validation Study
Dec 16, 2025



Artificial Intelligence tools such as large language models are increasingly used by the public to obtain health information and guidance. In health-related contexts, following or rejecting AI-generated advice can have direct clinical implications. Existing instruments like the Trust in Automated Systems Survey assess trustworthiness of generic technology, and no validated instrument measures users' trust in AI-generated health advice specifically. This study developed and validated the Trust in AI-Generated Health Advice (TAIGHA) scale and its four-item short form (TAIGHA-S) as theory-based instruments measuring trust and distrust, each with cognitive and affective components. The items were developed using a generative AI approach, followed by content validation with 10 domain experts, face validation with 30 lay participants, and psychometric validation with 385 UK participants who received AI-generated advice in a symptom-assessment scenario. After automated item reduction, 28 items were retained and reduced to 10 based on expert ratings. TAIGHA showed excellent content validity (S-CVI/Ave=0.99) and CFA confirmed a two-factor model with excellent fit (CFI=0.98, TLI=0.98, RMSEA=0.07, SRMR=0.03). Internal consistency was high (α=0.95). Convergent validity was supported by correlations with the Trust in Automated Systems Survey (r=0.67/-0.66) and users' reliance on the AI's advice (r=0.37 for trust), while divergent validity was supported by low correlations with reading flow and mental load (all |r|<0.25). TAIGHA-S correlated highly with the full scale (r=0.96) and showed good reliability (α=0.88). TAIGHA and TAIGHA-S are validated instruments for assessing user trust and distrust in AI-generated health advice. Reporting trust and distrust separately permits a more complete evaluation of AI interventions, and the short scale is well-suited for time-constrained settings.
A comparative study of artificial intelligence and human doctors for the purpose of triage and diagnosis
Jun 27, 2018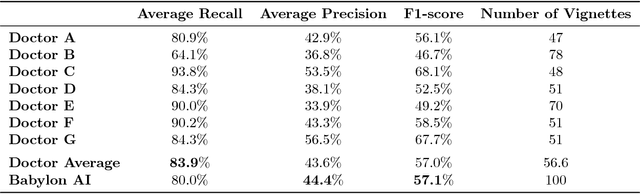
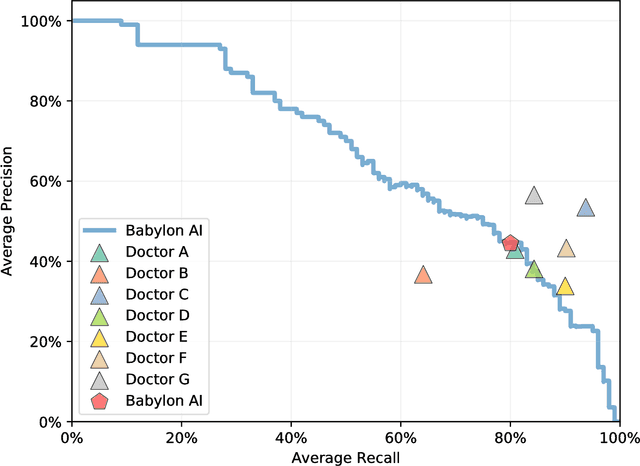
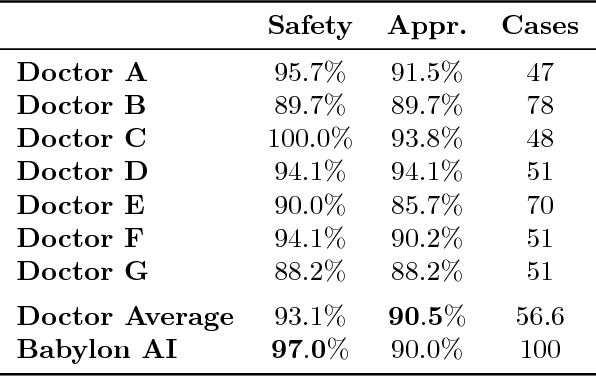
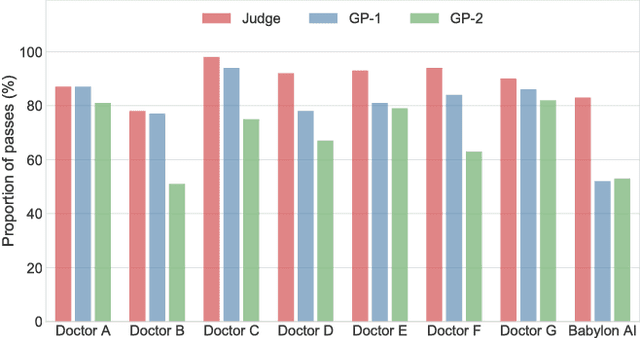
Online symptom checkers have significant potential to improve patient care, however their reliability and accuracy remain variable. We hypothesised that an artificial intelligence (AI) powered triage and diagnostic system would compare favourably with human doctors with respect to triage and diagnostic accuracy. We performed a prospective validation study of the accuracy and safety of an AI powered triage and diagnostic system. Identical cases were evaluated by both an AI system and human doctors. Differential diagnoses and triage outcomes were evaluated by an independent judge, who was blinded from knowing the source (AI system or human doctor) of the outcomes. Independently of these cases, vignettes from publicly available resources were also assessed to provide a benchmark to previous studies and the diagnostic component of the MRCGP exam. Overall we found that the Babylon AI powered Triage and Diagnostic System was able to identify the condition modelled by a clinical vignette with accuracy comparable to human doctors (in terms of precision and recall). In addition, we found that the triage advice recommended by the AI System was, on average, safer than that of human doctors, when compared to the ranges of acceptable triage provided by independent expert judges, with only a minimal reduction in appropriateness.