 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Documents within Multiple Hierarchical Datasets using Multi-Task Learning
Jun 06, 2017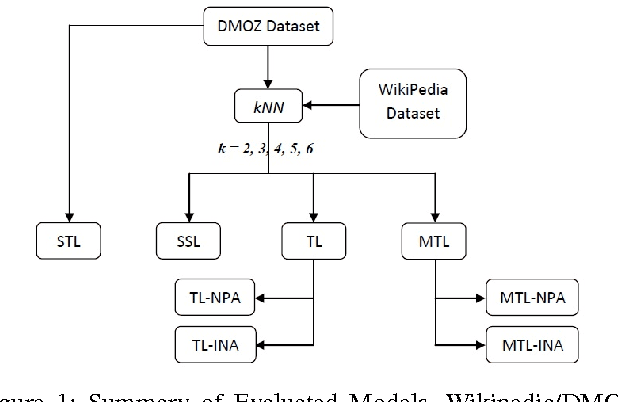
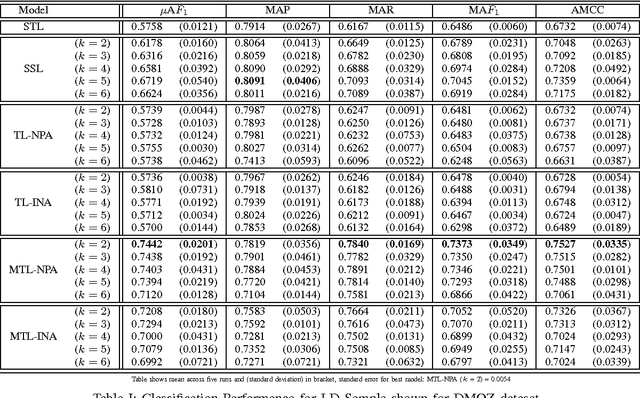
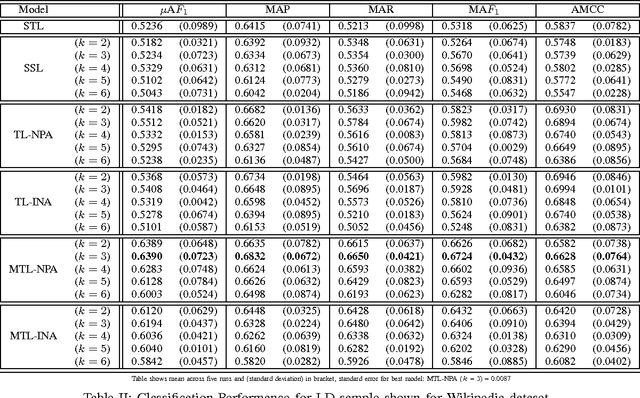
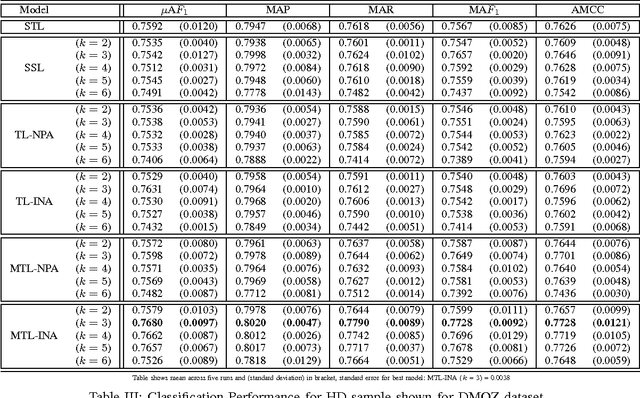
Multi-task learning (MTL) is a supervised learning paradigm in which the prediction models for several related tasks are learned jointly to achieve better generalization performance. When there are only a few training examples per task, MTL considerably outperforms the traditional Single task learning (STL) in terms of prediction accuracy. In this work we develop an MTL based approach for classifying documents that are archived within dual concept hierarchies, namely, DMOZ and Wikipedia. We solve the multi-class classification problem by defining one-versus-rest binary classification tasks for each of the different classes across the two hierarchical datasets. Instead of learning a linear discriminant for each of the different tasks independently, we use a MTL approach with relationships between the different tasks across the datasets established using the non-parametric, lazy, nearest neighbor approach. We also develop and evaluate a transfer learning (TL) approach and compare the MTL (and TL) methods against the standard single task learning and semi-supervised learning approaches. Our empirical results demonstrate the strength of our developed methods that show an improvement especially when there are fewer number of training examples per classification task.
Embedding Feature Selection for Large-scale Hierarchical Classification
Jun 06, 2017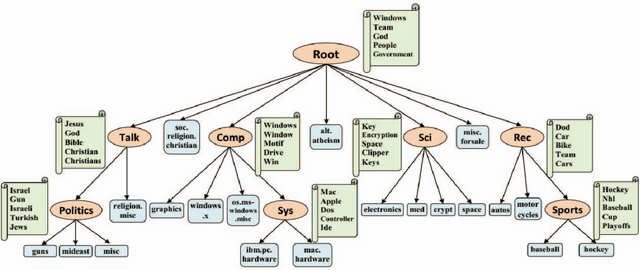
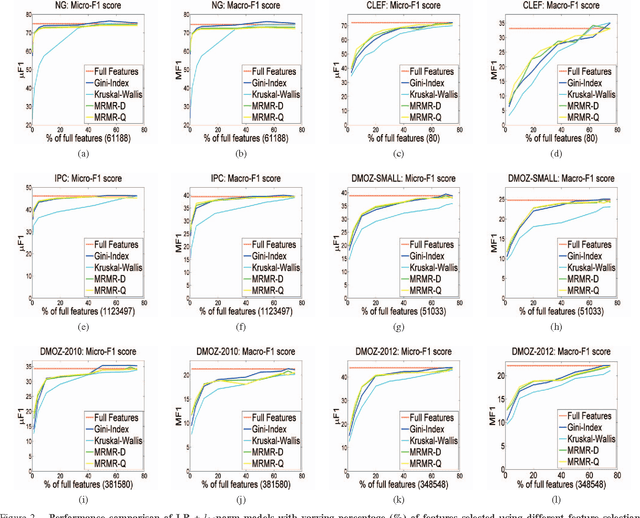
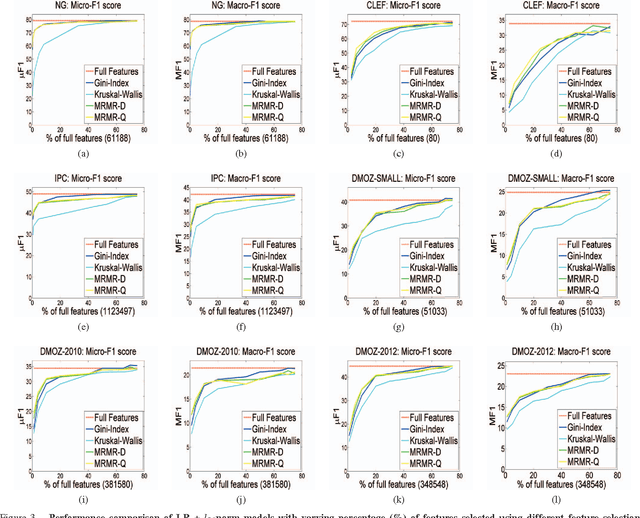
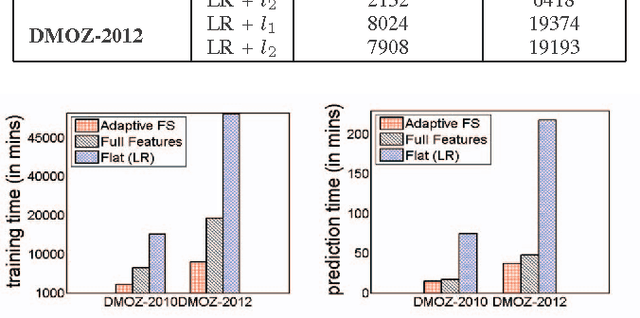
Large-scale Hierarchical Classification (HC) involves datasets consisting of thousands of classes and millions of training instances with high-dimensional features posing several big data challenges. Feature selection that aims to select the subset of discriminant features is an effective strategy to deal with large-scale HC problem. It speeds up the training process, reduces the prediction time and minimizes the memory requirements by compressing the total size of learned model weight vectors. Majority of the studies have also shown feature selection to be competent and successful in improving the classification accuracy by removing irrelevant features. In this work, we investigate various filter-based feature selection methods for dimensionality reduction to solve the large-scale HC problem. Our experimental evaluation on text and image datasets with varying distribution of features, classes and instances shows upto 3x order of speed-up on massive datasets and upto 45% less memory requirements for storing the weight vectors of learned model without any significant loss (improvement for some datasets) in the classification accuracy. Source Code: https://cs.gmu.edu/~mlbio/featureselection.
Inconsistent Node Flattening for Improving Top-down Hierarchical Classification
Jun 05, 2017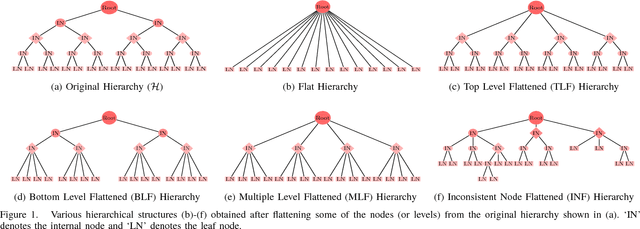
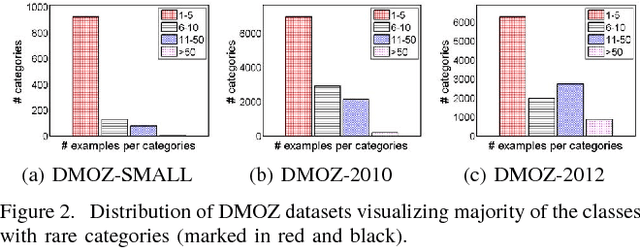
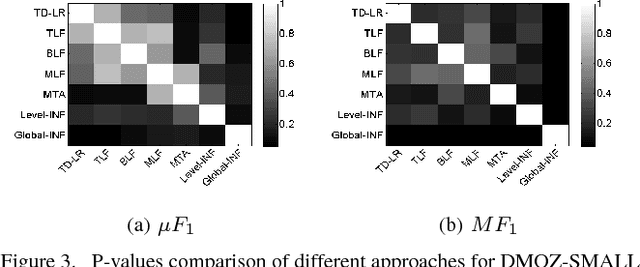
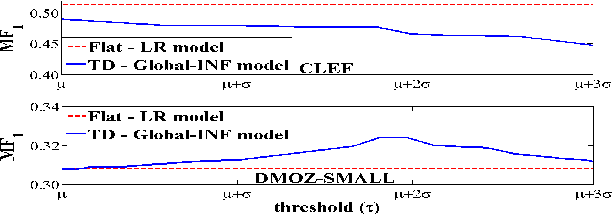
Large-scale classification of data where classes are structurally organized in a hierarchy is an important area of research. Top-down approaches that exploit the hierarchy during the learning and prediction phase are efficient for large scale hierarchical classification. However, accuracy of top-down approaches is poor due to error propagation i.e., prediction errors made at higher levels in the hierarchy cannot be corrected at lower levels. One of the main reason behind errors at the higher levels is the presence of inconsistent nodes that are introduced due to the arbitrary process of creating these hierarchies by domain experts. In this paper, we propose two different data-driven approaches (local and global) for hierarchical structure modification that identifies and flattens inconsistent nodes present within the hierarchy. Our extensive empirical evaluation of the proposed approaches on several image and text datasets with varying distribution of features, classes and training instances per class shows improved classification performance over competing hierarchical modification approaches. Specifically, we see an improvement upto 7% in Macro-F1 score with our approach over best TD baseline. SOURCE CODE: http://www.cs.gmu.edu/~mlbio/InconsistentNodeFlattening
Filter based Taxonomy Modification for Improving Hierarchical Classification
Oct 15, 2016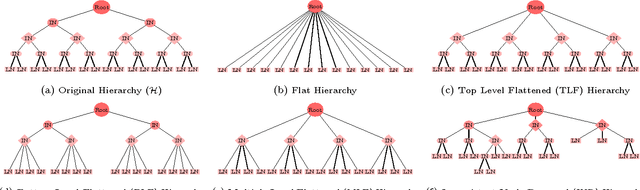
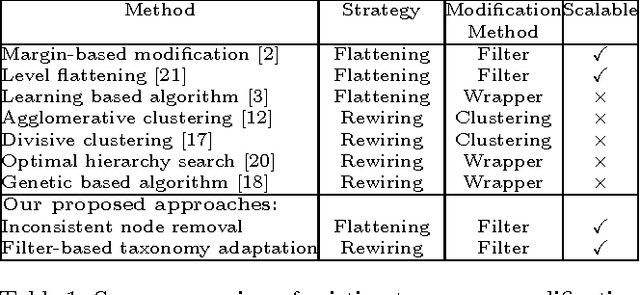


Hierarchical Classification (HC) is a supervised learning problem where unlabeled instances are classified into a taxonomy of classes. Several methods that utilize the hierarchical structure have been developed to improve the HC performance. However, in most cases apriori defined hierarchical structure by domain experts is inconsistent; as a consequence performance improvement is not noticeable in comparison to flat classification methods. We propose a scalable data-driven filter based rewiring approach to modify an expert-defined hierarchy. Experimental comparisons of top-down HC with our modified hierarchy, on a wide range of datasets shows classification performance improvement over the baseline hierarchy (i:e:, defined by expert), clustered hierarchy and flattening based hierarchy modification approaches. In comparison to existing rewiring approaches, our developed method (rewHier) is computationally efficient, enabling it to scale to datasets with large numbers of classes, instances and features. We also show that our modified hierarchy leads to improved classification performance for classes with few training samples in comparison to flat and state-of-the-art HC approaches.