 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATFormer: When Continual Learning Meets Spiking Transformers With Dynamic Thresholds
Mar 16, 2026Although deep neural networks perform extremely well in controlled environments, they fail in real-world scenarios where data isn't available all at once, and the model must adapt to a new data distribution that may or may not follow the initial distribution. Previously acquired knowledge is lost during subsequent updates based on new data. a phenomenon commonly known as catastrophic forgetting. In contrast, the brain can learn without such catastrophic forgetting, irrespective of the number of tasks it encounters. Existing spiking neural networks (SNNs) for class-incremental learning (CIL) suffer a sharp performance drop as tasks accumulate. We here introduce CATFormer (Context Adaptive Threshold Transformer), a scalable framework that overcomes this limitation. We observe that the key to preventing forgetting in SNNs lies not only in synaptic plasticity but also in modulating neuronal excitability. At the core of CATFormer is the Dynamic Threshold Leaky Integrate-and-Fire (DTLIF) neuron model, which leverages context-adaptive thresholds as the primary mechanism for knowledge retention. This is paired with a Gated Dynamic Head Selection (G-DHS) mechanism for task-agnostic inference. Extensive evaluation on both static (CIFAR-10/100/Tiny-ImageNet) and neuromorphic (CIFAR10-DVS/SHD) datasets reveals that CATFormer outperforms existing rehearsal-free CIL algorithms across various task splits, establishing it as an ideal architecture for energy-efficient, true-class incremental learning.
Discriminative Flow Matching Via Local Generative Predictors
Mar 14, 2026Traditional discriminative computer vision relies predominantly on static projections, mapping input features to outputs in a single computational step. Although efficient, this paradigm lacks the iterative refinement and robustness inherent in biological vision and modern generative modelling. In this paper, we propose Discriminative Flow Matching, a framework that reformulates classification and object detection as a conditional transport process. By learning a vector field that continuously transports samples from a simple noise distribution toward a task-aligned target manifold -- such as class embeddings or bounding box coordinates -- we are at the interface between generative and discriminative learning. Our method attaches multiple independent flow predictors to a shared backbone. These predictors are trained using local flow matching objectives, where gradients are computed independently for each block. We formulate this approach for standard image classification and extend it to the complex task of object detection, where targets are high-dimensional and spatially distributed. This architecture provides the flexibility to update blocks either sequentially to minimise activation memory or in parallel to suit different hardware constraints. By aggregating the predictions from these independent flow predictors, our framework enables robust, generative-inspired inference across diverse architectures, including CNNs and vision transformers.
SHaRe-SSM: An Oscillatory Spiking Neural Network for Target Variable Modeling in Long Sequences
Oct 16, 2025In recent years, with the emergence of large models, there has been a significant interest in spiking neural networks (SNNs) primarily due to their energy efficiency, multiplication-free, and sparse event-based deep learning. Similarly, state space models (SSMs) in varying designs have evolved as a powerful alternative to transformers for target modeling in long sequences, thereby overcoming the quadratic dependence on sequence length of a transformer. Inspired by this progress, we here design SHaRe-SSM (Spiking Harmonic Resonate and Fire State Space Model), for target variable modeling (including both classification and regression) for very-long-range sequences. Our second-order spiking SSM, on average, performs better than transformers or first-order SSMs while circumventing multiplication operations, making it ideal for resource-constrained applications. The proposed block consumes $73 \times$ less energy than second-order ANN-based SSMs for an 18k sequence, while retaining performance. To ensure learnability over the long-range sequences, we propose exploiting the stable and efficient implementation of the dynamical system using parallel scans. Moreover, for the first time, we propose a kernel-based spiking regressor using resonate and fire neurons for very long-range sequences. Our network shows superior performance on even a 50k sequence while being significantly energy-efficient. In addition, we conducted a systematic analysis of the impact of heterogeneity, dissipation, and conservation in resonate-and-fire SSMs.
Heterogeneous quantization regularizes spiking neural network activity
Sep 27, 2024



The learning and recognition of object features from unregulated input has been a longstanding challenge for artificial intelligence systems. Brains are adept at learning stable representations given small samples of noisy observations; across sensory modalities, this capacity is aided by a cascade of signal conditioning steps informed by domain knowledge. The olfactory system, in particular, solves a source separation and denoising problem compounded by concentration variability, environmental interference, and unpredictably correlated sensor affinities. To function optimally, its plastic network requires statistically well-behaved input. We present a data-blind neuromorphic signal conditioning strategy whereby analog data are normalized and quantized into spike phase representations. Input is delivered to a column of duplicated spiking principal neurons via heterogeneous synaptic weights; this regularizes layer utilization, yoking total activity to the network's operating range and rendering internal representations robust to uncontrolled open-set stimulus variance. We extend this mechanism by adding a data-aware calibration step whereby the range and density of the quantization weights adapt to accumulated input statistics, optimizing resource utilization by balancing activity regularization and information retention.
Representation Learning Using a Single Forward Pass
Feb 15, 2024



We propose a neuroscience-inspired Solo Pass Embedded Learning Algorithm (SPELA). SPELA is a prime candidate for training and inference applications in Edge AI devices. At the same time, SPELA can optimally cater to the need for a framework to study perceptual representation learning and formation. SPELA has distinctive features such as neural priors (in the form of embedded vectors), no weight transport, no update locking of weights, complete local Hebbian learning, single forward pass with no storage of activations, and single weight update per sample. Juxtaposed with traditional approaches, SPELA operates without the need for backpropagation. We show that our algorithm can perform nonlinear classification on a noisy boolean operation dataset. Additionally, we exhibit high performance using SPELA across MNIST, KMNIST, and Fashion MNIST. Lastly, we show the few-shot and 1-epoch learning capabilities of SPELA on MNIST, KMNIST, and Fashion MNIST, where it consistently outperforms backpropagation.
A Study on Tiny YOLO for Resource Constrained Xray Threat Detection
Sep 27, 2023This paper implements and analyses multiple nets to determine their suitability for edge devices to solve the problem of detecting Threat Objects from X-ray security imaging data. There has been ongoing research on applying Deep Learning techniques to solve this problem automatedly. We utilize an alternative activation function calculated to have zero expected conversion error with the activation of a spiking activation function, in the our tiny YOLOv7 model. This QCFS version of the tiny YOLO replicates the activation of ultra-low latency and high-efficiency SNN architecture and achieves state-of-the-art performance on CLCXray which is another open-source XRay Threat Detection dataset, hence making improvements in the field of using spiking for object detection. We also analyze the performance of a Spiking YOLO network by converting our QCFS network into a Spiking Network.
Sapinet: A sparse event-based spatiotemporal oscillator for learning in the wild
Apr 13, 2022



We introduce Sapinet -- a spike timing (event)-based multilayer neural network for \textit{learning in the wild} -- that is: one-shot online learning of multiple inputs without catastrophic forgetting, and without the need for data-specific hyperparameter retuning. Key features of Sapinet include data regularization, model scaling, data classification, and denoising. The model also supports stimulus similarity mapping. We propose a systematic method to tune the network for performance. We studied the model performance on different levels of odor similarity, gaussian and impulse noise. Sapinet achieved high classification accuracies on standard machine olfaction datasets without the requirement of fine tuning for a specific dataset.
* PhD thesis
Signal Conditioning for Learning in the Wild
Jul 12, 2019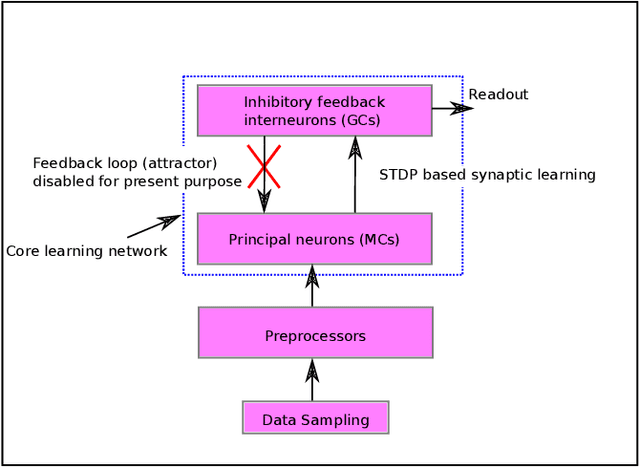
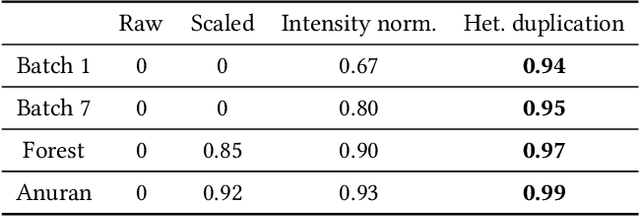
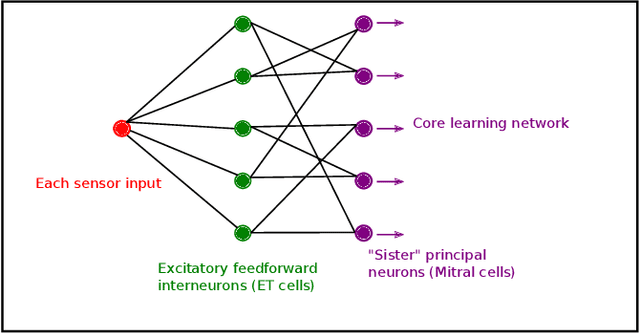
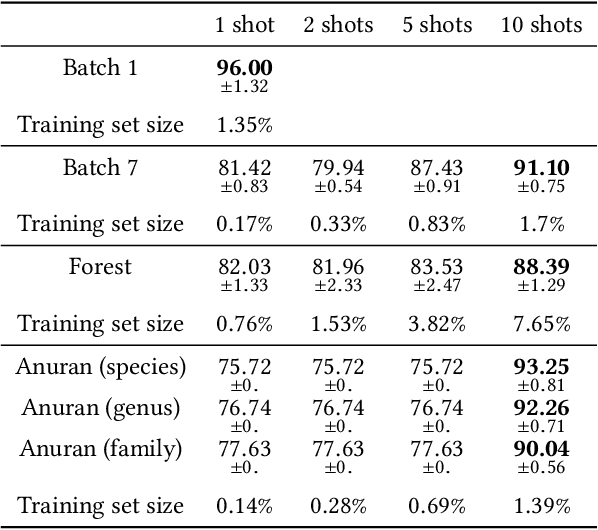
The mammalian olfactory system learns rapidly from very few examples, presented in unpredictable online sequences, and then recognizes these learned odors under conditions of substantial interference without exhibiting catastrophic forgetting. We have developed a brain-mimetic algorithm that replicates these properties, provided that sensory inputs adhere to a common statistical structure. However, in natural, unregulated environments, this constraint cannot be assured. We here present a series of signal conditioning steps, inspired by the mammalian olfactory system, that transform diverse sensory inputs into a regularized statistical structure to which the learning network can be tuned. This pre-processing enables a single instantiated network to be applied to widely diverse classification tasks and datasets - here including gas sensor data, remote sensing from spectral characteristics, and multi-label hierarchical identification of wild species - without adjusting network hyperparameters.