 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-IDS: Multi-Agent RAG Framework for IoT Network Intrusion Detection with an Experience Library
Apr 07, 2026Network Intrusion Detection Systems (NIDS) face important limitations. Signature-based methods are effective for known attack patterns, but they struggle to detect zero-day attacks and often miss modified variants of previously known attacks, while many machine learning approaches offer limited interpretability. These challenges become even more severe in IoT environments because of resource constraints and heterogeneous protocols. To address these issues, we propose MA-IDS, a Multi-Agent Intrusion Detection System that combines Large Language Models (LLMs) with Retrieval Augmented Generation (RAG) for reasoning-driven intrusion detection. The proposed framework grounds LLM reasoning through a persistent, self-building Experience Library. Two specialized agents collaborate through a FAISS-based vector database: a Traffic Classification Agent that retrieves past error rules before each inference, and an Error Analysis Agent that converts misclassifications into human-readable detection rules stored for future retrieval, enabling continual learning through external knowledge accumulation, without modifying the underlying language model. Evaluated on NF-BoT-IoT and NF-ToN-IoT benchmark datasets, MA-IDS achieves Macro F1-Scores of 89.75% and 85.22%, improving over zero-shot baselines of 17% and 4.96% by more than 72 and 80 percentage points. These results are competitive with SVM while providing rule-level explanations for every classification decision, demonstrating that retrieval-augmented reasoning offers a principled path toward explainable, self-improving intrusion detection for IoT networks.
ALIGNAgent: Adaptive Learner Intelligence for Gap Identification and Next-step guidance
Jan 22, 2026Personalized learning systems have emerged as a promising approach to enhance student outcomes by tailoring educational content, pacing, and feedback to individual needs. However, most existing systems remain fragmented, specializing in either knowledge tracing, diagnostic modeling, or resource recommendation, but rarely integrating these components into a cohesive adaptive cycle. In this paper, we propose ALIGNAgent (Adaptive Learner Intelligence for Gap Identification and Next-step guidance), a multi-agent educational framework designed to deliver personalized learning through integrated knowledge estimation, skill-gap identification, and targeted resource recommendation.ALIGNAgent begins by processing student quiz performance, gradebook data, and learner preferences to generate topic-level proficiency estimates using a Skill Gap Agent that employs concept-level diagnostic reasoning to identify specific misconceptions and knowledge deficiencies. After identifying skill gaps, the Recommender Agent retrieves preference-aware learning materials aligned with diagnosed deficiencies, implementing a continuous feedback loop where interventions occur before advancing to subsequent topics. Extensive empirical evaluation on authentic datasets from two undergraduate computer science courses demonstrates ALIGNAgent's effectiveness, with GPT-4o-based agents achieving precision of 0.87-0.90 and F1 scores of 0.84-0.87 in knowledge proficiency estimation validated against actual exam performance.
Effect of Balancing Data Using Synthetic Data on the Performance of Machine Learning Classifiers for Intrusion Detection in Computer Networks
Apr 01, 2022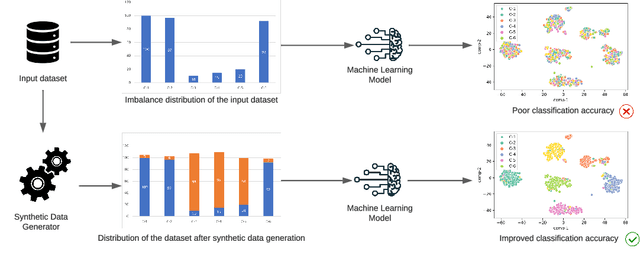
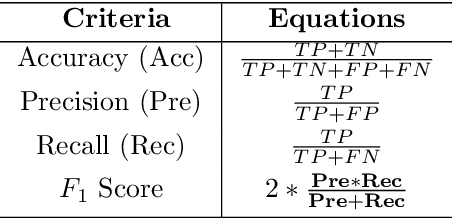
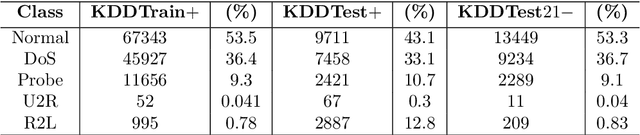
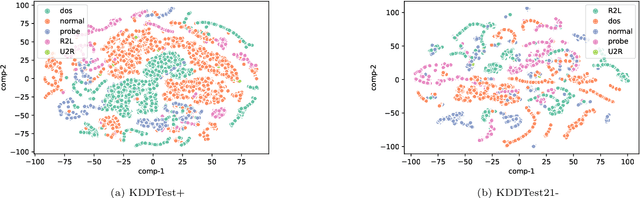
Attacks on computer networks have increased significantly in recent days, due in part to the availability of sophisticated tools for launching such attacks as well as thriving underground cyber-crime economy to support it. Over the past several years, researchers in academia and industry used machine learning (ML) techniques to design and implement Intrusion Detection Systems (IDSes) for computer networks. Many of these researchers used datasets collected by various organizations to train ML models for predicting intrusions. In many of the datasets used in such systems, data are imbalanced (i.e., not all classes have equal amount of samples). With unbalanced data, the predictive models developed using ML algorithms may produce unsatisfactory classifiers which would affect accuracy in predicting intrusions. Traditionally, researchers used over-sampling and under-sampling for balancing data in datasets to overcome this problem. In this work, in addition to over-sampling, we also use a synthetic data generation method, called Conditional Generative Adversarial Network (CTGAN), to balance data and study their effect on various ML classifiers. To the best of our knowledge, no one else has used CTGAN to generate synthetic samples to balance intrusion detection datasets. Based on extensive experiments using a widely used dataset NSL-KDD, we found that training ML models on dataset balanced with synthetic samples generated by CTGAN increased prediction accuracy by up to $8\%$, compared to training the same ML models over unbalanced data. Our experiments also show that the accuracy of some ML models trained over data balanced with random over-sampling decline compared to the same ML models trained over unbalanced data.