 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalence of Privacy and Stability with Generalization Guarantees in Quantum Learning
Feb 01, 2026We present a unified information-theoretic framework to analyze the generalization performance of differentially private (DP) quantum learning algorithms. By leveraging the connection between privacy and algorithmic stability, we establish that $(\varepsilon, δ)$-Quantum Differential Privacy (QDP) imposes a strong constraint on the mutual information between the training data and the algorithm's output. We derive a rigorous, mechanism-agnostic upper bound on this mutual information for learning algorithms satisfying a 1-neighbor privacy constraint. Furthermore, we connect this stability guarantee to generalization, proving that the expected generalization error of any $(\varepsilon, δ)$-QDP learning algorithm is bounded by the square root of the privacy-induced stability term. Finally, we extend our framework to the setting of an untrusted Data Processor, introducing the concept of Information-Theoretic Admissibility (ITA) to characterize the fundamental limits of privacy in scenarios where the learning map itself must remain oblivious to the specific dataset instance.
Generalization Bounds for Quantum Learning via Rényi Divergences
May 16, 2025

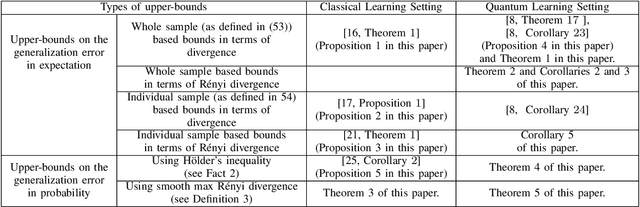
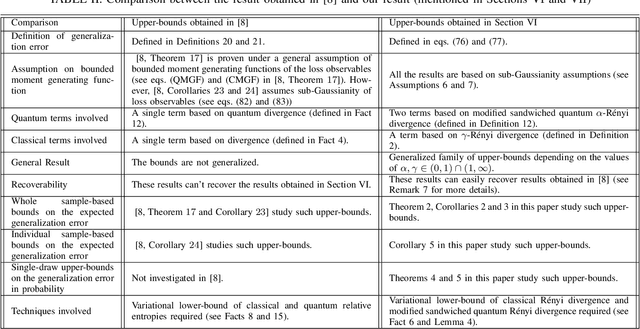
This work advances the theoretical understanding of quantum learning by establishing a new family of upper bounds on the expected generalization error of quantum learning algorithms, leveraging the framework introduced by Caro et al. (2024) and a new definition for the expected true loss. Our primary contribution is the derivation of these bounds in terms of quantum and classical R\'enyi divergences, utilizing a variational approach for evaluating quantum R\'enyi divergences, specifically the Petz and a newly introduced modified sandwich quantum R\'enyi divergence. Analytically and numerically, we demonstrate the superior performance of the bounds derived using the modified sandwich quantum R\'enyi divergence compared to those based on the Petz divergence. Furthermore, we provide probabilistic generalization error bounds using two distinct techniques: one based on the modified sandwich quantum R\'enyi divergence and classical R\'enyi divergence, and another employing smooth max R\'enyi divergence.