 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Impact of Blur on Recognition by Convolutional Networks
May 30, 2017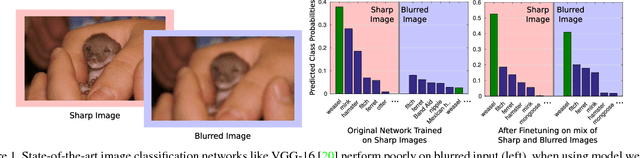
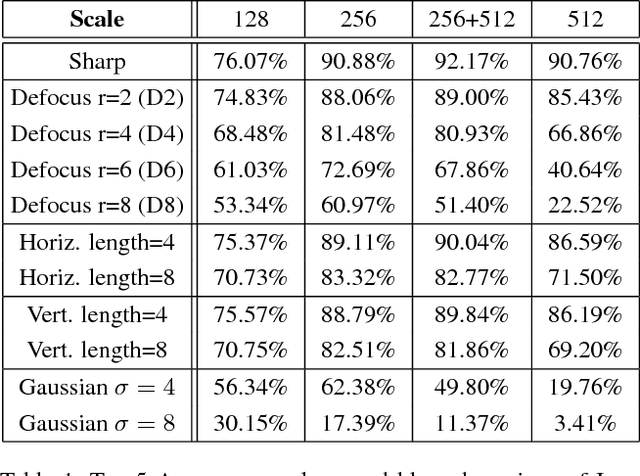
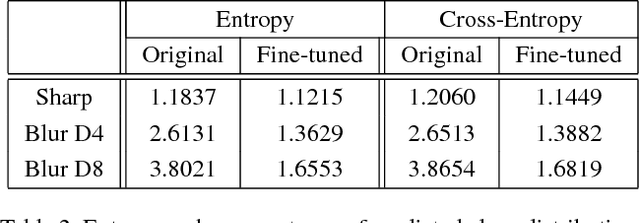
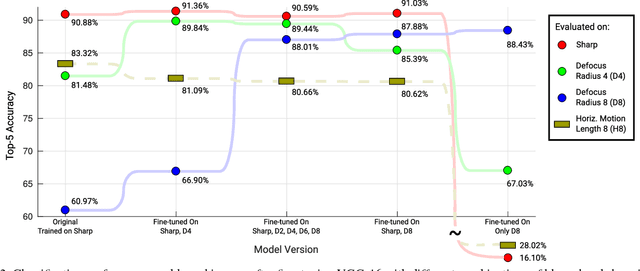
State-of-the-art algorithms for many semantic visual tasks are based on the use of convolutional neural networks. These networks are commonly trained, and evaluated, on large annotated datasets of artifact-free high-quality images. In this paper, we investigate the effect of one such artifact that is quite common in natural capture settings: optical blur. We show that standard network models, trained only on high-quality images, suffer a significant degradation in performance when applied to those degraded by blur due to defocus, or subject or camera motion. We investigate the extent to which this degradation is due to the mismatch between training and input image statistics. Specifically, we find that fine-tuning a pre-trained model with blurred images added to the training set allows it to regain much of the lost accuracy. We also show that there is a fair amount of generalization between different degrees and types of blur, which implies that a single network model can be used robustly for recognition when the nature of the blur in the input is unknown. We find that this robustness arises as a result of these models learning to generate blur invariant representations in their hidden layers. Our findings provide useful insights towards developing vision systems that can perform reliably on real world images affected by blur.
Learning Sensor Multiplexing Design through Back-propagation
Nov 02, 2016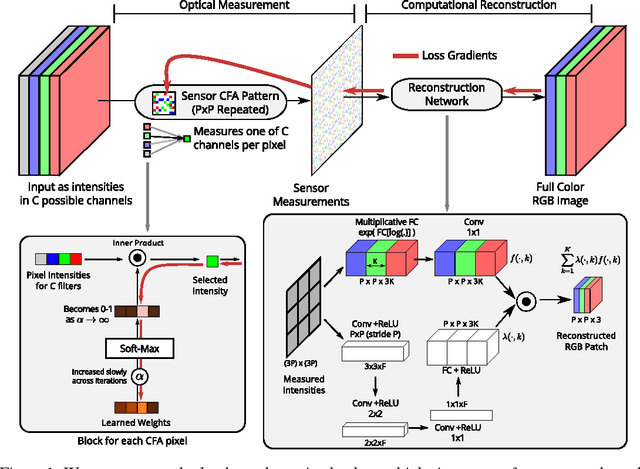

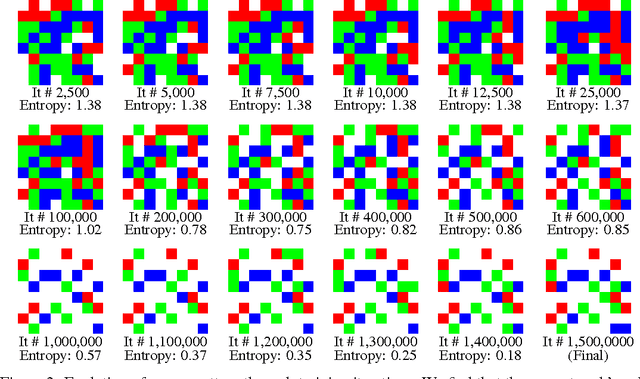
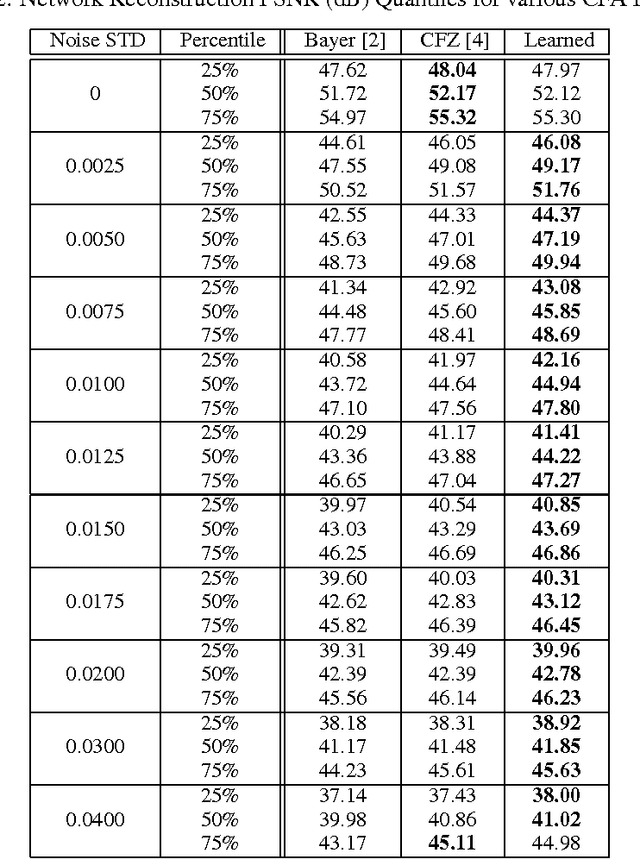
Recent progress on many imaging and vision tasks has been driven by the use of deep feed-forward neural networks, which are trained by propagating gradients of a loss defined on the final output, back through the network up to the first layer that operates directly on the image. We propose back-propagating one step further---to learn camera sensor designs jointly with networks that carry out inference on the images they capture. In this paper, we specifically consider the design and inference problems in a typical color camera---where the sensor is able to measure only one color channel at each pixel location, and computational inference is required to reconstruct a full color image. We learn the camera sensor's color multiplexing pattern by encoding it as layer whose learnable weights determine which color channel, from among a fixed set, will be measured at each location. These weights are jointly trained with those of a reconstruction network that operates on the corresponding sensor measurements to produce a full color image. Our network achieves significant improvements in accuracy over the traditional Bayer pattern used in most color cameras. It automatically learns to employ a sparse color measurement approach similar to that of a recent design, and moreover, improves upon that design by learning an optimal layout for these measurements.
Single-image RGB Photometric Stereo With Spatially-varying Albedo
Sep 14, 2016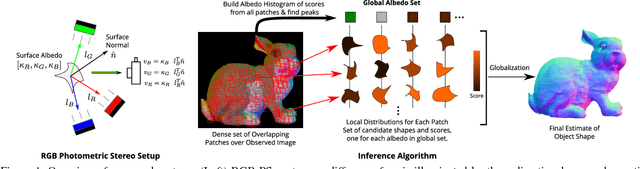
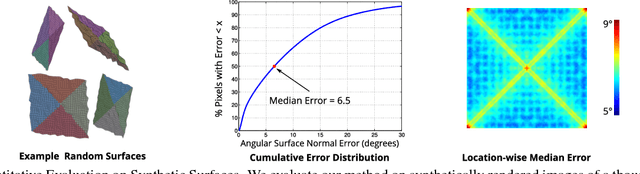
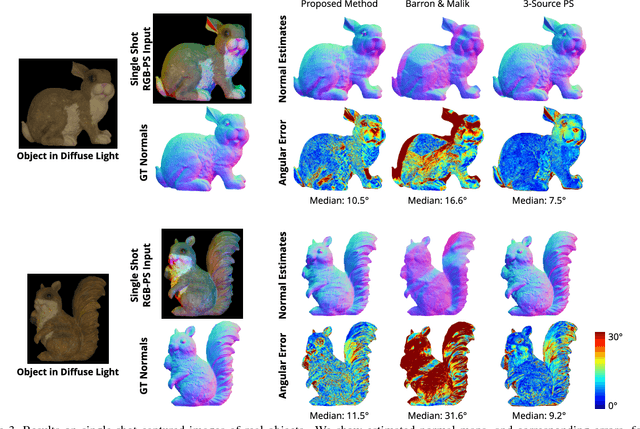
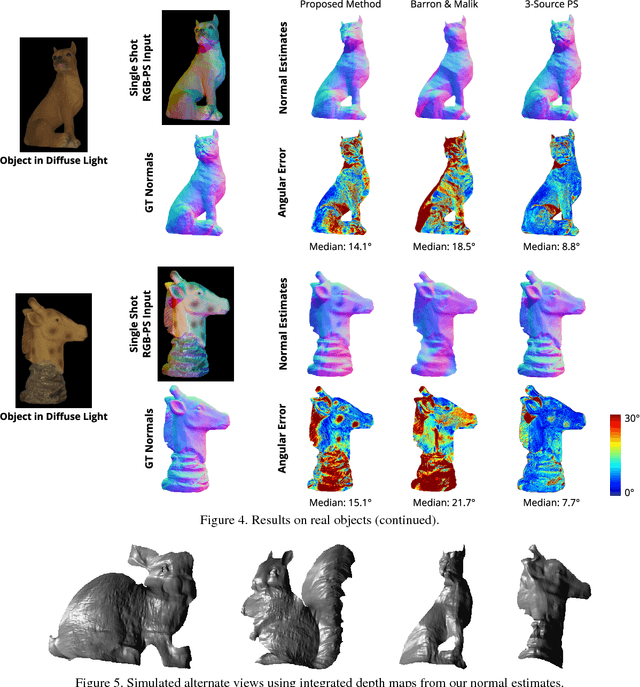
We present a single-shot system to recover surface geometry of objects with spatially-varying albedos, from images captured under a calibrated RGB photometric stereo setup---with three light directions multiplexed across different color channels in the observed RGB image. Since the problem is ill-posed point-wise, we assume that the albedo map can be modeled as piece-wise constant with a restricted number of distinct albedo values. We show that under ideal conditions, the shape of a non-degenerate local constant albedo surface patch can theoretically be recovered exactly. Moreover, we present a practical and efficient algorithm that uses this model to robustly recover shape from real images. Our method first reasons about shape locally in a dense set of patches in the observed image, producing shape distributions for every patch. These local distributions are then combined to produce a single consistent surface normal map. We demonstrate the efficacy of the approach through experiments on both synthetic renderings as well as real captured images.
Depth from a Single Image by Harmonizing Overcomplete Local Network Predictions
Sep 07, 2016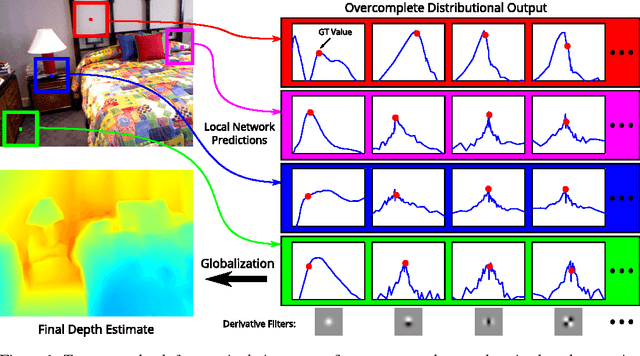
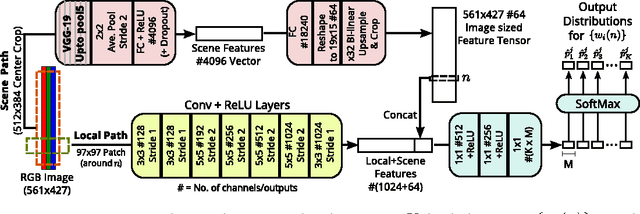
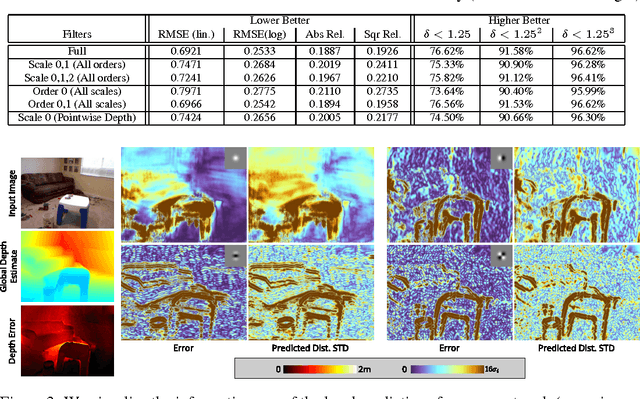
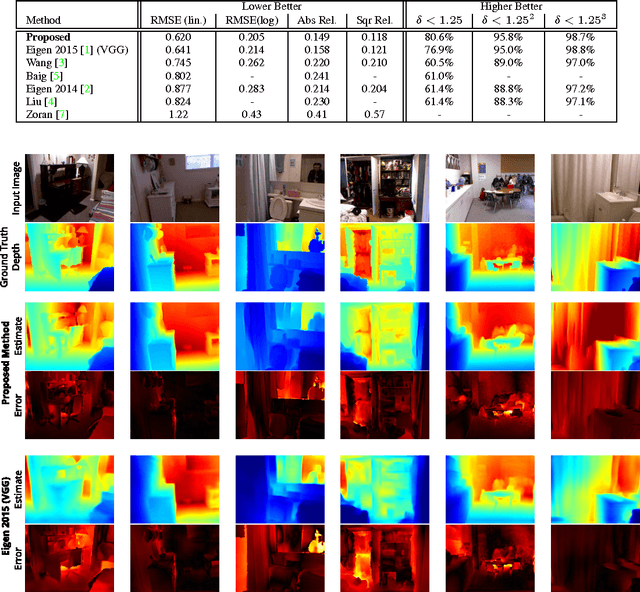
A single color image can contain many cues informative towards different aspects of local geometric structure. We approach the problem of monocular depth estimation by using a neural network to produce a mid-level representation that summarizes these cues. This network is trained to characterize local scene geometry by predicting, at every image location, depth derivatives of different orders, orientations and scales. However, instead of a single estimate for each derivative, the network outputs probability distributions that allow it to express confidence about some coefficients, and ambiguity about others. Scene depth is then estimated by harmonizing this overcomplete set of network predictions, using a globalization procedure that finds a single consistent depth map that best matches all the local derivative distributions. We demonstrate the efficacy of this approach through evaluation on the NYU v2 depth data set.
A Neural Approach to Blind Motion Deblurring
Aug 01, 2016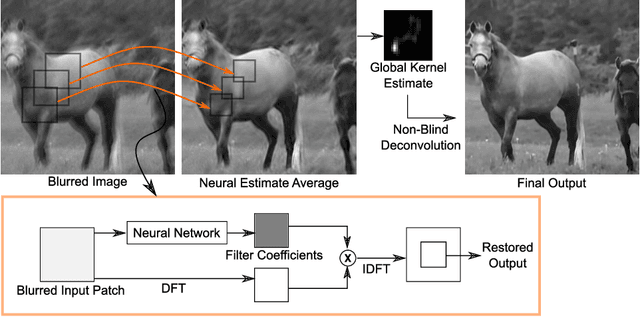
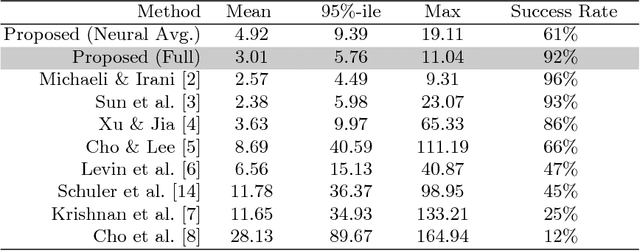
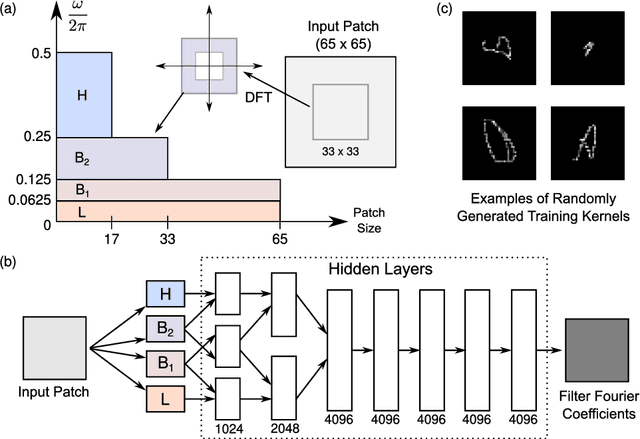
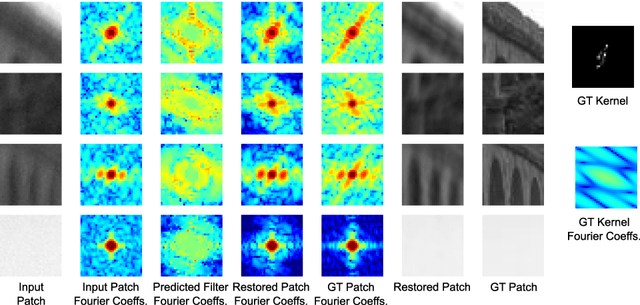
We present a new method for blind motion deblurring that uses a neural network trained to compute estimates of sharp image patches from observations that are blurred by an unknown motion kernel. Instead of regressing directly to patch intensities, this network learns to predict the complex Fourier coefficients of a deconvolution filter to be applied to the input patch for restoration. For inference, we apply the network independently to all overlapping patches in the observed image, and average its outputs to form an initial estimate of the sharp image. We then explicitly estimate a single global blur kernel by relating this estimate to the observed image, and finally perform non-blind deconvolution with this kernel. Our method exhibits accuracy and robustness close to state-of-the-art iterative methods, while being much faster when parallelized on GPU hardware.
Color Constancy by Learning to Predict Chromaticity from Luminance
Dec 07, 2015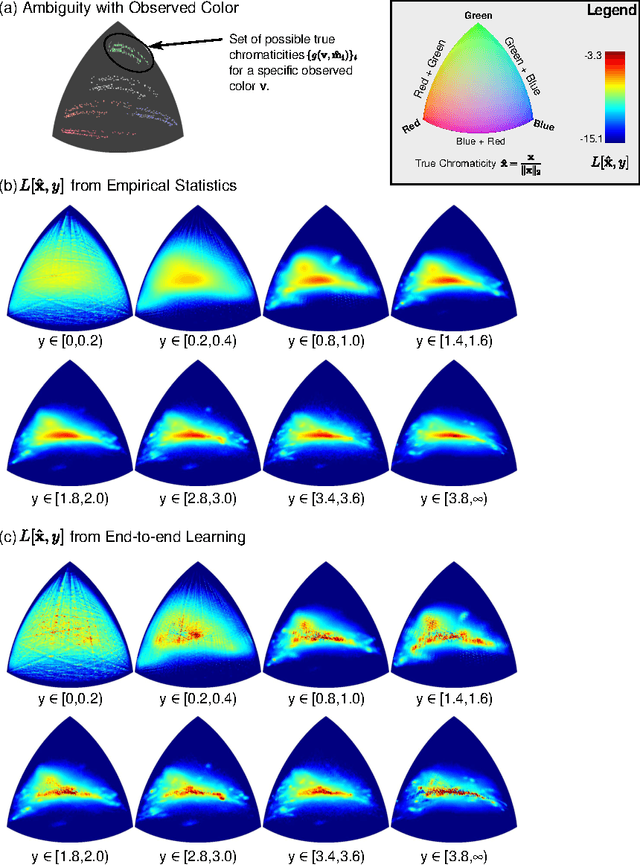
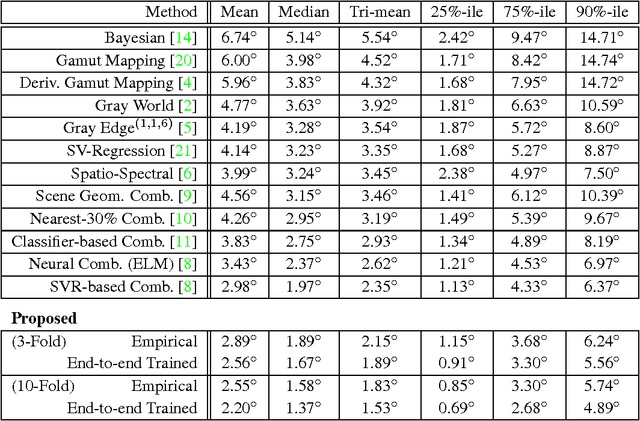

Color constancy is the recovery of true surface color from observed color, and requires estimating the chromaticity of scene illumination to correct for the bias it induces. In this paper, we show that the per-pixel color statistics of natural scenes---without any spatial or semantic context---can by themselves be a powerful cue for color constancy. Specifically, we describe an illuminant estimation method that is built around a "classifier" for identifying the true chromaticity of a pixel given its luminance (absolute brightness across color channels). During inference, each pixel's observed color restricts its true chromaticity to those values that can be explained by one of a candidate set of illuminants, and applying the classifier over these values yields a distribution over the corresponding illuminants. A global estimate for the scene illuminant is computed through a simple aggregation of these distributions across all pixels. We begin by simply defining the luminance-to-chromaticity classifier by computing empirical histograms over discretized chromaticity and luminance values from a training set of natural images. These histograms reflect a preference for hues corresponding to smooth reflectance functions, and for achromatic colors in brighter pixels. Despite its simplicity, the resulting estimation algorithm outperforms current state-of-the-art color constancy methods. Next, we propose a method to learn the luminance-to-chromaticity classifier "end-to-end". Using stochastic gradient descent, we set chromaticity-luminance likelihoods to minimize errors in the final scene illuminant estimates on a training set. This leads to further improvements in accuracy, most significantly in the tail of the error distribution.
Low-level Vision by Consensus in a Spatial Hierarchy of Regions
Apr 14, 2015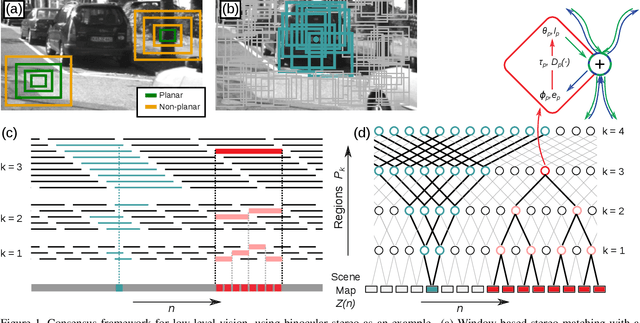
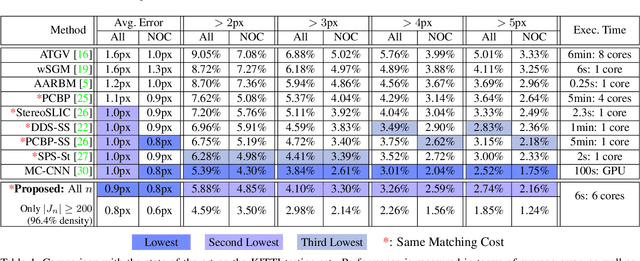

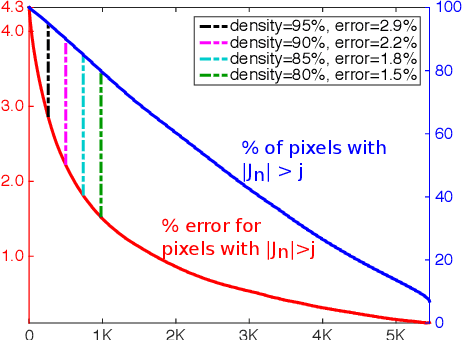
We introduce a multi-scale framework for low-level vision, where the goal is estimating physical scene values from image data---such as depth from stereo image pairs. The framework uses a dense, overlapping set of image regions at multiple scales and a "local model," such as a slanted-plane model for stereo disparity, that is expected to be valid piecewise across the visual field. Estimation is cast as optimization over a dichotomous mixture of variables, simultaneously determining which regions are inliers with respect to the local model (binary variables) and the correct co-ordinates in the local model space for each inlying region (continuous variables). When the regions are organized into a multi-scale hierarchy, optimization can occur in an efficient and parallel architecture, where distributed computational units iteratively perform calculations and share information through sparse connections between parents and children. The framework performs well on a standard benchmark for binocular stereo, and it produces a distributional scene representation that is appropriate for combining with higher-level reasoning and other low-level cues.
Modeling Radiometric Uncertainty for Vision with Tone-mapped Color Images
Apr 09, 2014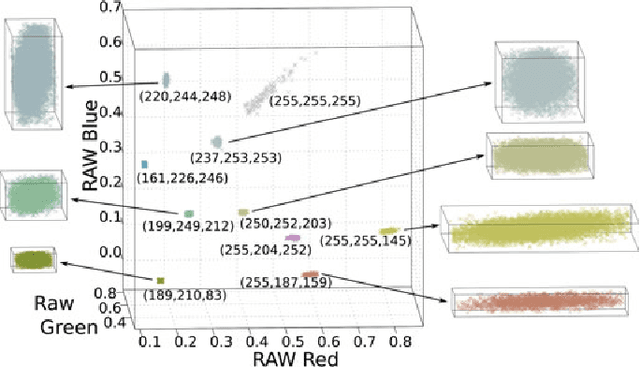
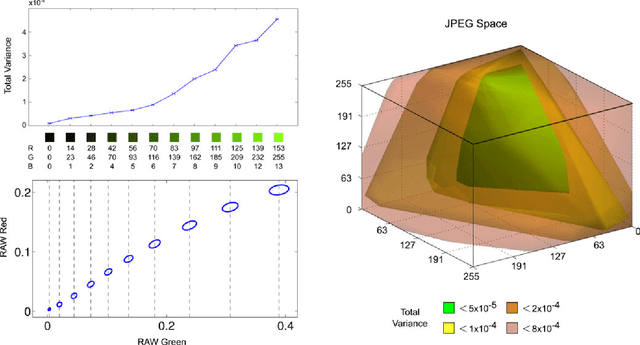

To produce images that are suitable for display, tone-mapping is widely used in digital cameras to map linear color measurements into narrow gamuts with limited dynamic range. This introduces non-linear distortion that must be undone, through a radiometric calibration process, before computer vision systems can analyze such photographs radiometrically. This paper considers the inherent uncertainty of undoing the effects of tone-mapping. We observe that this uncertainty varies substantially across color space, making some pixels more reliable than others. We introduce a model for this uncertainty and a method for fitting it to a given camera or imaging pipeline. Once fit, the model provides for each pixel in a tone-mapped digital photograph a probability distribution over linear scene colors that could have induced it. We demonstrate how these distributions can be useful for visual inference by incorporating them into estimation algorithms for a representative set of vision tasks.
From Shading to Local Shape
Apr 07, 2014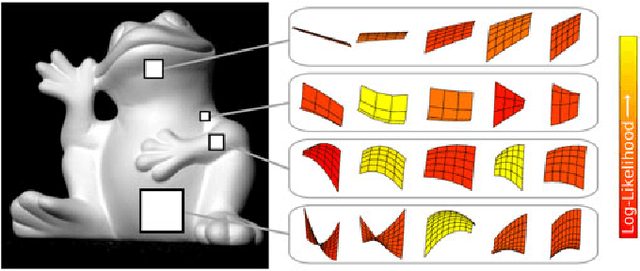


We develop a framework for extracting a concise representation of the shape information available from diffuse shading in a small image patch. This produces a mid-level scene descriptor, comprised of local shape distributions that are inferred separately at every image patch across multiple scales. The framework is based on a quadratic representation of local shape that, in the absence of noise, has guarantees on recovering accurate local shape and lighting. And when noise is present, the inferred local shape distributions provide useful shape information without over-committing to any particular image explanation. These local shape distributions naturally encode the fact that some smooth diffuse regions are more informative than others, and they enable efficient and robust reconstruction of object-scale shape. Experimental results show that this approach to surface reconstruction compares well against the state-of-art on both synthetic images and captured photographs.
Image Restoration with Signal-dependent Camera Noise
Apr 13, 2012
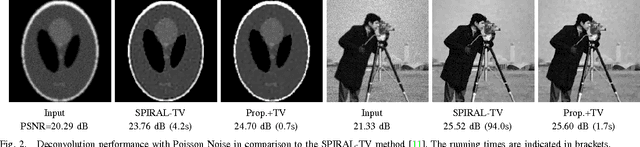
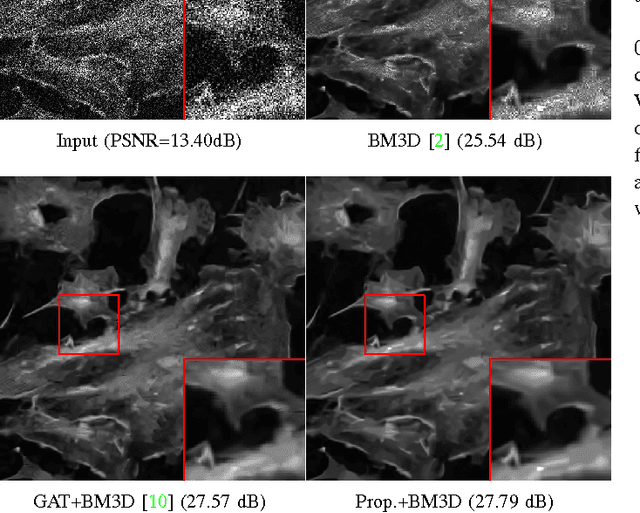
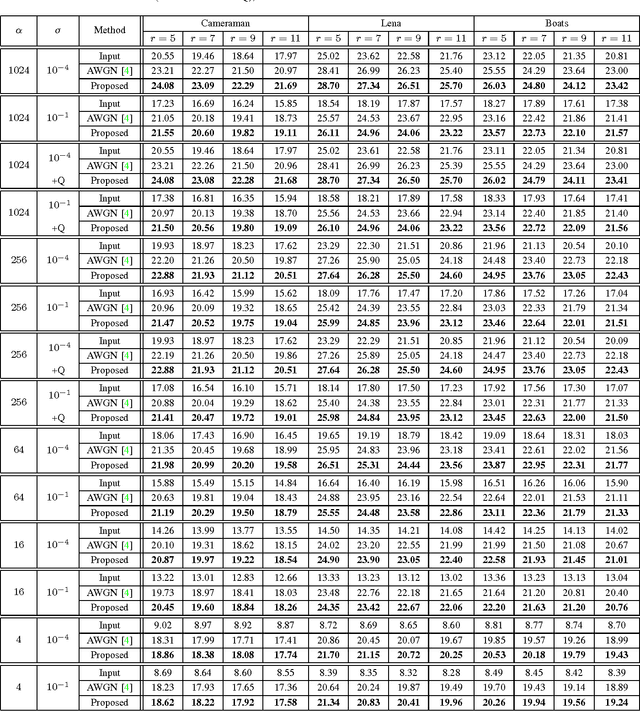
This article describes a fast iterative algorithm for image denoising and deconvolution with signal-dependent observation noise. We use an optimization strategy based on variable splitting that adapts traditional Gaussian noise-based restoration algorithms to account for the observed image being corrupted by mixed Poisson-Gaussian noise and quantization errors.