 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Labelled Data Scarcity: Taxonomy-Agnostic Annotation of PII Values in HTTP Traffic using LLMs
May 07, 2026Automated privacy audits of web and mobile applications often analyse outbound HTTP traffic to detect Personally Identifiable Information (PII) leakage. However, existing learning-based detectors typically depend on scarce, manually labelled traffic and are tightly coupled to fixed label taxonomies, limiting transferability across domains and evolving definitions of PII. This paper investigates whether Large Language Models (LLMs) can support taxonomy-agnostic annotation of explicitly transmitted PII values in HTTP message bodies when the taxonomy is provided at runtime. We introduce a multi-stage LLM-based pipeline that combines deterministic pre-processing with label-level classification, targeted instance-level value annotation, and output validation. To enable controlled evaluation and exemplar-based prompting without relying on sensitive real-user captures, we further propose an LLM-based generator for synthetic HTTP traffic with manually validated, taxonomy-derived PII annotations. We evaluate the approach across three taxonomies spanning different PII domains and granularity levels. Results show that the pipeline accurately detects PII types and extracts corresponding values for concrete PII taxonomies. Overall, our findings position LLMs as a promising foundation for flexible, taxonomy-agnostic traffic annotation and for creating labelled data under evolving privacy taxonomies.
Word-level Annotation of GDPR Transparency Compliance in Privacy Policies using Large Language Models
Mar 13, 2025Ensuring transparency of data practices related to personal information is a fundamental requirement under the General Data Protection Regulation (GDPR), particularly as mandated by Articles 13 and 14. However, assessing compliance at scale remains a challenge due to the complexity and variability of privacy policy language. Manual audits are resource-intensive and inconsistent, while existing automated approaches lack the granularity needed to capture nuanced transparency disclosures. In this paper, we introduce a large language model (LLM)-based framework for word-level GDPR transparency compliance annotation. Our approach comprises a two-stage annotation pipeline that combines initial LLM-based annotation with a self-correction mechanism for iterative refinement. This annotation pipeline enables the systematic identification and fine-grained annotation of transparency-related content in privacy policies, aligning with 21 GDPR-derived transparency requirements. To enable large-scale analysis, we compile a dataset of 703,791 English-language policies, from which we generate a sample of 200 manually annotated privacy policies. To evaluate our approach, we introduce a two-tiered methodology assessing both label- and span-level annotation performance. We conduct a comparative analysis of eight high-profile LLMs, providing insights into their effectiveness in identifying GDPR transparency disclosures. Our findings contribute to advancing the automation of GDPR compliance assessments and provide valuable resources for future research in privacy policy analysis.
Anomaly Detection with HMM Gauge Likelihood Analysis
Jun 14, 2019


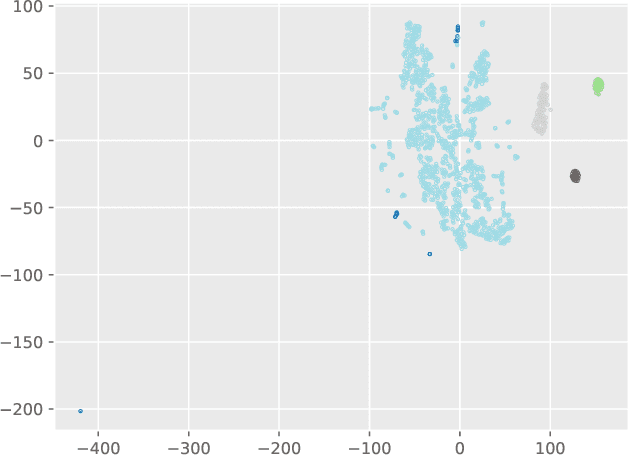
This paper describes a new method, HMM gauge likelihood analysis, or GLA, of detecting anomalies in discrete time series using Hidden Markov Models and clustering. At the center of the method lies the comparison of subsequences. To achieve this, they first get assigned to their Hidden Markov Models using the Baum-Welch algorithm. Next, those models are described by an approximating representation of the probability distributions they define. Finally, this representation is then analyzed with the help of some clustering technique or other outlier detection tool and anomalies are detected. Clearly, HMMs could be substituted by some other appropriate model, e.g. some other dynamic Bayesian network. Our learning algorithm is unsupervised, so it does not require the labeling of large amounts of data. The usability of this method is demonstrated by applying it to synthetic and real-world syslog data.