 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOOK: A System for Probabilistic Object-Oriented Knowledge Representation
Jan 23, 2013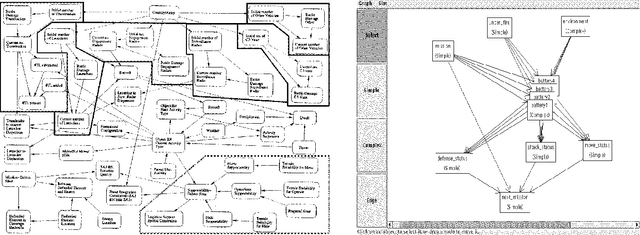
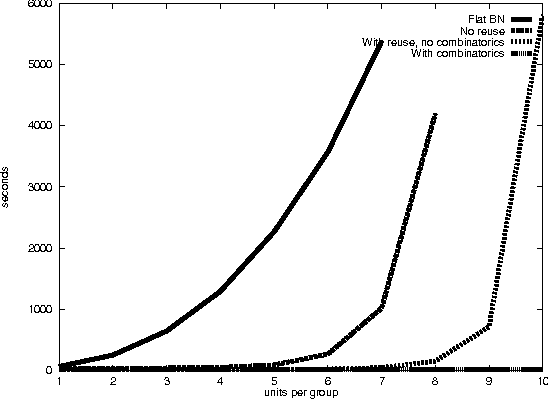
In previous work, we pointed out the limitations of standard Bayesian networks as a modeling framework for large, complex domains. We proposed a new, richly structured modeling language, {em Object-oriented Bayesian Netorks}, that we argued would be able to deal with such domains. However, it turns out that OOBNs are not expressive enough to model many interesting aspects of complex domains: the existence of specific named objects, arbitrary relations between objects, and uncertainty over domain structure. These aspects are crucial in real-world domains such as battlefield awareness. In this paper, we present SPOOK, an implemented system that addresses these limitations. SPOOK implements a more expressive language that allows it to represent the battlespace domain naturally and compactly. We present a new inference algorithm that utilizes the model structure in a fundamental way, and show empirically that it achieves orders of magnitude speedup over existing approaches.
Sufficiency, Separability and Temporal Probabilistic Models
Jan 10, 2013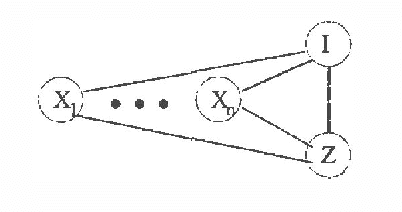
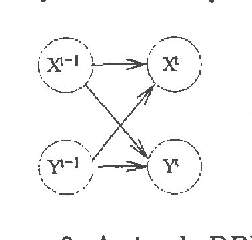
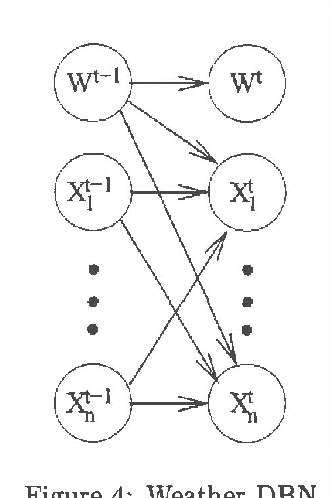
Suppose we are given the conditional probability of one variable given some other variables.Normally the full joint distribution over the conditioning variablesis required to determine the probability of the conditioned variable.Under what circumstances are the marginal distributions over the conditioning variables sufficient to determine the probability ofthe conditioned variable?Sufficiency in this sense is equivalent to additive separability ofthe conditional probability distribution.Such separability structure is natural and can be exploited forefficient inference.Separability has a natural generalization to conditional separability.Separability provides a precise notion of weaklyinteracting subsystems in temporal probabilistic models.Given a system that is decomposed into separable subsystems, exactmarginal probabilities over subsystems at future points in time can becomputed by propagating marginal subsystem probabilities, rather thancomplete system joint probabilities.Thus, separability can make exact prediction tractable.However, observations can break separability,so exact monitoring of dynamic systems remains hard.
Factored Particles for Scalable Monitoring
Dec 12, 2012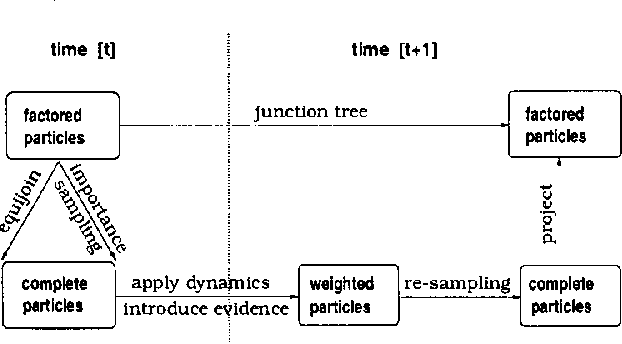
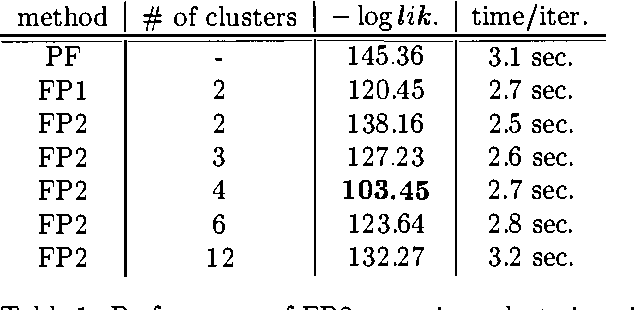
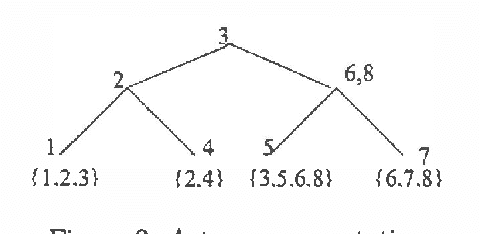
Exact monitoring in dynamic Bayesian networks is intractable, so approximate algorithms are necessary. This paper presents a new family of approximate monitoring algorithms that combine the best qualities of the particle filtering and Boyen-Koller methods. Our algorithms maintain an approximate representation the belief state in the form of sets of factored particles, that correspond to samples of clusters of state variables. Empirical results show that our algorithms outperform both ordinary particle filtering and the Boyen-Koller algorithm on large systems.
Loopy Belief Propagation as a Basis for Communication in Sensor Networks
Oct 19, 2012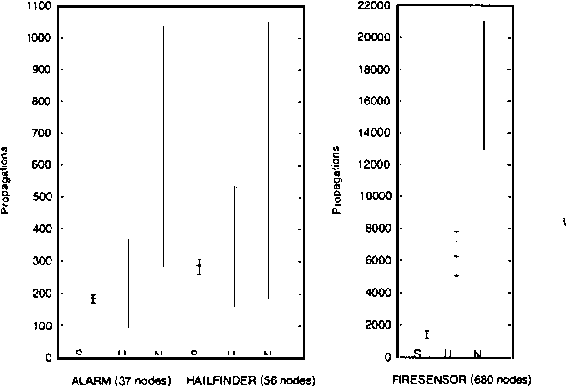
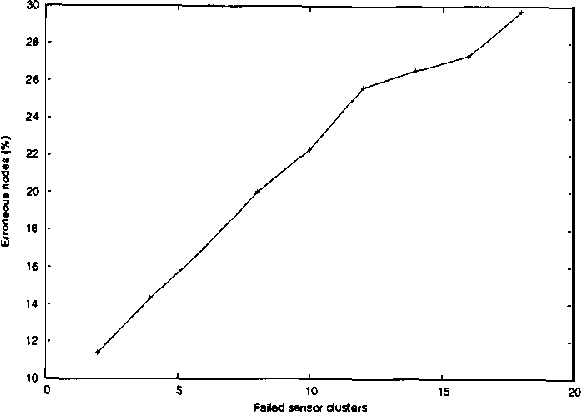
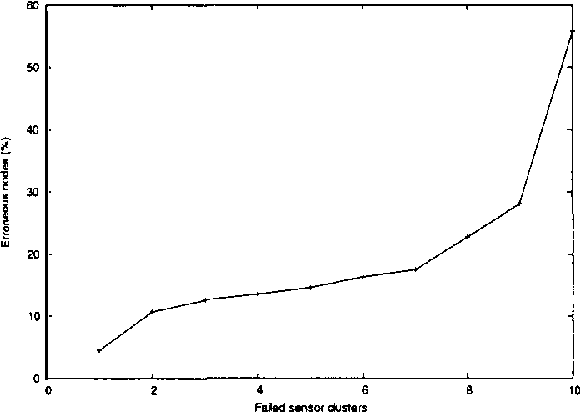
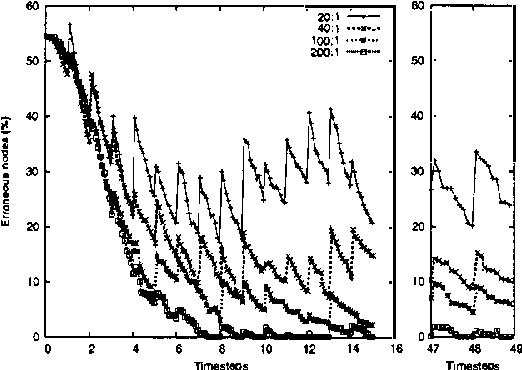
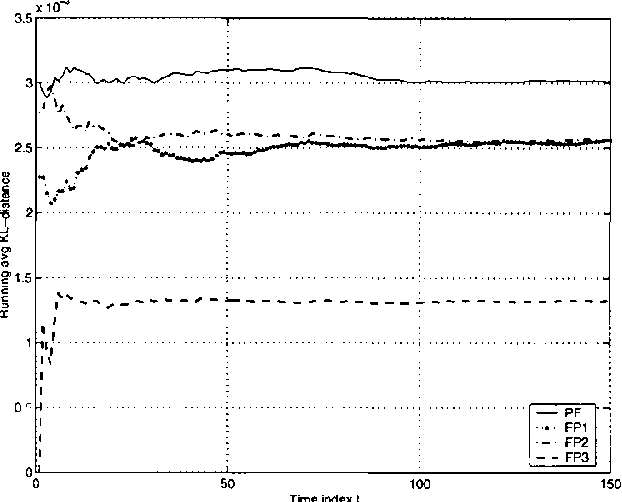
Sensor networks are an exciting new kind of computer system. Consisting of a large number of tiny, cheap computational devices physically distributed in an environment, they gather and process data about the environment in real time. One of the central questions in sensor networks is what to do with the data, i.e., how to reason with it and how to communicate it. This paper argues that the lessons of the UAI community, in particular that one should produce and communicate beliefs rather than raw sensor values, are highly relevant to sensor networks. We contend that loopy belief propagation is particularly well suited to communicating beliefs in sensor networks, due to its compact implementation and distributed nature. We investigate the ability of loopy belief propagation to function under the stressful conditions likely to prevail in sensor networks. Our experiments show that it performs well and degrades gracefully. It converges to appropriate beliefs even in highly asynchronous settings where some nodes communicate far less frequently than others; it continues to function if some nodes fail to participate in the propagation process; and it can track changes in the environment that occur while beliefs are propagating. As a result, we believe that sensor networks present an important application opportunity for UAI.
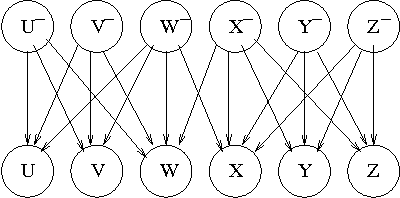
Asynchronous Dynamic Bayesian Networks
Jul 04, 2012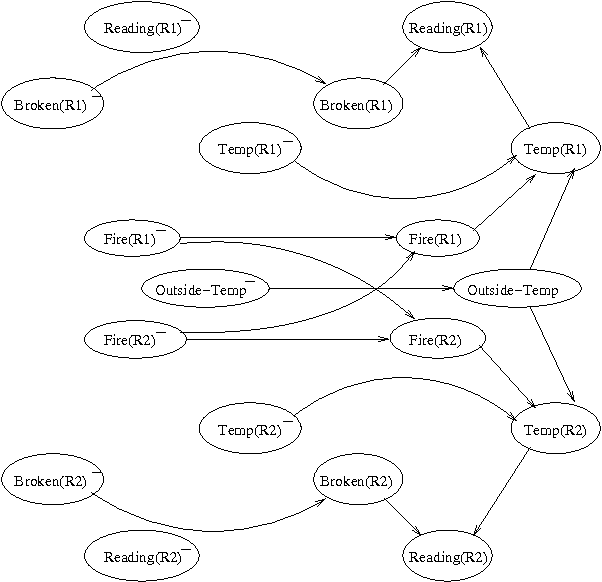
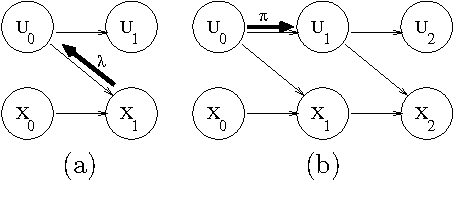

Systems such as sensor networks and teams of autonomous robots consist of multiple autonomous entities that interact with each other in a distributed, asynchronous manner. These entities need to keep track of the state of the system as it evolves. Asynchronous systems lead to special challenges for monitoring, as nodes must update their beliefs independently of each other and no central coordination is possible. Furthermore, the state of the system continues to change as beliefs are being updated. Previous approaches to developing distributed asynchronous probabilistic reasoning systems have used static models. We present an approach using dynamic models, that take into account the way the system changes state over time. Our approach, which is based on belief propagation, is fully distributed and asynchronous, and allows the world to keep on changing as messages are being sent around. Experimental results show that our approach compares favorably to the factored frontier algorithm.
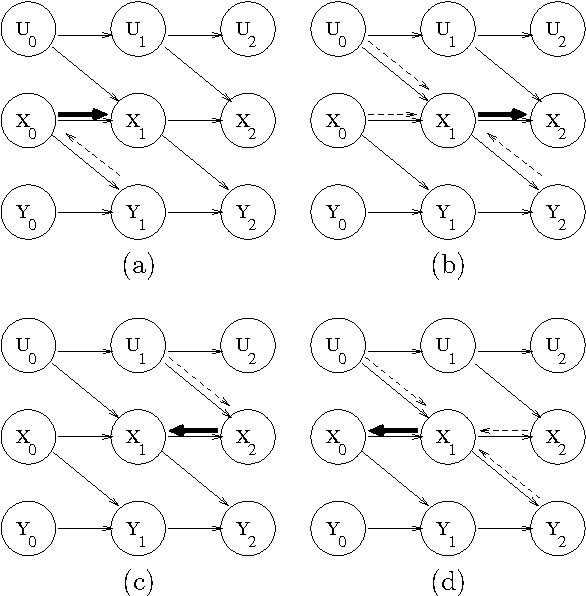
Approximate Separability for Weak Interaction in Dynamic Systems
Jun 27, 2012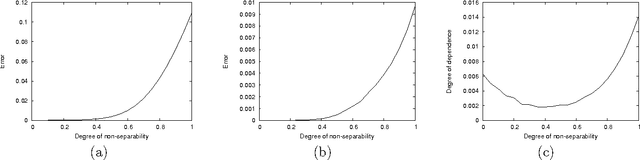
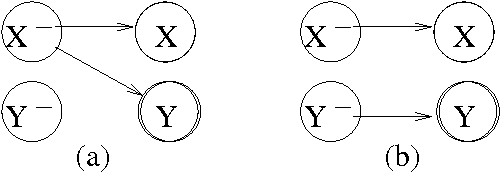
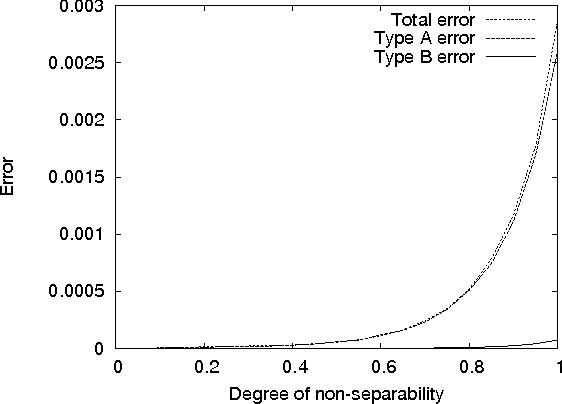
One approach to monitoring a dynamic system relies on decomposition of the system into weakly interacting subsystems. An earlier paper introduced a notion of weak interaction called separability, and showed that it leads to exact propagation of marginals for prediction. This paper addresses two questions left open by the earlier paper: can we define a notion of approximate separability that occurs naturally in practice, and do separability and approximate separability lead to accurate monitoring? The answer to both questions is afirmative. The paper also analyzes the structure of approximately separable decompositions, and provides some explanation as to why these models perform well.
Learning and Solving Many-Player Games through a Cluster-Based Representation
Jun 13, 2012
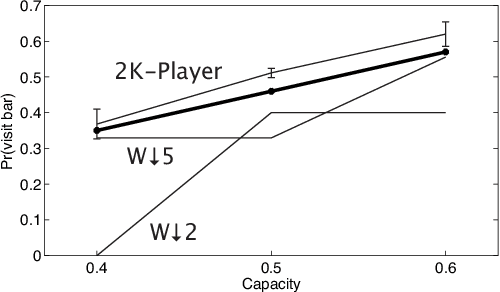

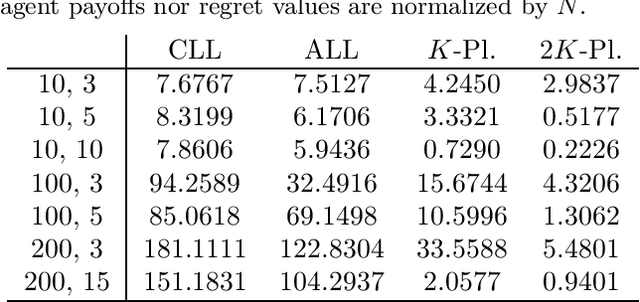
In addressing the challenge of exponential scaling with the number of agents we adopt a cluster-based representation to approximately solve asymmetric games of very many players. A cluster groups together agents with a similar "strategic view" of the game. We learn the clustered approximation from data consisting of strategy profiles and payoffs, which may be obtained from observations of play or access to a simulator. Using our clustering we construct a reduced "twins" game in which each cluster is associated with two players of the reduced game. This allows our representation to be individually- responsive because we align the interests of every individual agent with the strategy of its cluster. Our approach provides agents with higher payoffs and lower regret on average than model-free methods as well as previous cluster-based methods, and requires only few observations for learning to be successful. The "twins" approach is shown to be an important component of providing these low regret approximations.
Identifying reasoning patterns in games
Jun 13, 2012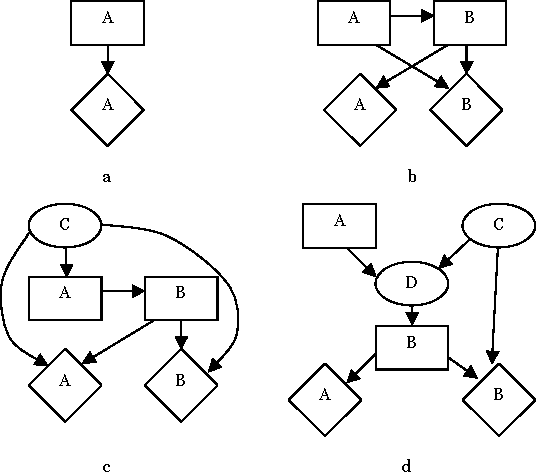
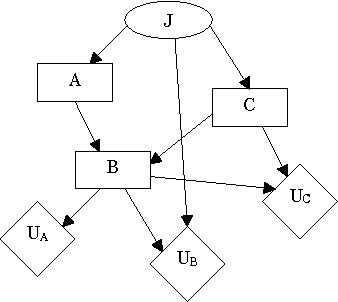
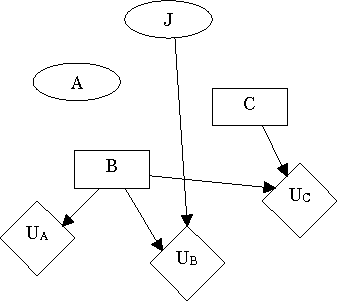
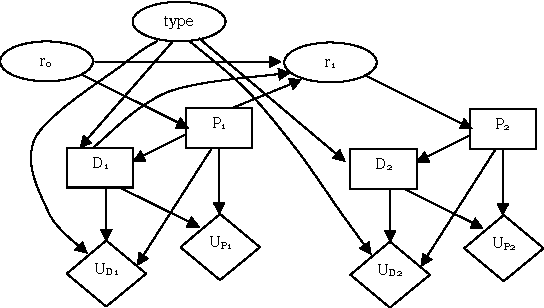
We present an algorithm that identifies the reasoning patterns of agents in a game, by iteratively examining the graph structure of its Multi-Agent Influence Diagram (MAID) representation. If the decision of an agent participates in no reasoning patterns, then we can effectively ignore that decision for the purpose of calculating a Nash equilibrium for the game. In some cases, this can lead to exponential time savings in the process of equilibrium calculation. Moreover, our algorithm can be used to enumerate the reasoning patterns in a game, which can be useful for constructing more effective computerized agents interacting with humans.
Temporal Action-Graph Games: A New Representation for Dynamic Games
May 09, 2012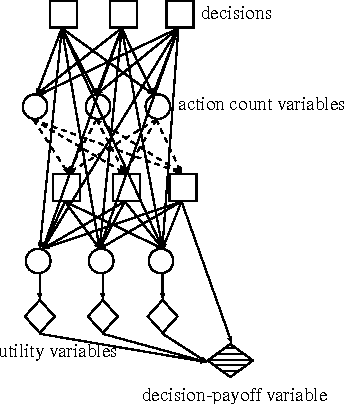
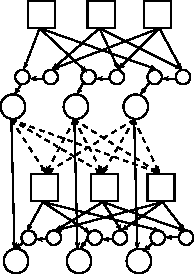

In this paper we introduce temporal action graph games (TAGGs), a novel graphical representation of imperfect-information extensive form games. We show that when a game involves anonymity or context-specific utility independencies, its encoding as a TAGG can be much more compact than its direct encoding as a multiagent influence diagram (MAID).We also show that TAGGs can be understood as indirect MAID encodings in which many deterministic chance nodes are introduced. We provide an algorithm for computing with TAGGs, and show both theoretically and empirically that our approach improves significantly on the previous state of the art.
Learning Game Representations from Data Using Rationality Constraints
Mar 15, 2012
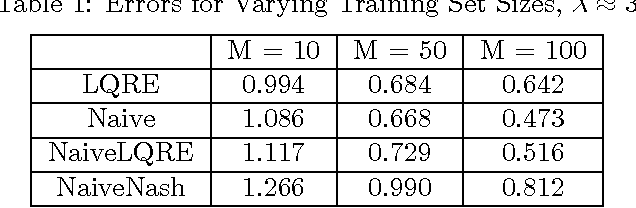
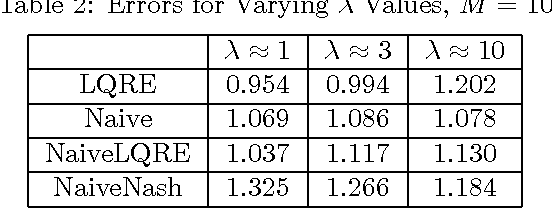
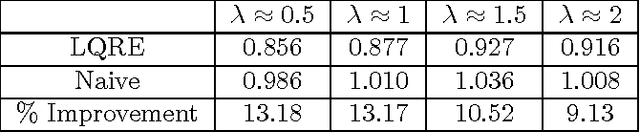
While game theory is widely used to model strategic interactions, a natural question is where do the game representations come from? One answer is to learn the representations from data. If one wants to learn both the payoffs and the players' strategies, a naive approach is to learn them both directly from the data. This approach ignores the fact the players might be playing reasonably good strategies, so there is a connection between the strategies and the data. The main contribution of this paper is to make this connection while learning. We formulate the learning problem as a weighted constraint satisfaction problem, including constraints both for the fit of the payoffs and strategies to the data and the fit of the strategies to the payoffs. We use quantal response equilibrium as our notion of rationality for quantifying the latter fit. Our results show that incorporating rationality constraints can improve learning when the amount of data is limited.