 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Humour-Aware Retrieval with Dense and Re-Ranking Models
May 24, 2026Humour-aware information retrieval poses unique challenges beyond standard semantic retrieval, as systems must account not only for topical relevance but also for humour-specific linguistic phenomena such as wordplay, phonetic ambiguity, and polysemy. In this paper, Team DUTH studies multilingual humour-aware information retrieval using the CLEF 2025 JOKER Task 1 benchmark, which evaluates humour retrieval in English and Portuguese. Our approach combines multilingual XLM-RoBERTa-based dense retrieval with additional system variants, including neural re-ranking, in order to assess the extent to which general-purpose Transformer models can capture humour-specific relevance. The results reveal substantial cross-lingual variation. While the Portuguese runs demonstrate comparatively strong performance across MAP, MRR, and early precision metrics, the English runs perform significantly worse, with relevant humorous documents frequently appearing at lower ranks. These findings highlight the limitations of purely semantic dense representations for humour retrieval, particularly when humour depends on surface-level cues that are not explicitly modelled by multilingual encoders. We further analyse contributing factors to this discrepancy, including dataset characteristics, query-document alignment, and variation in humour mechanisms. Overall, the Team DUTH experiments establish multilingual dense-retrieval and re-ranking baselines and provide insights into the challenges of modelling humour-aware relevance within the JOKER framework.
CAMIL: Context-Aware Multiple Instance Learning for Whole Slide Image Classification
May 09, 2023



Cancer diagnoses typically involve human pathologists examining whole slide images (WSIs) of tissue section biopsies to identify tumor cells and their subtypes. However, artificial intelligence (AI)-based models, particularly weakly supervised approaches, have recently emerged as viable alternatives. Weakly supervised approaches often use image subsections or tiles as input, with the overall classification of the WSI based on attention scores assigned to each tile. However, this method overlooks the potential for false positives/negatives because tumors can be heterogeneous, with cancer and normal cells growing in patterns larger than a single tile. Such errors at the tile level could lead to misclassification at the tumor level. To address this limitation, we developed a novel deep learning pooling operator called CHARM (Contrastive Histopathology Attention Resolved Models). CHARM leverages the dependencies among single tiles within a WSI and imposes contextual constraints as prior knowledge to multiple instance learning models. We tested CHARM on the subtyping of non-small cell lung cancer (NSLC) and lymph node (LN) metastasis, and the results demonstrated its superiority over other state-of-the-art weakly supervised classification algorithms. Furthermore, CHARM facilitates interpretability by visualizing regions of attention.
DUTH at SemEval-2020 Task 11: BERT with Entity Mapping for Propaganda Classification
Aug 25, 2020
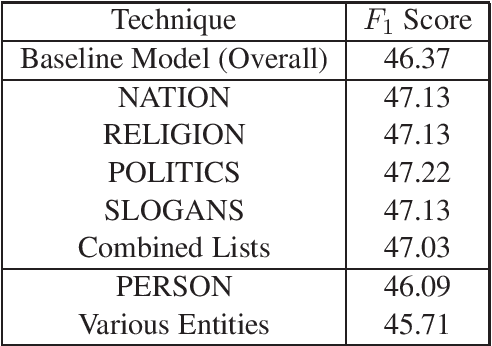
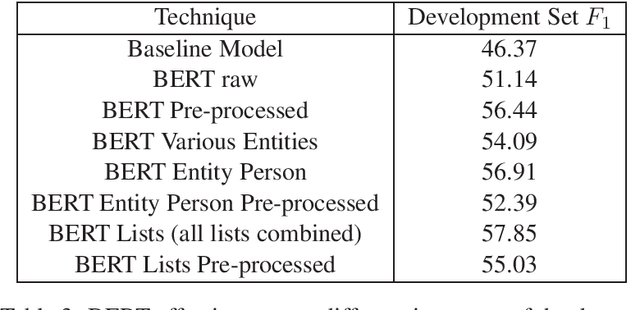
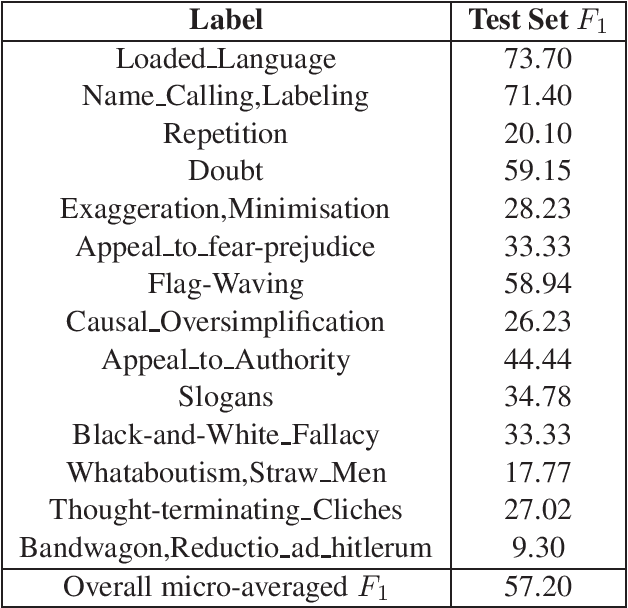
This report describes the methods employed by the Democritus University of Thrace (DUTH) team for participating in SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. Our team dealt with Subtask 2: Technique Classification. We used shallow Natural Language Processing (NLP) preprocessing techniques to reduce the noise in the dataset, feature selection methods, and common supervised machine learning algorithms. Our final model is based on using the BERT system with entity mapping. To improve our model's accuracy, we mapped certain words into five distinct categories by employing word-classes and entity recognition.