 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Reinforcement Learning for 2D Irregular Nesting
Jun 09, 2026Traditional heuristic solvers for the 2D irregular nesting problem share a fundamental limitation: they are blind to polygon geometry, relying on guided brute-force to navigate the continuous placement space with minimal geometrical guidance. In this paper, we argue that Reinforcement Learning is uniquely positioned to overcome this bottleneck. By pairing an optimization policy with a geometry-aware neural encoder, an agent can automatically discover rich geometric priors directly from data, utilizing these learned intuitions to strategically guide exploration. To realize this, we introduce the Polygons Transformer (PoT), a novel architecture that encodes 2D continuous vector geometries while allowing cross-polygons attention. We couple this novel architecture with a Combinatorial Optimization Reinforcement Learning (CORL) training framework to find optimal solutions. To support this paradigm, we release an open-source training dataset derived from complex geographic contours alongside a dedicated evaluation benchmark. Our empirical validation demonstrates that our trained agent achieves area utilization performance highly competitive with Sparrow, the state-of-the-art heuristic solver, proving that reinforcement learning can successfully discover and exploit geometric awareness for precise spatial tasks.
Fixed $β$-VAE Encoding for Curious Exploration in Complex 3D Environments
May 18, 2021
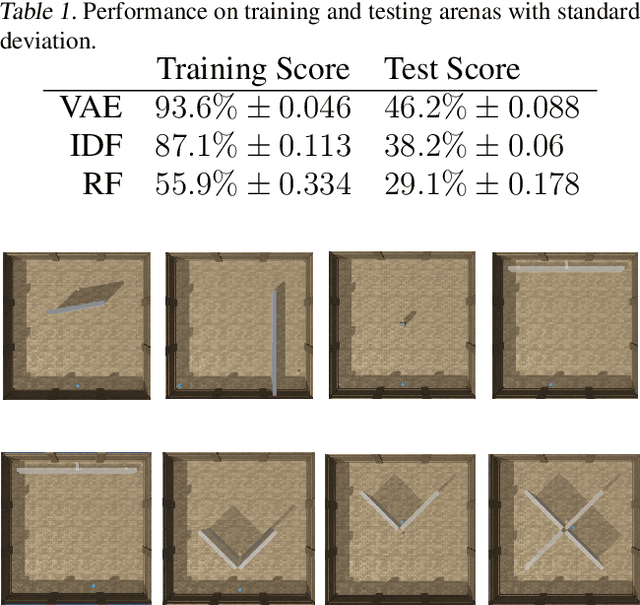
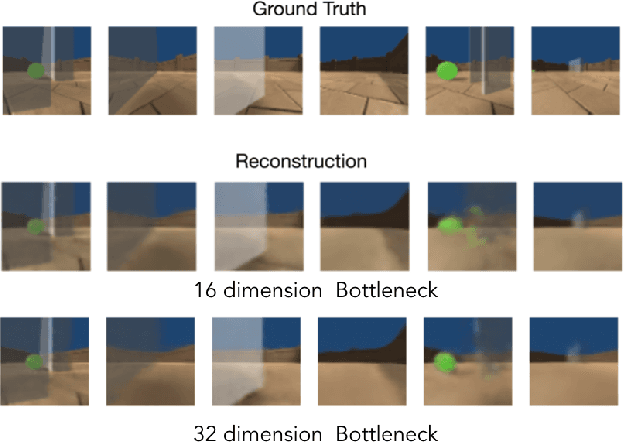
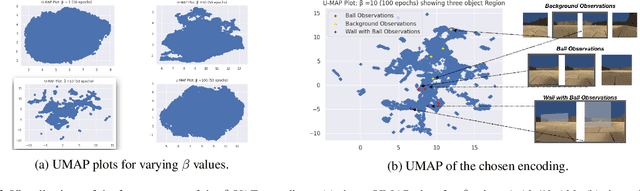
Curiosity is a general method for augmenting an environment reward with an intrinsic reward, which encourages exploration and is especially useful in sparse reward settings. As curiosity is calculated using next state prediction error, the type of state encoding used has a large impact on performance. Random features and inverse-dynamics features are generally preferred over VAEs based on previous results from Atari and other mostly 2D environments. However, unlike VAEs, they may not encode sufficient information for optimal behaviour, which becomes increasingly important as environments become more complex. In this paper, we use the sparse reward 3D physics environment Animal-AI, to demonstrate how a fixed $\beta$-VAE encoding can be used effectively with curiosity. We combine this with curriculum learning to solve the previously unsolved exploration intensive detour tasks while achieving 22\% gain in sample efficiency on the training curriculum against the next best encoding. We also corroborate the results on Atari Breakout, with our custom encoding outperforming random features and inverse-dynamics features.