 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topic Model for Melodic Sequences
Jun 27, 2012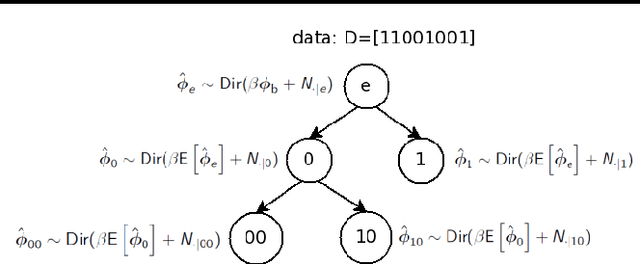
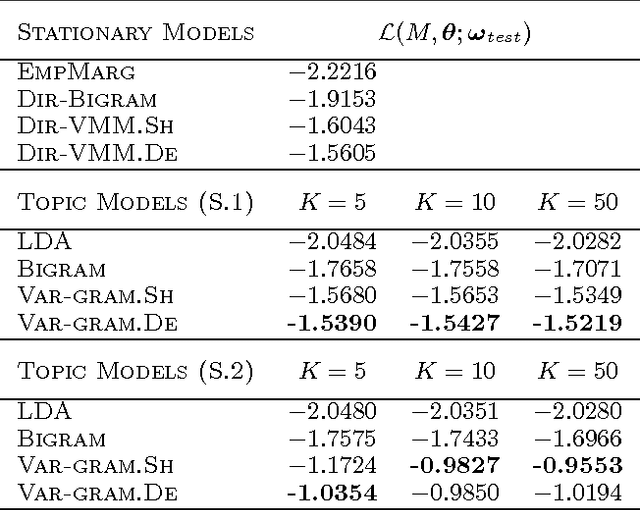
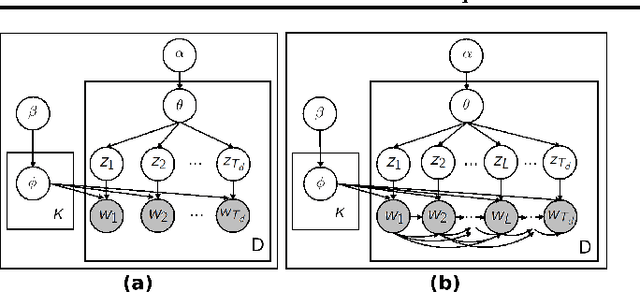
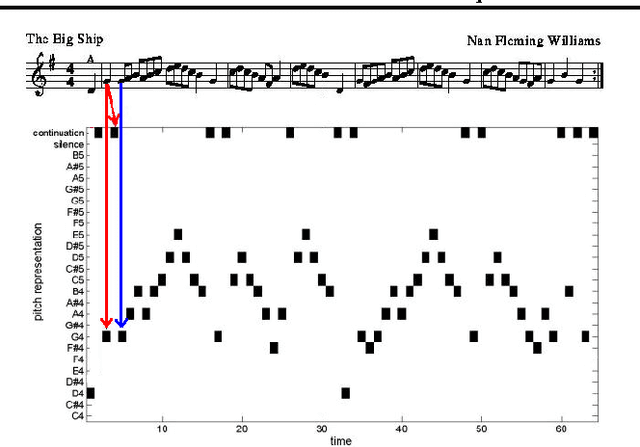
We examine the problem of learning a probabilistic model for melody directly from musical sequences belonging to the same genre. This is a challenging task as one needs to capture not only the rich temporal structure evident in music, but also the complex statistical dependencies among different music components. To address this problem we introduce the Variable-gram Topic Model, which couples the latent topic formalism with a systematic model for contextual information. We evaluate the model on next-step prediction. Additionally, we present a novel way of model evaluation, where we directly compare model samples with data sequences using the Maximum Mean Discrepancy of string kernels, to assess how close is the model distribution to the data distribution. We show that the model has the highest performance under both evaluation measures when compared to LDA, the Topic Bigram and related non-topic models.
Comparing Probabilistic Models for Melodic Sequences
Sep 30, 2011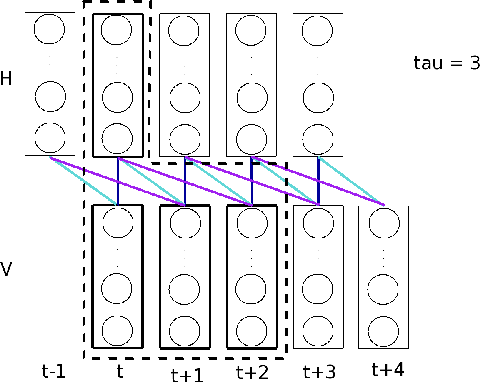
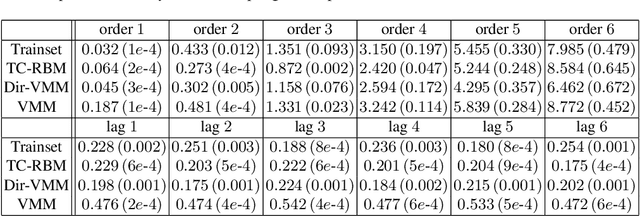
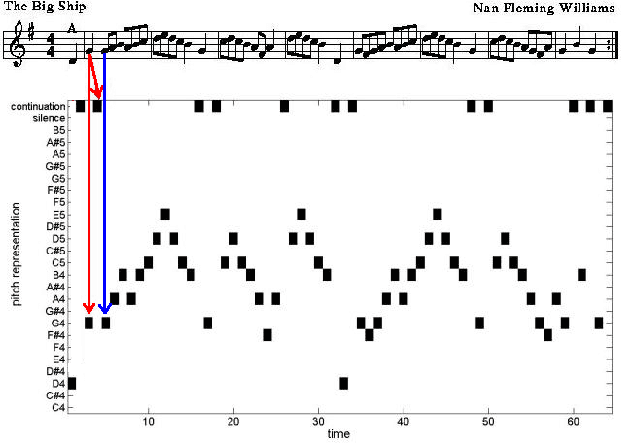
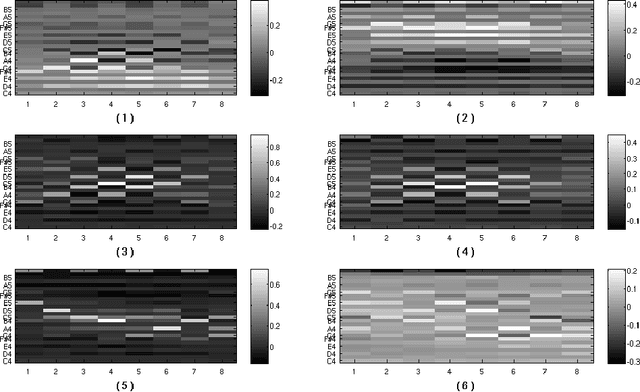
Modelling the real world complexity of music is a challenge for machine learning. We address the task of modeling melodic sequences from the same music genre. We perform a comparative analysis of two probabilistic models; a Dirichlet Variable Length Markov Model (Dirichlet-VMM) and a Time Convolutional Restricted Boltzmann Machine (TC-RBM). We show that the TC-RBM learns descriptive music features, such as underlying chords and typical melody transitions and dynamics. We assess the models for future prediction and compare their performance to a VMM, which is the current state of the art in melody generation. We show that both models perform significantly better than the VMM, with the Dirichlet-VMM marginally outperforming the TC-RBM. Finally, we evaluate the short order statistics of the models, using the Kullback-Leibler divergence between test sequences and model samples, and show that our proposed methods match the statistics of the music genre significantly better than the VMM.
* in Proceedings of the ECML-PKDD 2011. Lecture Notes in Computer Science, vol. 6913, pp. 289-304. Springer (2011)