 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Generation from a Single Video Made Possible
Sep 17, 2021

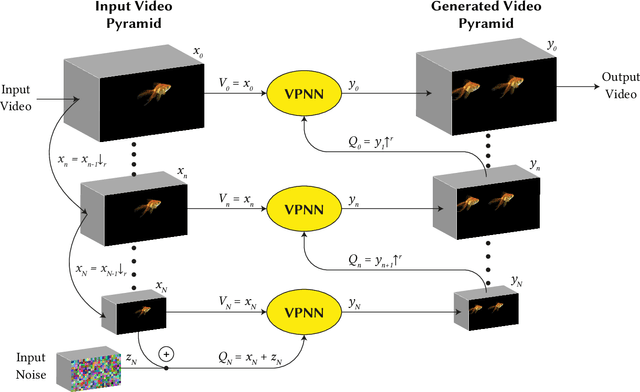
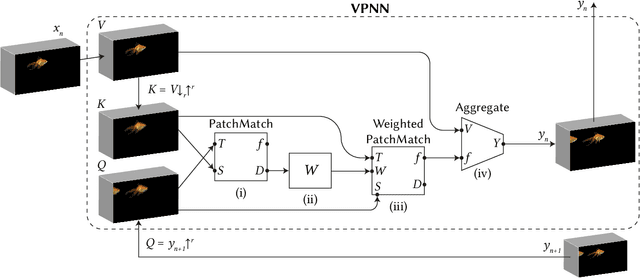
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
Mar 29, 2021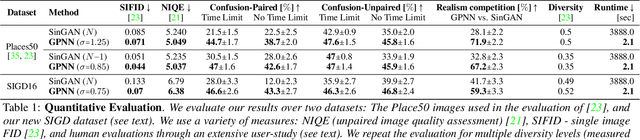
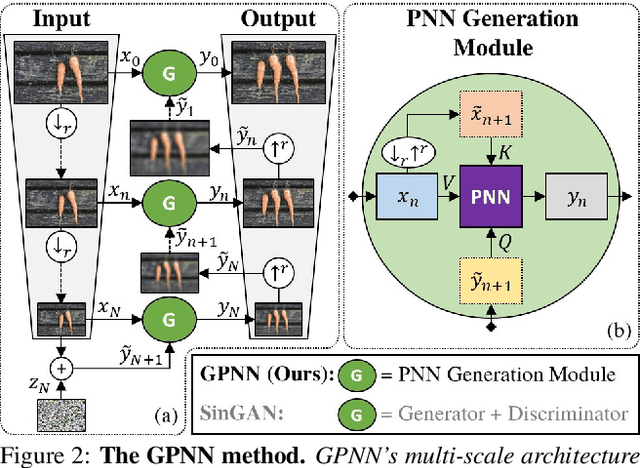
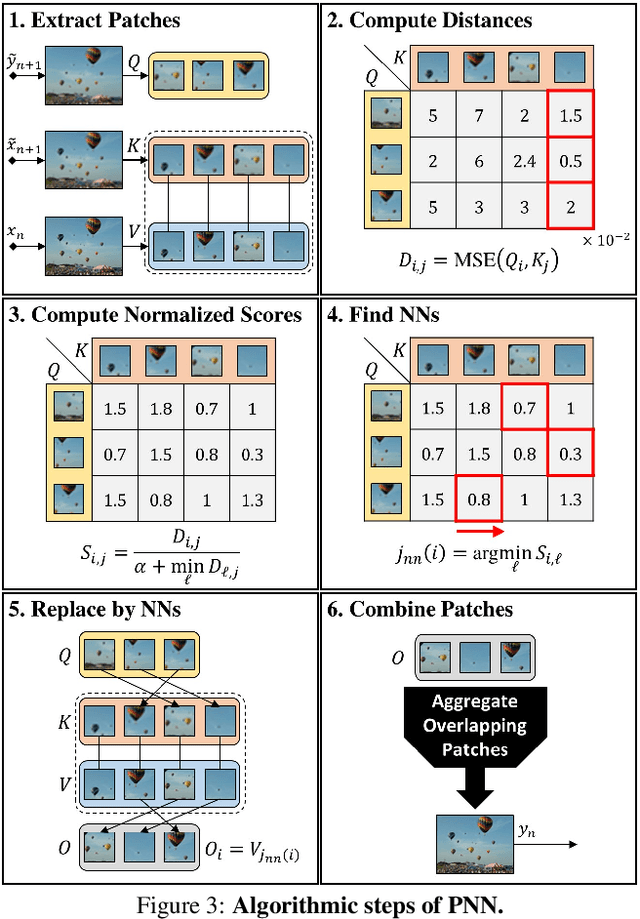

Single image generative models perform synthesis and manipulation tasks by capturing the distribution of patches within a single image. The classical (pre Deep Learning) prevailing approaches for these tasks are based on an optimization process that maximizes patch similarity between the input and generated output. Recently, however, Single Image GANs were introduced both as a superior solution for such manipulation tasks, but also for remarkable novel generative tasks. Despite their impressiveness, single image GANs require long training time (usually hours) for each image and each task. They often suffer from artifacts and are prone to optimization issues such as mode collapse. In this paper, we show that all of these tasks can be performed without any training, within several seconds, in a unified, surprisingly simple framework. We revisit and cast the "good-old" patch-based methods into a novel optimization-free framework. We start with an initial coarse guess, and then simply refine the details coarse-to-fine using patch-nearest-neighbor search. This allows generating random novel images better and much faster than GANs. We further demonstrate a wide range of applications, such as image editing and reshuffling, retargeting to different sizes, structural analogies, image collage and a newly introduced task of conditional inpainting. Not only is our method faster ($\times 10^3$-$\times 10^4$ than a GAN), it produces superior results (confirmed by quantitative and qualitative evaluation), less artifacts and more realistic global structure than any of the previous approaches (whether GAN-based or classical patch-based).
From Discrete to Continuous Convolution Layers
Jun 19, 2020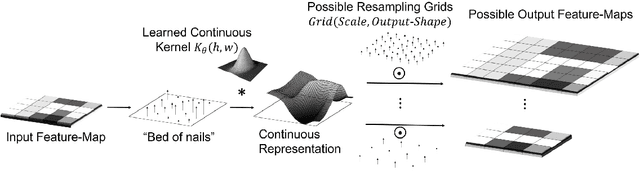
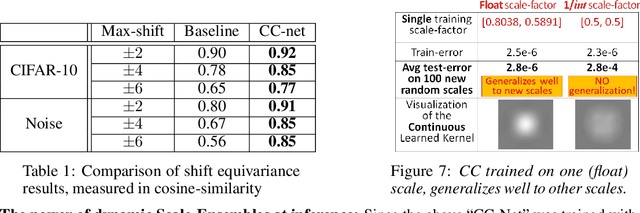
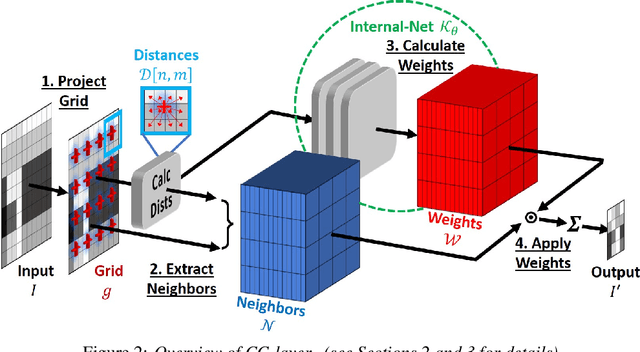

A basic operation in Convolutional Neural Networks (CNNs) is spatial resizing of feature maps. This is done either by strided convolution (donwscaling) or transposed convolution (upscaling). Such operations are limited to a fixed filter moving at predetermined integer steps (strides). Spatial sizes of consecutive layers are related by integer scale factors, predetermined at architectural design, and remain fixed throughout training and inference time. We propose a generalization of the common Conv-layer, from a discrete layer to a Continuous Convolution (CC) Layer. CC Layers naturally extend Conv-layers by representing the filter as a learned continuous function over sub-pixel coordinates. This allows learnable and principled resizing of feature maps, to any size, dynamically and consistently across scales. Once trained, the CC layer can be used to output any scale/size chosen at inference time. The scale can be non-integer and differ between the axes. CC gives rise to new freedoms for architectural design, such as dynamic layer shapes at inference time, or gradual architectures where the size changes by a small factor at each layer. This gives rise to many desired CNN properties, new architectural design capabilities, and useful applications. We further show that current Conv-layers suffer from inherent misalignments, which are ameliorated by CC layers.
Semantic Pyramid for Image Generation
Mar 16, 2020

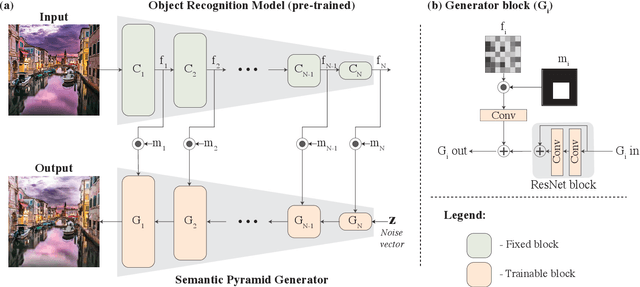
We present a novel GAN-based model that utilizes the space of deep features learned by a pre-trained classification model. Inspired by classical image pyramid representations, we construct our model as a Semantic Generation Pyramid -- a hierarchical framework which leverages the continuum of semantic information encapsulated in such deep features; this ranges from low level information contained in fine features to high level, semantic information contained in deeper features. More specifically, given a set of features extracted from a reference image, our model generates diverse image samples, each with matching features at each semantic level of the classification model. We demonstrate that our model results in a versatile and flexible framework that can be used in various classic and novel image generation tasks. These include: generating images with a controllable extent of semantic similarity to a reference image, and different manipulation tasks such as semantically-controlled inpainting and compositing; all achieved with the same model, with no further training.
Blind Super-Resolution Kernel Estimation using an Internal-GAN
Oct 24, 2019
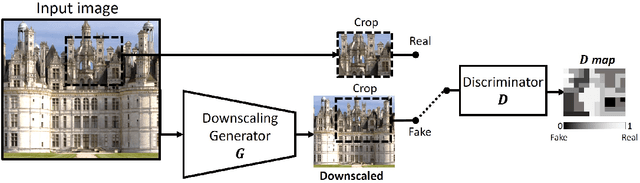
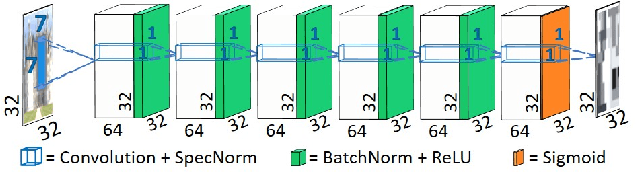
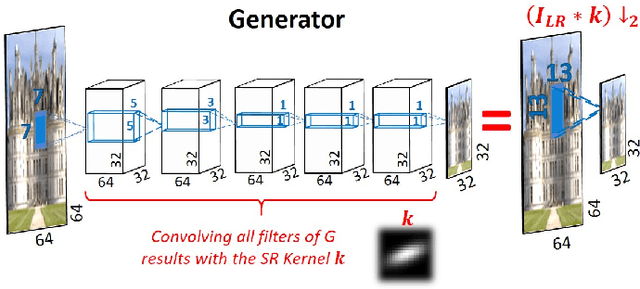
Super resolution (SR) methods typically assume that the low-resolution (LR) image was downscaled from the unknown high-resolution (HR) image by a fixed 'ideal' downscaling kernel (e.g. Bicubic downscaling). However, this is rarely the case in real LR images, in contrast to synthetically generated SR datasets. When the assumed downscaling kernel deviates from the true one, the performance of SR methods significantly deteriorates. This gave rise to Blind-SR - namely, SR when the downscaling kernel ("SR-kernel") is unknown. It was further shown that the true SR-kernel is the one that maximizes the recurrence of patches across scales of the LR image. In this paper we show how this powerful cross-scale recurrence property can be realized using Deep Internal Learning. We introduce "KernelGAN", an image-specific Internal-GAN, which trains solely on the LR test image at test time, and learns its internal distribution of patches. Its Generator is trained to produce a downscaled version of the LR test image, such that its Discriminator cannot distinguish between the patch distribution of the downscaled image, and the patch distribution of the original LR image. The Generator, once trained, constitutes the downscaling operation with the correct image-specific SR-kernel. KernelGAN is fully unsupervised, requires no training data other than the input image itself, and leads to state-of-the-art results in Blind-SR when plugged into existing SR algorithms.
"Double-DIP": Unsupervised Image Decomposition via Coupled Deep-Image-Priors
Dec 05, 2018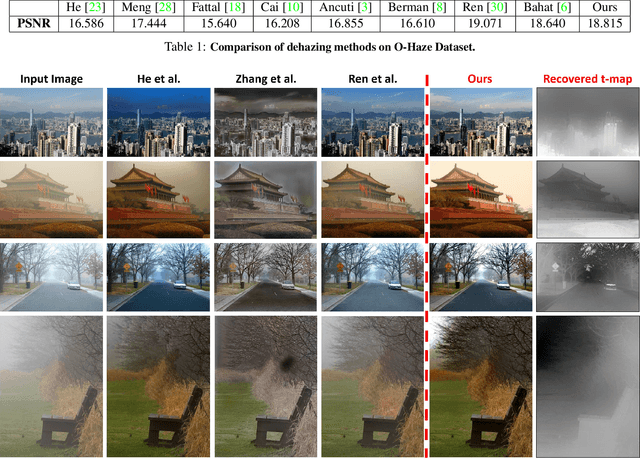
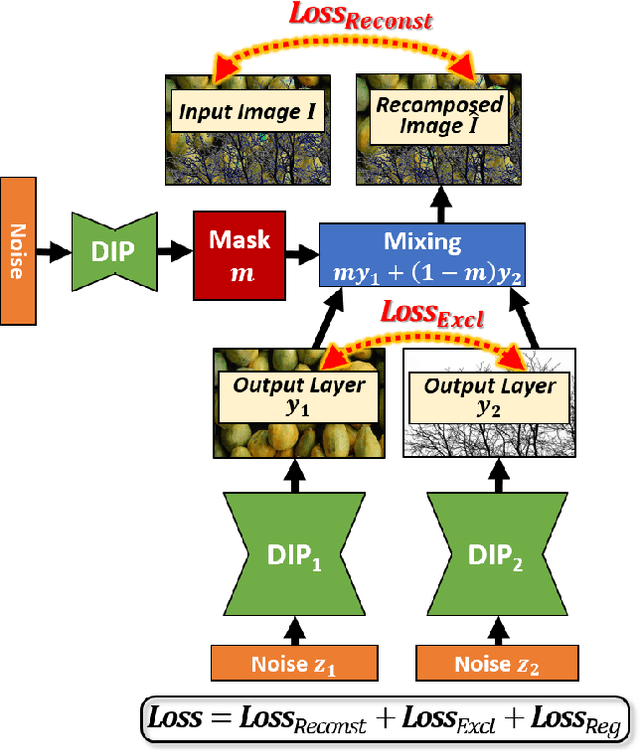
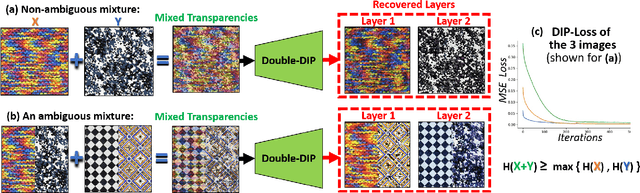

Many seemingly unrelated computer vision tasks can be viewed as a special case of image decomposition into separate layers. For example, image segmentation (separation into foreground and background layers); transparent layer separation (into reflection and transmission layers); Image dehazing (separation into a clear image and a haze map), and more. In this paper we propose a unified framework for unsupervised layer decomposition of a single image, based on coupled "Deep-image-Prior" (DIP) networks. It was shown [Ulyanov et al] that the structure of a single DIP generator network is sufficient to capture the low-level statistics of a single image. We show that coupling multiple such DIPs provides a powerful tool for decomposing images into their basic components, for a wide variety of applications. This capability stems from the fact that the internal statistics of a mixture of layers is more complex than the statistics of each of its individual components. We show the power of this approach for Image-Dehazing, Fg/Bg Segmentation, Watermark-Removal, Transparency Separation in images and video, and more. These capabilities are achieved in a totally unsupervised way, with no training examples other than the input image/video itself.
Internal Distribution Matching for Natural Image Retargeting
Dec 01, 2018
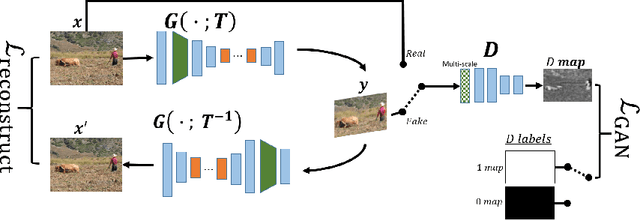
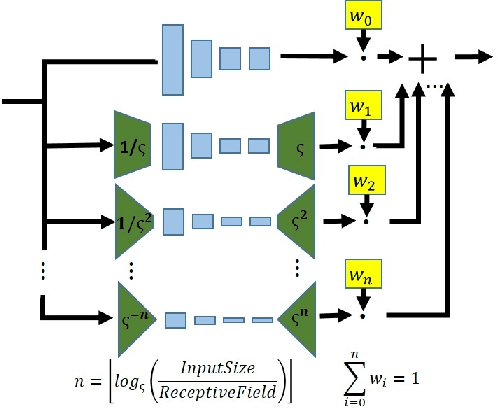
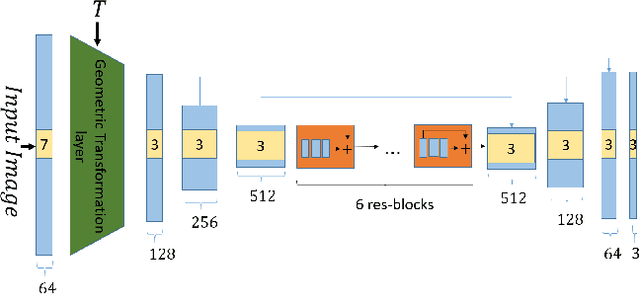
Good Visual Retargeting changes the global size and aspect ratio of a natural image, while preserving the size and aspect ratio of all its local elements. We propose formulating this principle by requiring that the distribution of patches in the input matches the distribution of patches in the output. We introduce a Deep-Learning approach for retargeting, based on an "Internal GAN" (InGAN). InGAN is an image-specific GAN. It incorporates the Internal statistics of a single natural image in a GAN. It is trained on a single input image and learns the distribution of its patches. It is then able to synthesize natural looking target images composed from the input image patch-distribution. InGAN is totally unsupervised, and requires no additional data other than the input image itself. Moreover, once trained on the input image, it can generate target images of any specified size or aspect ratio in real-time.
"Zero-Shot" Super-Resolution using Deep Internal Learning
Dec 17, 2017
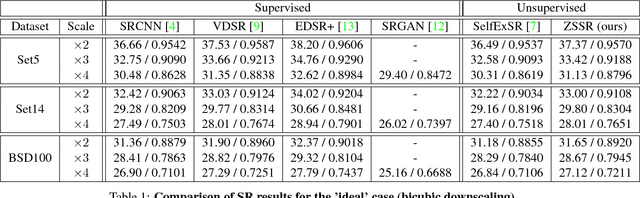

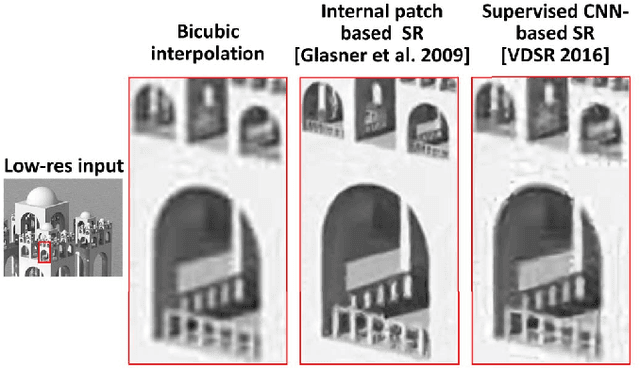
Deep Learning has led to a dramatic leap in Super-Resolution (SR) performance in the past few years. However, being supervised, these SR methods are restricted to specific training data, where the acquisition of the low-resolution (LR) images from their high-resolution (HR) counterparts is predetermined (e.g., bicubic downscaling), without any distracting artifacts (e.g., sensor noise, image compression, non-ideal PSF, etc). Real LR images, however, rarely obey these restrictions, resulting in poor SR results by SotA (State of the Art) methods. In this paper we introduce "Zero-Shot" SR, which exploits the power of Deep Learning, but does not rely on prior training. We exploit the internal recurrence of information inside a single image, and train a small image-specific CNN at test time, on examples extracted solely from the input image itself. As such, it can adapt itself to different settings per image. This allows to perform SR of real old photos, noisy images, biological data, and other images where the acquisition process is unknown or non-ideal. On such images, our method outperforms SotA CNN-based SR methods, as well as previous unsupervised SR methods. To the best of our knowledge, this is the first unsupervised CNN-based SR method.