 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-Guided Query-Aware Inference System for GNN Models on Large Knowledge Graphs
Mar 04, 2026Efficient inference for graph neural networks (GNNs) on large knowledge graphs (KGs) is essential for many real-world applications. GNN inference queries are computationally expensive and vary in complexity, as each involves a different number of target nodes linked to subgraphs of diverse densities and structures. Existing acceleration methods, such as pruning, quantization, and knowledge distillation, instantiate smaller models but do not adapt them to the structure or semantics of individual queries. They also store models as monolithic files that must be fully loaded, and miss the opportunity to retrieve only the neighboring nodes and corresponding model components that are semantically relevant to the target nodes. These limitations lead to excessive data loading and redundant computation on large KGs. This paper presents KG-WISE, a task-driven inference paradigm for large KGs. KG-WISE decomposes trained GNN models into fine-grained components that can be partially loaded based on the structure of the queried subgraph. It employs large language models (LLMs) to generate reusable query templates that extract semantically relevant subgraphs for each task, enabling query-aware and compact model instantiation. We evaluate KG-WISE on six large KGs with up to 42 million nodes and 166 million edges. KG-WISE achieves up to 28x faster inference and 98% lower memory usage than state-of-the-art systems while maintaining or improving accuracy across both commercial and open-weight LLMs.
gHAWK: Local and Global Structure Encoding for Scalable Training of Graph Neural Networks on Knowledge Graphs
Dec 09, 2025



Knowledge Graphs (KGs) are a rich source of structured, heterogeneous data, powering a wide range of applications. A common approach to leverage this data is to train a graph neural network (GNN) on the KG. However, existing message-passing GNNs struggle to scale to large KGs because they rely on the iterative message passing process to learn the graph structure, which is inefficient, especially under mini-batch training, where a node sees only a partial view of its neighborhood. In this paper, we address this problem and present gHAWK, a novel and scalable GNN training framework for large KGs. The key idea is to precompute structural features for each node that capture its local and global structure before GNN training even begins. Specifically, gHAWK introduces a preprocessing step that computes: (a)~Bloom filters to compactly encode local neighborhood structure, and (b)~TransE embeddings to represent each node's global position in the graph. These features are then fused with any domain-specific features (e.g., text embeddings), producing a node feature vector that can be incorporated into any GNN technique. By augmenting message-passing training with structural priors, gHAWK significantly reduces memory usage, accelerates convergence, and improves model accuracy. Extensive experiments on large datasets from the Open Graph Benchmark (OGB) demonstrate that gHAWK achieves state-of-the-art accuracy and lower training time on both node property prediction and link prediction tasks, topping the OGB leaderboard for three graphs.
RDFFrames: Knowledge Graph Access for Machine Learning Tools
Feb 10, 2020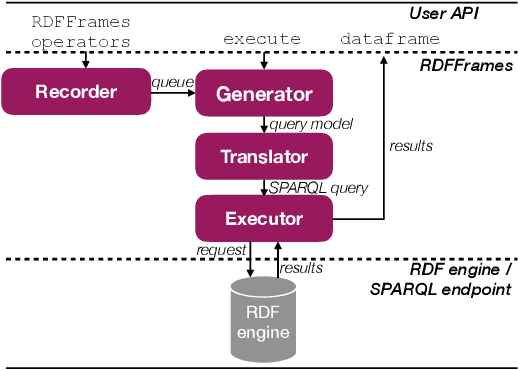
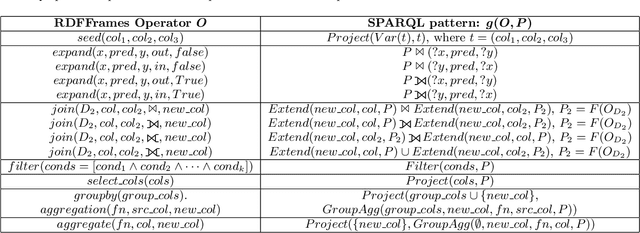
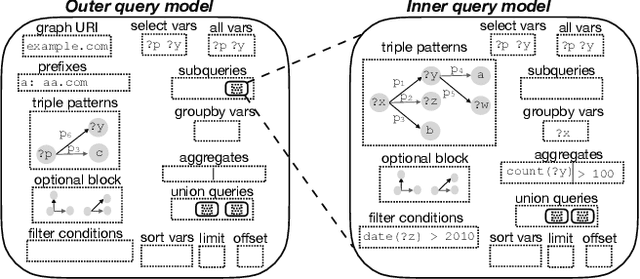
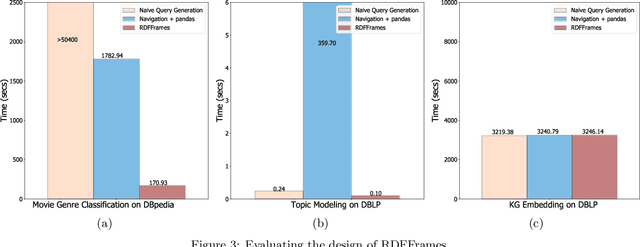
Knowledge graphs represented as RDF datasets are becoming increasingly popular, and they are an integral part of many machine learning applications. A rich ecosystem of data management systems and tools that support RDF has evolved over the years to facilitate high performance storage and retrieval of RDF data, most notably RDF database management systems that support the SPARQL query language. Surprisingly, machine learning tools for knowledge graphs typically do not use SPARQL, despite the obvious advantages of using a database system. This is due to the mismatch between SPARQL and machine learning tools in terms of the expected data model and the programming style. Machine learning tools work on data in tabular format and process it using an imperative programming style, while SPARQL is declarative and has as the basic query operation matching graph patterns to RDF triples. We posit that a good interface to knowledge graphs from a machine learning software stack should use an imperative, navigational programming paradigm based on graph traversal rather than the SPARQL query paradigm based on graph patterns. In this paper, we introduce RDFFrames, a framework that provides such an interface. RDFFrames enables the user to make a sequence of calls in a programming language such as Python to define the data to be extracted from a knowledge graph stored in an RDF database system. It then translates these calls into compact SPQARL queries, executes these queries on the database system, and returns the results in a standard tabular format. Thus, RDFframes combines the usability of a machine learning software stack with the performance of an RDF database system.
Link Prediction via Higher-Order Motif Features
Feb 08, 2019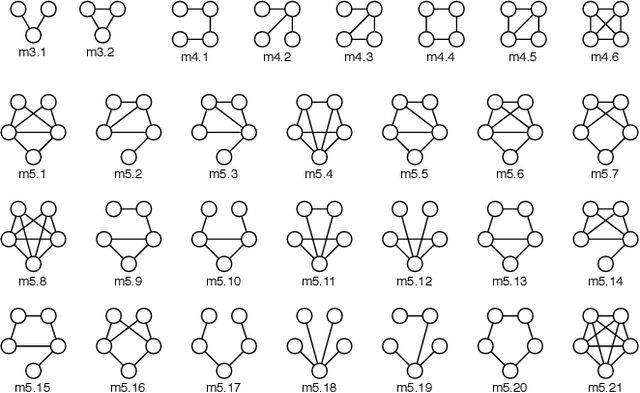
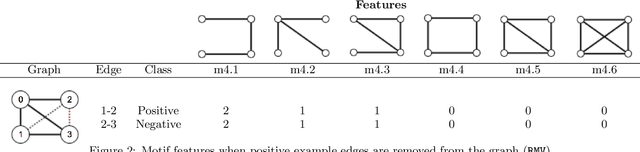

Link prediction requires predicting which new links are likely to appear in a graph. Being able to predict unseen links with good accuracy has important applications in several domains such as social media, security, transportation, and recommendation systems. A common approach is to use features based on the common neighbors of an unconnected pair of nodes to predict whether the pair will form a link in the future. In this paper, we present an approach for link prediction that relies on higher-order analysis of the graph topology, well beyond common neighbors. We treat the link prediction problem as a supervised classification problem, and we propose a set of features that depend on the patterns or motifs that a pair of nodes occurs in. By using motifs of sizes 3, 4, and 5, our approach captures a high level of detail about the graph topology within the neighborhood of the pair of nodes, which leads to a higher classification accuracy. In addition to proposing the use of motif-based features, we also propose two optimizations related to constructing the classification dataset from the graph. First, to ensure that positive and negative examples are treated equally when extracting features, we propose adding the negative examples to the graph as an alternative to the common approach of removing the positive ones. Second, we show that it is important to control for the shortest-path distance when sampling pairs of nodes to form negative examples, since the difficulty of prediction varies with the shortest-path distance. We experimentally demonstrate that using off-the-shelf classifiers with a well constructed classification dataset results in up to 10 percentage points increase in accuracy over prior topology-based and feature learning methods.