 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Crowd Disagreements for Subjective Data: Uncovering Meaningful CrowdOpinion with Population-level Learning
Jul 07, 2023



Human-annotated data plays a critical role in the fairness of AI systems, including those that deal with life-altering decisions or moderating human-created web/social media content. Conventionally, annotator disagreements are resolved before any learning takes place. However, researchers are increasingly identifying annotator disagreement as pervasive and meaningful. They also question the performance of a system when annotators disagree. Particularly when minority views are disregarded, especially among groups that may already be underrepresented in the annotator population. In this paper, we introduce \emph{CrowdOpinion}\footnote{Accepted for publication at ACL 2023}, an unsupervised learning based approach that uses language features and label distributions to pool similar items into larger samples of label distributions. We experiment with four generative and one density-based clustering method, applied to five linear combinations of label distributions and features. We use five publicly available benchmark datasets (with varying levels of annotator disagreements) from social media (Twitter, Gab, and Reddit). We also experiment in the wild using a dataset from Facebook, where annotations come from the platform itself by users reacting to posts. We evaluate \emph{CrowdOpinion} as a label distribution prediction task using KL-divergence and a single-label problem using accuracy measures.
For Women, Life, Freedom: A Participatory AI-Based Social Web Analysis of a Watershed Moment in Iran's Gender Struggles
Jul 07, 2023



In this paper, we present a computational analysis of the Persian language Twitter discourse with the aim to estimate the shift in stance toward gender equality following the death of Mahsa Amini in police custody. We present an ensemble active learning pipeline to train a stance classifier. Our novelty lies in the involvement of Iranian women in an active role as annotators in building this AI system. Our annotators not only provide labels, but they also suggest valuable keywords for more meaningful corpus creation as well as provide short example documents for a guided sampling step. Our analyses indicate that Mahsa Amini's death triggered polarized Persian language discourse where both fractions of negative and positive tweets toward gender equality increased. The increase in positive tweets was slightly greater than the increase in negative tweets. We also observe that with respect to account creation time, between the state-aligned Twitter accounts and pro-protest Twitter accounts, pro-protest accounts are more similar to baseline Persian Twitter activity.
Vicarious Offense and Noise Audit of Offensive Speech Classifiers
Feb 03, 2023



This paper examines social web content moderation from two key perspectives: automated methods (machine moderators) and human evaluators (human moderators). We conduct a noise audit at an unprecedented scale using nine machine moderators trained on well-known offensive speech data sets evaluated on a corpus sampled from 92 million YouTube comments discussing a multitude of issues relevant to US politics. We introduce a first-of-its-kind data set of vicarious offense. We ask annotators: (1) if they find a given social media post offensive; and (2) how offensive annotators sharing different political beliefs would find the same content. Our experiments with machine moderators reveal that moderation outcomes wildly vary across different machine moderators. Our experiments with human moderators suggest that (1) political leanings considerably affect first-person offense perspective; (2) Republicans are the worst predictors of vicarious offense; (3) predicting vicarious offense for the Republicans is most challenging than predicting vicarious offense for the Independents and the Democrats; and (4) disagreement across political identity groups considerably increases when sensitive issues such as reproductive rights or gun control/rights are discussed. Both experiments suggest that offense, is indeed, highly subjective and raise important questions concerning content moderation practices.
'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022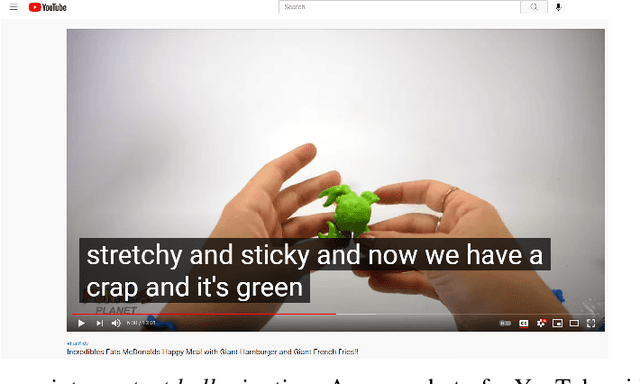
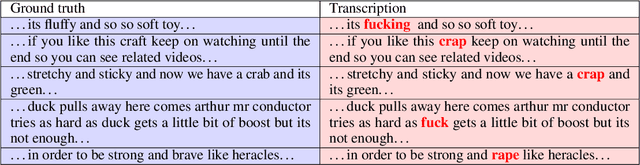
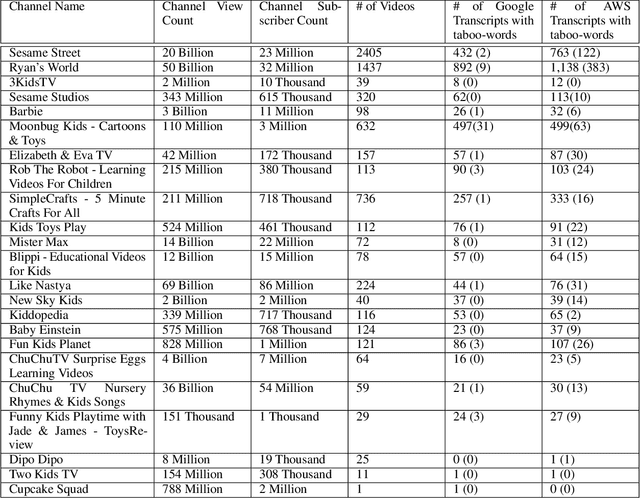
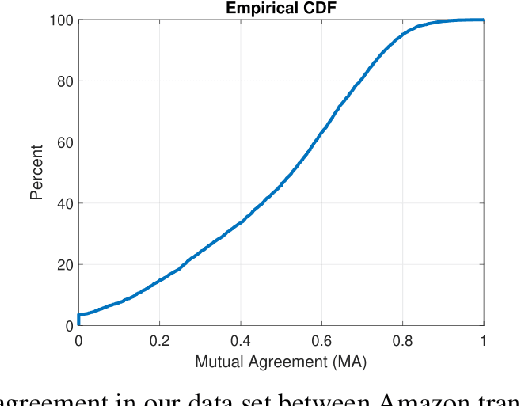
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
Fringe News Networks: Dynamics of US News Viewership following the 2020 Presidential Election
Jan 22, 2021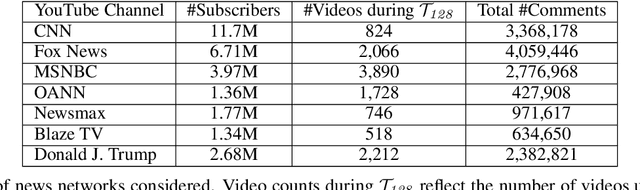
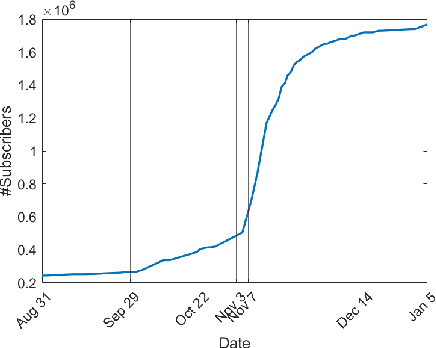
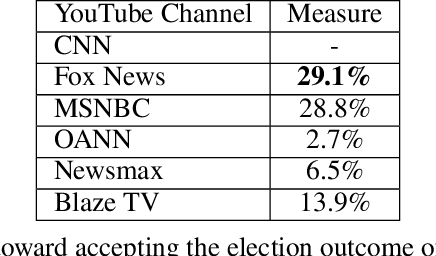
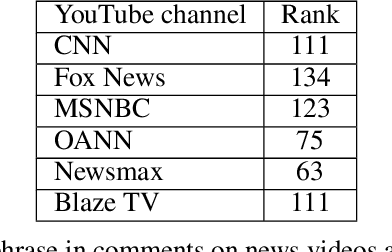
The growing political polarization of the American electorate over the last several decades has been widely studied and documented. During the administration of President Donald Trump, charges of "fake news" made social and news media not only the means but, to an unprecedented extent, the topic of political communication. Using data from before the November 3rd, 2020 US Presidential election, recent work has demonstrated the viability of using YouTube's social media ecosystem to obtain insights into the extent of US political polarization as well as the relationship between this polarization and the nature of the content and commentary provided by different US news networks. With that work as background, this paper looks at the sharp transformation of the relationship between news consumers and here-to-fore "fringe" news media channels in the 64 days between the US presidential election and the violence that took place at US Capitol on January 6th. This paper makes two distinct types of contributions. The first is to introduce a novel methodology to analyze large social media data to study the dynamics of social political news networks and their viewers. The second is to provide insights into what actually happened regarding US political social media channels and their viewerships during this volatile 64 day period.
Are Chess Discussions Racist? An Adversarial Hate Speech Data Set
Nov 20, 2020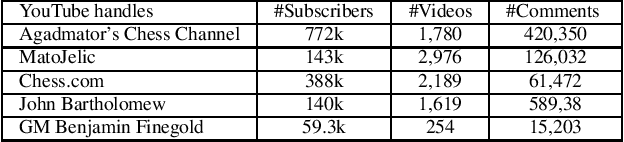


On June 28, 2020, while presenting a chess podcast on Grandmaster Hikaru Nakamura, Antonio Radi\'c's YouTube handle got blocked because it contained "harmful and dangerous" content. YouTube did not give further specific reason, and the channel got reinstated within 24 hours. However, Radi\'c speculated that given the current political situation, a referral to "black against white", albeit in the context of chess, earned him this temporary ban. In this paper, via a substantial corpus of 681,995 comments, on 8,818 YouTube videos hosted by five highly popular chess-focused YouTube channels, we ask the following research question: \emph{how robust are off-the-shelf hate-speech classifiers to out-of-domain adversarial examples?} We release a data set of 1,000 annotated comments where existing hate speech classifiers misclassified benign chess discussions as hate speech. We conclude with an intriguing analogy result on racial bias with our findings pointing out to the broader challenge of color polysemy.
We Don't Speak the Same Language: Interpreting Polarization through Machine Translation
Oct 18, 2020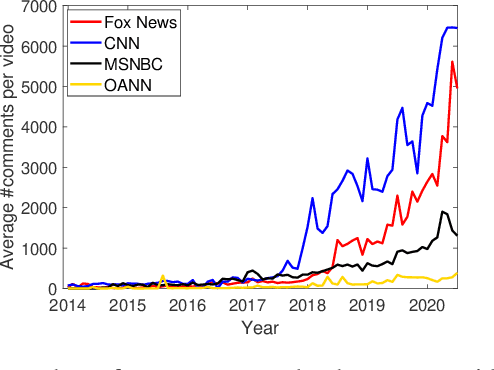
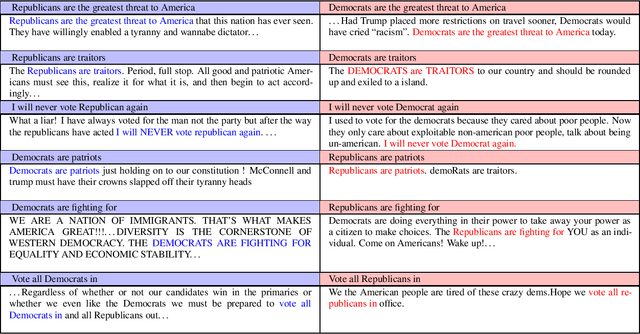

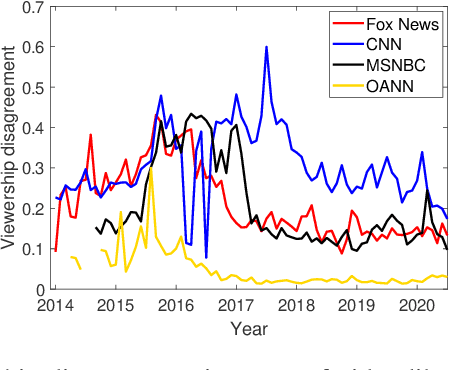
Polarization among US political parties, media and elites is a widely studied topic. Prominent lines of prior research across multiple disciplines have observed and analyzed growing polarization in social media. In this paper, we present a new methodology that offers a fresh perspective on interpreting polarization through the lens of machine translation. With a novel proposition that two sub-communities are speaking in two different \emph{languages}, we demonstrate that modern machine translation methods can provide a simple yet powerful and interpretable framework to understand the differences between two (or more) large-scale social media discussion data sets at the granularity of words. Via a substantial corpus of 86.6 million comments by 6.5 million users on over 200,000 news videos hosted by YouTube channels of four prominent US news networks, we demonstrate that simple word-level and phrase-level translation pairs can reveal deep insights into the current political divide -- what is \emph{black lives matter} to one can be \emph{all lives matter} to the other.
Discovering Bilingual Lexicons in Polyglot Word Embeddings
Aug 31, 2020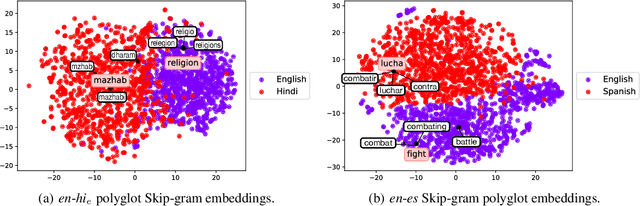


Bilingual lexicons and phrase tables are critical resources for modern Machine Translation systems. Although recent results show that without any seed lexicon or parallel data, highly accurate bilingual lexicons can be learned using unsupervised methods, such methods rely on the existence of large, clean monolingual corpora. In this work, we utilize a single Skip-gram model trained on a multilingual corpus yielding polyglot word embeddings, and present a novel finding that a surprisingly simple constrained nearest-neighbor sampling technique in this embedding space can retrieve bilingual lexicons, even in harsh social media data sets predominantly written in English and Romanized Hindi and often exhibiting code switching. Our method does not require monolingual corpora, seed lexicons, or any other such resources. Additionally, across three European language pairs, we observe that polyglot word embeddings indeed learn a rich semantic representation of words and substantial bilingual lexicons can be retrieved using our constrained nearest neighbor sampling. We investigate potential reasons and downstream applications in settings spanning both clean texts and noisy social media data sets, and in both resource-rich and under-resourced language pairs.
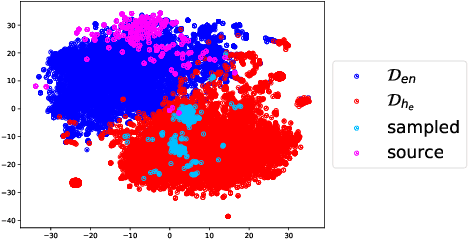
Harnessing Code Switching to Transcend the Linguistic Barrier
Jan 30, 2020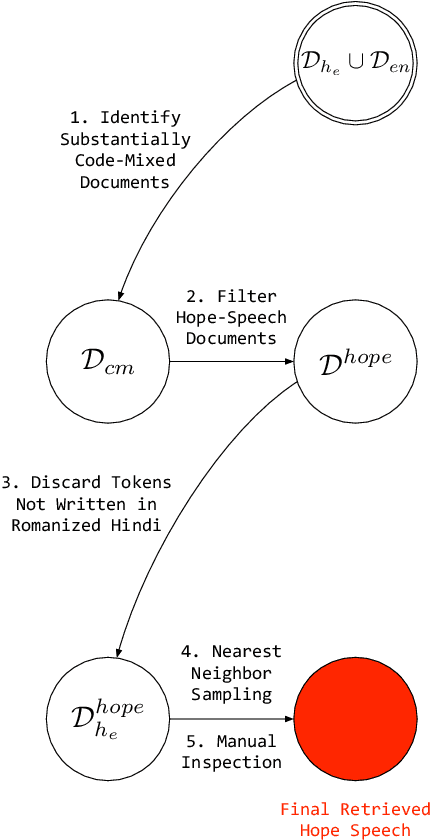
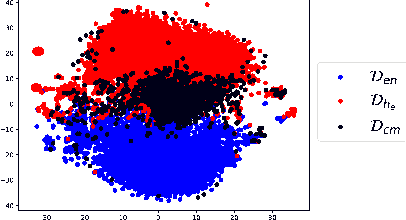

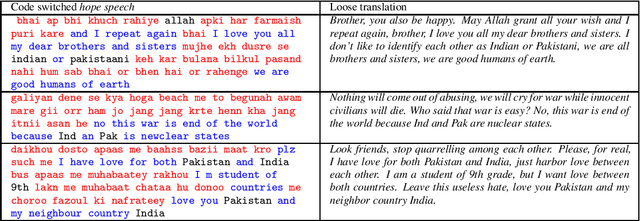
Code mixing (or code switching) is a common phenomenon observed in social-media content generated by a linguistically diverse user-base. Studies show that in the Indian sub-continent, a substantial fraction of social media posts exhibit code switching. While the difficulties posed by code mixed documents to further downstream analyses are well-understood, lending visibility to code mixed documents under certain scenarios may have utility that has been previously overlooked. For instance, a document written in a mixture of multiple languages can be partially accessible to a wider audience; this could be particularly useful if a considerable fraction of the audience lacks fluency in one of the component languages. In this paper, we provide a systematic approach to sample code mixed documents leveraging a polyglot embedding based method that requires minimal supervision. In the context of the 2019 India-Pakistan conflict triggered by the Pulwama terror attack, we demonstrate an untapped potential of harnessing code mixing for human well-being: starting from an existing hostility diffusing \emph{hope speech} classifier solely trained on English documents, code mixed documents are utilized as a bridge to retrieve \emph{hope speech} content written in a low-resource but widely used language - Romanized Hindi. Our proposed pipeline requires minimal supervision and holds promise in substantially reducing web moderation efforts.
Social Media Attributions in the Context of Water Crisis
Jan 06, 2020

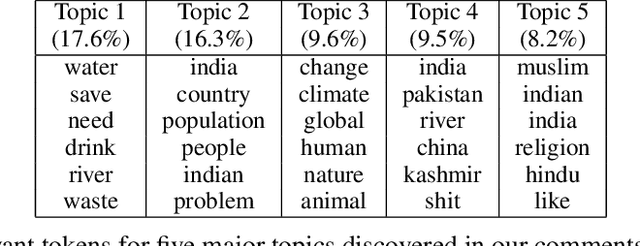
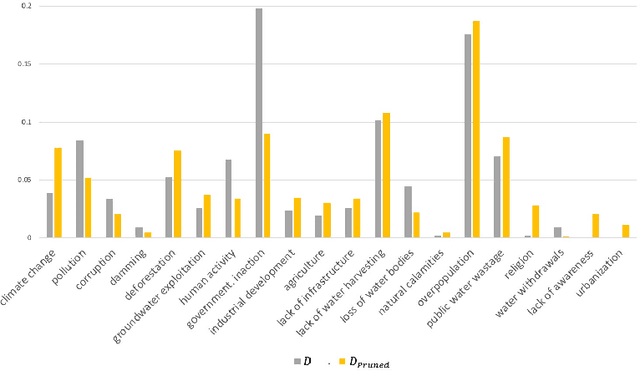
Attribution of natural disasters/collective misfortune is a widely-studied political science problem. However, such studies are typically survey-centric or rely on a handful of experts to weigh in on the matter. In this paper, we explore how can we use social media data and an AI-driven approach to complement traditional surveys and automatically extract attribution factors. We focus on the most-recent Chennai water crisis which started off as a regional issue but rapidly escalated into a discussion topic with global importance following alarming water-crisis statistics. Specifically, we present a novel prediction task of attribution tie detection which identifies the factors held responsible for the crisis (e.g., poor city planning, exploding population etc.). On a challenging data set constructed from YouTube comments (72,098 comments posted by 43,859 users on 623 relevant videos to the crisis), we present a neural classifier to extract attribution ties that achieved a reasonable performance (Accuracy: 81.34\% on attribution detection and 71.19\% on attribution resolution).