 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning in Large Language Models
May 24, 2024



Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75\% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) \citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset \citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) \citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models \citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
Zero Shot Context-Based Object Segmentation using SLIP (SAM+CLIP)
May 12, 2024We present SLIP (SAM+CLIP), an enhanced architecture for zero-shot object segmentation. SLIP combines the Segment Anything Model (SAM) \cite{kirillov2023segment} with the Contrastive Language-Image Pretraining (CLIP) \cite{radford2021learning}. By incorporating text prompts into SAM using CLIP, SLIP enables object segmentation without prior training on specific classes or categories. We fine-tune CLIP on a Pokemon dataset, allowing it to learn meaningful image-text representations. SLIP demonstrates the ability to recognize and segment objects in images based on contextual information from text prompts, expanding the capabilities of SAM for versatile object segmentation. Our experiments demonstrate the effectiveness of the SLIP architecture in segmenting objects in images based on textual cues. The integration of CLIP's text-image understanding capabilities into SAM expands the capabilities of the original architecture and enables more versatile and context-aware object segmentation.
DeepGamble: Towards unlocking real-time player intelligence using multi-layer instance segmentation and attribute detection
Dec 14, 2020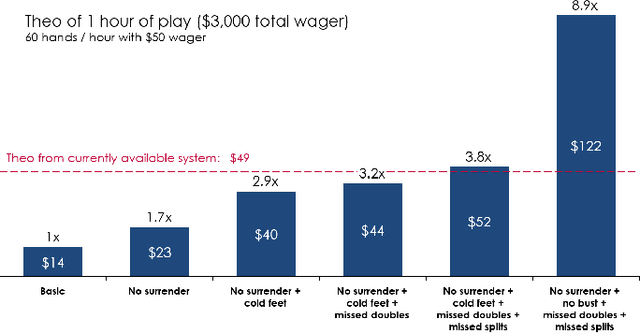
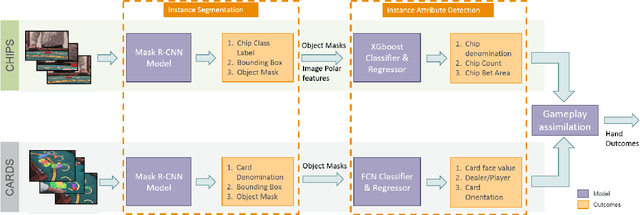
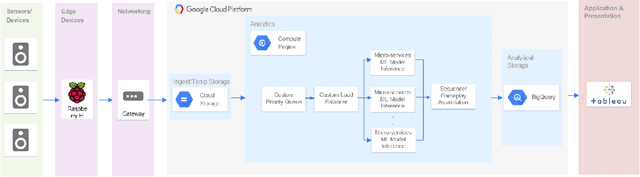

Annually the gaming industry spends approximately $15 billion in marketing reinvestment. However, this amount is spent without any consideration for the skill and luck of the player. For a casino, an unskilled player could fetch ~4 times more revenue than a skilled player. This paper describes a video recognition system that is based on an extension of the Mask R-CNN model. Our system digitizes the game of blackjack by detecting cards and player bets in real-time and processes decisions they took in order to create accurate player personas. Our proposed supervised learning approach consists of a specialized three-stage pipeline that takes images from two viewpoints of the casino table and does instance segmentation to generate masks on proposed regions of interest. These predicted masks along with derivative features are used to classify image attributes that are passed onto the next stage to assimilate the gameplay understanding. Our end-to-end model yields an accuracy of ~95% for the main bet detection and ~97% for card detection in a controlled environment trained using transfer learning approach with 900 training examples. Our approach is generalizable and scalable and shows promising results in varied gaming scenarios and test data. Such granular level gathered data, helped in understanding player's deviation from optimum strategy and thereby separate the skill of the player from the luck of the game. Our system also assesses the likelihood of card counting by correlating the player's betting pattern to the deck's scaled count. Such a system lets casinos flag fraudulent activity and calculate expected personalized profitability for each player and tailor their marketing reinvestment decisions.