Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Convolutional Representations for On-Device Natural Language Processing
Feb 04, 2020
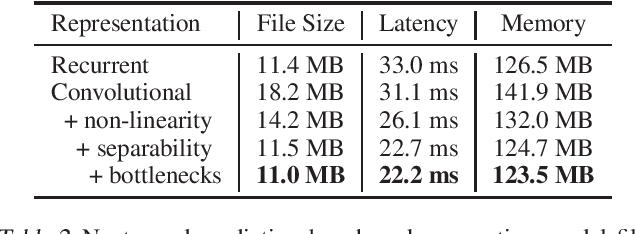
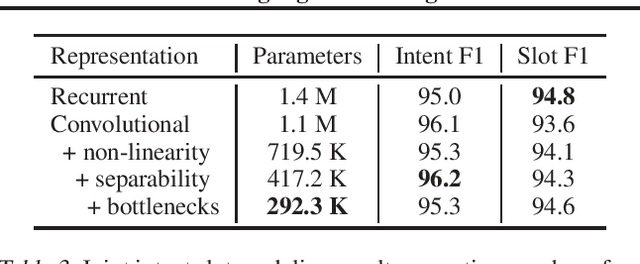
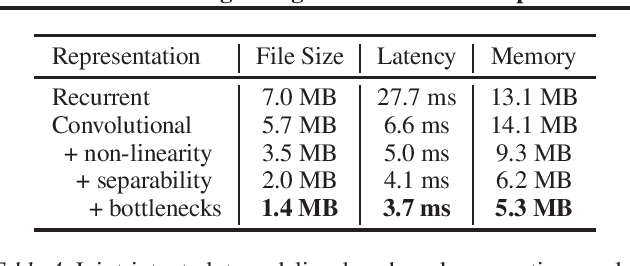
The increasing computational and memory complexities of deep neural networks have made it difficult to deploy them on low-resource electronic devices (e.g., mobile phones, tablets, wearables). Practitioners have developed numerous model compression methods to address these concerns, but few have condensed input representations themselves. In this work, we propose a fast, accurate, and lightweight convolutional representation that can be swapped into any neural model and compressed significantly (up to 32x) with a negligible reduction in performance. In addition, we show gains over recurrent representations when considering resource-centric metrics (e.g., model file size, latency, memory usage) on a Samsung Galaxy S9.
* Accepted to MLSys 2020
Via