 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Quantization
Jun 05, 2016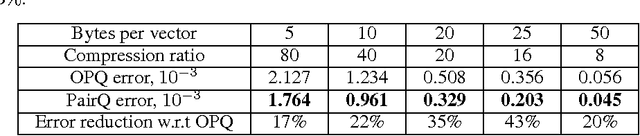
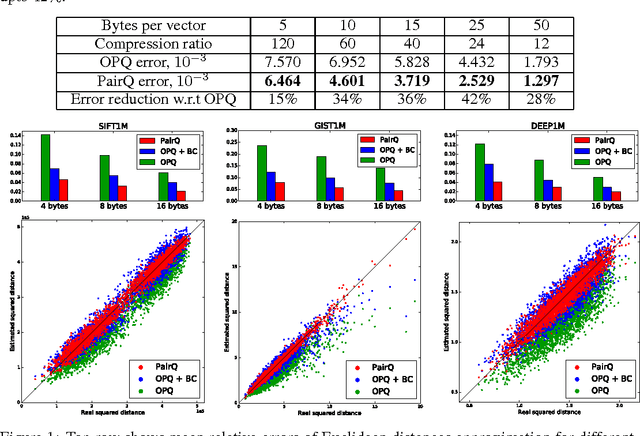
We consider the task of lossy compression of high-dimensional vectors through quantization. We propose the approach that learns quantization parameters by minimizing the distortion of scalar products and squared distances between pairs of points. This is in contrast to previous works that obtain these parameters through the minimization of the reconstruction error of individual points. The proposed approach proceeds by finding a linear transformation of the data that effectively reduces the minimization of the pairwise distortions to the minimization of individual reconstruction errors. After such transformation, any of the previously-proposed quantization approaches can be used. Despite the simplicity of this transformation, the experiments demonstrate that it achieves considerable reduction of the pairwise distortions compared to applying quantization directly to the untransformed data.
Aggregating Deep Convolutional Features for Image Retrieval
Oct 26, 2015
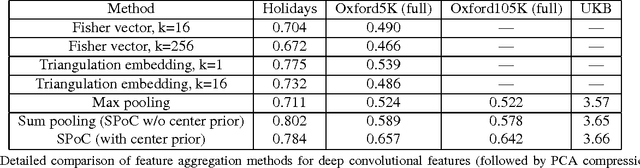
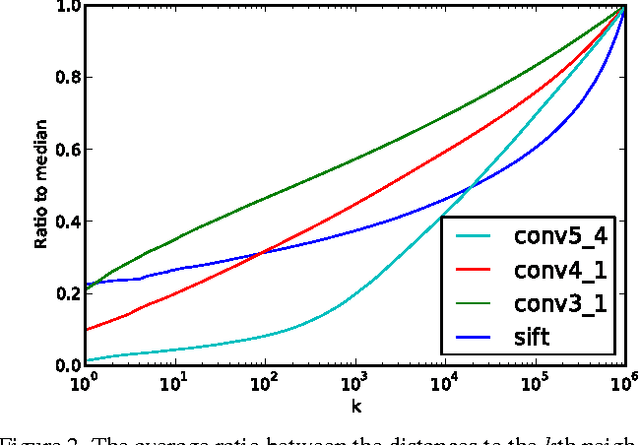
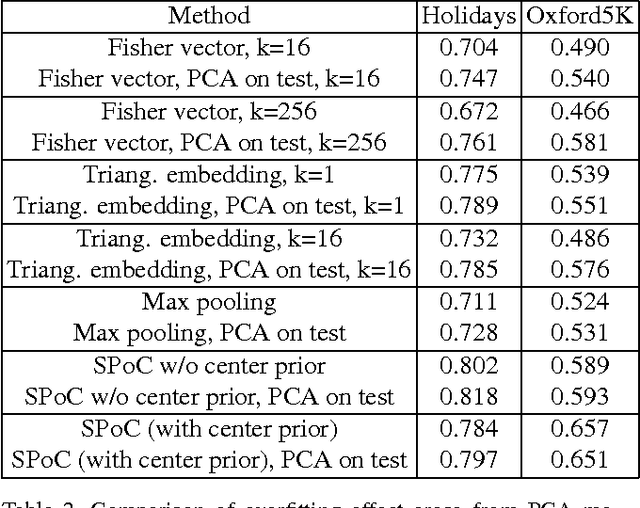
Several recent works have shown that image descriptors produced by deep convolutional neural networks provide state-of-the-art performance for image classification and retrieval problems. It has also been shown that the activations from the convolutional layers can be interpreted as local features describing particular image regions. These local features can be aggregated using aggregation approaches developed for local features (e.g. Fisher vectors), thus providing new powerful global descriptors. In this paper we investigate possible ways to aggregate local deep features to produce compact global descriptors for image retrieval. First, we show that deep features and traditional hand-engineered features have quite different distributions of pairwise similarities, hence existing aggregation methods have to be carefully re-evaluated. Such re-evaluation reveals that in contrast to shallow features, the simple aggregation method based on sum pooling provides arguably the best performance for deep convolutional features. This method is efficient, has few parameters, and bears little risk of overfitting when e.g. learning the PCA matrix. Overall, the new compact global descriptor improves the state-of-the-art on four common benchmarks considerably.
Neural Codes for Image Retrieval
Jul 07, 2014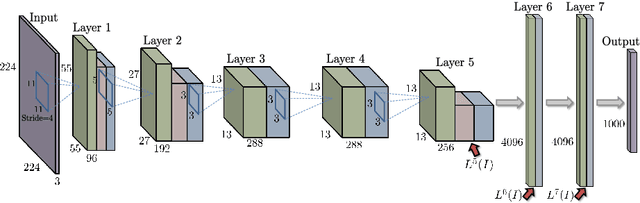
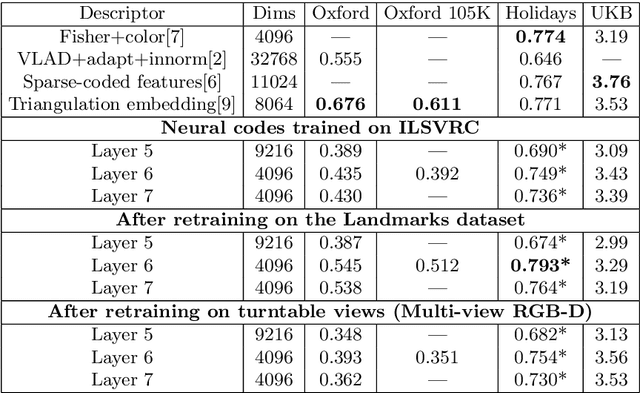

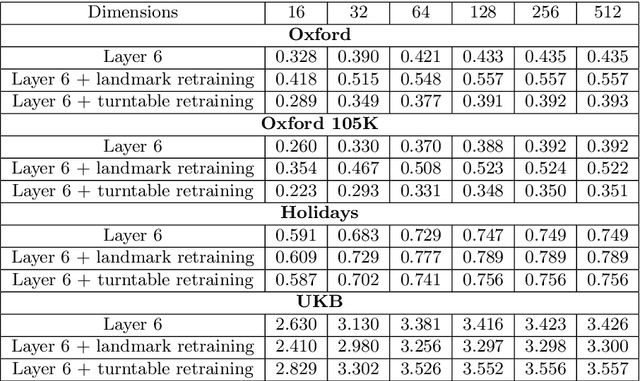
It has been shown that the activations invoked by an image within the top layers of a large convolutional neural network provide a high-level descriptor of the visual content of the image. In this paper, we investigate the use of such descriptors (neural codes) within the image retrieval application. In the experiments with several standard retrieval benchmarks, we establish that neural codes perform competitively even when the convolutional neural network has been trained for an unrelated classification task (e.g.\ Image-Net). We also evaluate the improvement in the retrieval performance of neural codes, when the network is retrained on a dataset of images that are similar to images encountered at test time. We further evaluate the performance of the compressed neural codes and show that a simple PCA compression provides very good short codes that give state-of-the-art accuracy on a number of datasets. In general, neural codes turn out to be much more resilient to such compression in comparison other state-of-the-art descriptors. Finally, we show that discriminative dimensionality reduction trained on a dataset of pairs of matched photographs improves the performance of PCA-compressed neural codes even further. Overall, our quantitative experiments demonstrate the promise of neural codes as visual descriptors for image retrieval.
Improving Bilayer Product Quantization for Billion-Scale Approximate Nearest Neighbors in High Dimensions
Apr 07, 2014
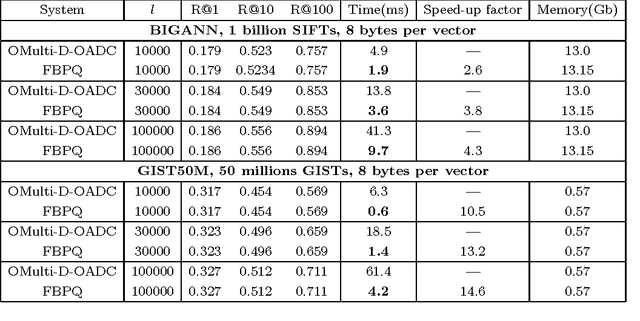
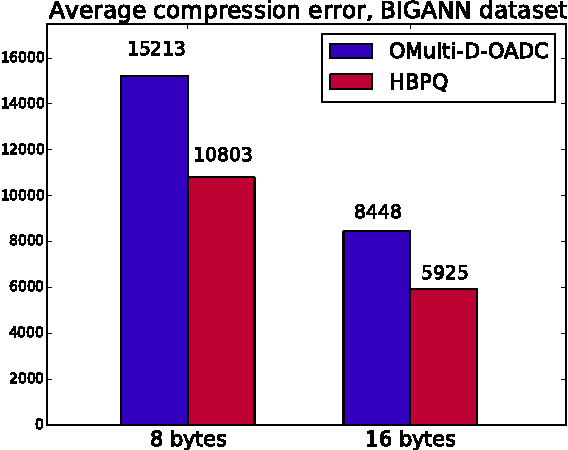
The top-performing systems for billion-scale high-dimensional approximate nearest neighbor (ANN) search are all based on two-layer architectures that include an indexing structure and a compressed datapoints layer. An indexing structure is crucial as it allows to avoid exhaustive search, while the lossy data compression is needed to fit the dataset into RAM. Several of the most successful systems use product quantization (PQ) for both the indexing and the dataset compression layers. These systems are however limited in the way they exploit the interaction of product quantization processes that happen at different stages of these systems. Here we introduce and evaluate two approximate nearest neighbor search systems that both exploit the synergy of product quantization processes in a more efficient way. The first system, called Fast Bilayer Product Quantization (FBPQ), speeds up the runtime of the baseline system (Multi-D-ADC) by several times, while achieving the same accuracy. The second system, Hierarchical Bilayer Product Quantization (HBPQ) provides a significantly better recall for the same runtime at a cost of small memory footprint increase. For the BIGANN dataset of billion SIFT descriptors, the 10% increase in Recall@1 and the 17% increase in Recall@10 is observed.