 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Thematic Review of Prevention of Future Deaths Reports: Replicating the ONS Child Suicide Study using Large Language Models
Jul 28, 2025Prevention of Future Deaths (PFD) reports, issued by coroners in England and Wales, flag systemic hazards that may lead to further loss of life. Analysis of these reports has previously been constrained by the manual effort required to identify and code relevant cases. In 2025, the Office for National Statistics (ONS) published a national thematic review of child-suicide PFD reports ($\leq$ 18 years), identifying 37 cases from January 2015 to November 2023 - a process based entirely on manual curation and coding. We evaluated whether a fully automated, open source "text-to-table" language-model pipeline (PFD Toolkit) could reproduce the ONS's identification and thematic analysis of child-suicide PFD reports, and assessed gains in efficiency and reliability. All 4,249 PFD reports published from July 2013 to November 2023 were processed via PFD Toolkit's large language model pipelines. Automated screening identified cases where the coroner attributed death to suicide in individuals aged 18 or younger, and eligible reports were coded for recipient category and 23 concern sub-themes, replicating the ONS coding frame. PFD Toolkit identified 72 child-suicide PFD reports - almost twice the ONS count. Three blinded clinicians adjudicated a stratified sample of 144 reports to validate the child-suicide screening. Against the post-consensus clinical annotations, the LLM-based workflow showed substantial to almost-perfect agreement (Cohen's $\kappa$ = 0.82, 95% CI: 0.66-0.98, raw agreement = 91%). The end-to-end script runtime was 8m 16s, transforming a process that previously took months into one that can be completed in minutes. This demonstrates that automated LLM analysis can reliably and efficiently replicate manual thematic reviews of coronial data, enabling scalable, reproducible, and timely insights for public health and safety. The PFD Toolkit is openly available for future research.
Beyond the Buzz: A Pragmatic Take on Inference Disaggregation
Jun 05, 2025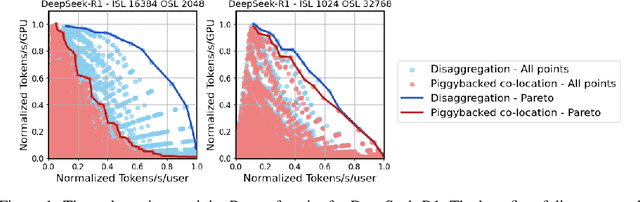

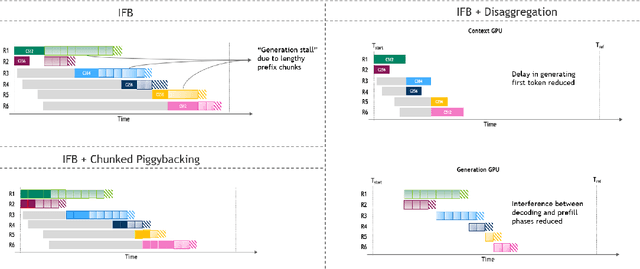
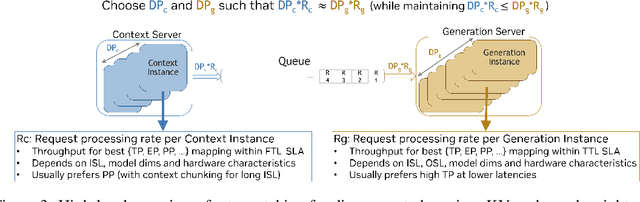
As inference scales to multi-node deployments, disaggregation - splitting inference into distinct phases - offers a promising path to improving the throughput-interactivity Pareto frontier. Despite growing enthusiasm and a surge of open-source efforts, practical deployment of disaggregated serving remains limited due to the complexity of the optimization search space and system-level coordination. In this paper, we present the first systematic study of disaggregated inference at scale, evaluating hundreds of thousands of design points across diverse workloads and hardware configurations. We find that disaggregation is most effective for prefill-heavy traffic patterns and larger models. Our results highlight the critical role of dynamic rate matching and elastic scaling in achieving Pareto-optimal performance. Our findings offer actionable insights for efficient disaggregated deployments to navigate the trade-off between system throughput and interactivity.