 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Advancements of the Forward-Forward Algorithm
Apr 30, 2025



The Forward-Forward algorithm has evolved in machine learning research, tackling more complex tasks that mimic real-life applications. In the last years, it has been improved by several techniques to perform better than its original version, handling a challenging dataset like CIFAR10 without losing its flexibility and low memory usage. We have shown in our results that improvements are achieved through a combination of convolutional channel grouping, learning rate schedules, and independent block structures during training that lead to a 20\% decrease in test error percentage. Additionally, to approach further implementations on low-capacity hardware projects we have presented a series of lighter models that achieve low test error percentages within (21$\pm$6)\% and number of trainable parameters between 164,706 and 754,386. This serving also as a basis for our future study on complete verification and validation of these kinds of neural networks.
Weight fluctuations in (deep) linear neural networks and a derivation of the inverse-variance flatness relation
Nov 23, 2023



We investigate the stationary (late-time) training regime of single- and two-layer linear neural networks within the continuum limit of stochastic gradient descent (SGD) for synthetic Gaussian data. In the case of a single-layer network in the weakly oversampled regime, the spectrum of the noise covariance matrix deviates notably from the Hessian, which can be attributed to the broken detailed balance of SGD dynamics. The weight fluctuations are in this case generally anisotropic, but experience an isotropic loss. For a two-layer network, we obtain the stochastic dynamics of the weights in each layer and analyze the associated stationary covariances. We identify the inter-layer coupling as a new source of anisotropy for the weight fluctuations. In contrast to the single-layer case, the weight fluctuations experience an anisotropic loss, the flatness of which is inversely related to the fluctuation variance. We thereby provide an analytical derivation of the recently observed inverse variance-flatness relation in a deep linear network model.
Deep Neural Networks for the Correction of Mie Scattering in Fourier-Transformed Infrared Spectra of Biological Samples
Feb 18, 2020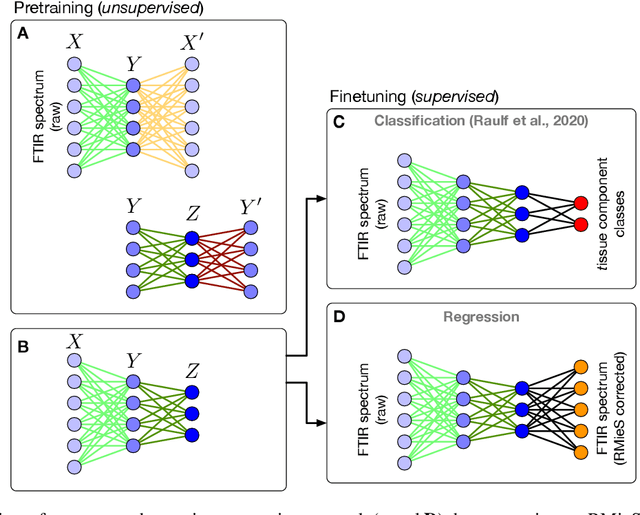

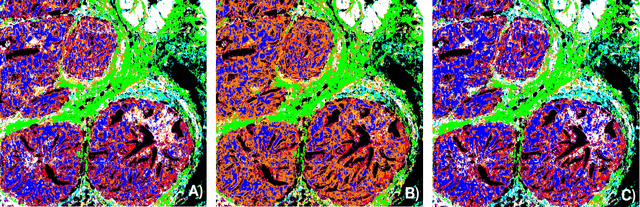

Infrared spectra obtained from cell or tissue specimen have commonly been observed to involve a significant degree of (resonant) Mie scattering, which often overshadows biochemically relevant spectral information by a non-linear, non-additive spectral component in Fourier transformed infrared (FTIR) spectroscopic measurements. Correspondingly, many successful machine learning approaches for FTIR spectra have relied on preprocessing procedures that computationally remove the scattering components from an infrared spectrum. We propose an approach to approximate this complex preprocessing function using deep neural networks. As we demonstrate, the resulting model is not just several orders of magnitudes faster, which is important for real-time clinical applications, but also generalizes strongly across different tissue types. Furthermore, our proposed method overcomes the trade-off between computation time and the corrected spectrum being biased towards an artificial reference spectrum.