 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA two-step sequential approach for hyperparameter selection in finite context models
Mar 20, 2026Finite-context models (FCMs) are widely used for compressing symbolic sequences such as DNA, where predictive performance depends critically on the context length k and smoothing parameter α. In practice, these hyperparameters are typically selected through exhaustive search, which is computationally expensive and scales poorly with model complexity. This paper proposes a statistically grounded two-step sequential approach for efficient hyperparameter selection in FCMs. The key idea is to decompose the joint optimization problem into two independent stages. First, the context length k is estimated using categorical serial dependence measures, including Cramér's ν, Cohen's \k{appa} and partial mutual information (pami). Second, the smoothing parameter α is estimated via maximum likelihood conditional on the selected context length k. Simulation experiments were conducted on synthetic symbolic sequences generated by FCMs across multiple (k, α) configurations, considering a four-letter alphabet and different sample sizes. Results show that the dependence measures are substantially more sensitive to variations in k than in α, supporting the sequential estimation strategy. As expected, the accuracy of the hyperparameter estimation improves with increasing sample size. Furthermore, the proposed method achieves compression performance comparable to exhaustive grid search in terms of average bitrate (bits per symbol), while substantially reducing computational cost. Overall, the results on simulated data show that the proposed sequential approach is a practical and computationally efficient alternative to exhaustive hyperparameter tuning in FCMs.
Revisiting OmniAnomaly for Anomaly Detection: performance metrics and comparison with PCA-based models
Mar 19, 2026Deep learning models have become the dominant approach for multivariate time series anomaly detection (MTSAD), often reporting substantial performance improvements over classical statistical methods. However, these gains are frequently evaluated under heterogeneous thresholding strategies and evaluation protocols, making fair comparisons difficult. This work revisits OmniAnomaly, a widely used stochastic recurrent model for MTSAD, and systematically compares it with a simple linear baseline based on Principal Component Analysis (PCA) on the Server Machine Dataset (SMD). Both methods are evaluated under identical thresholding and evaluation procedures, with experiments repeated across 100 runs for each of the 28 machines in the dataset. Performance is evaluated using Precision, Recall and F1-score at point-level, with and without point-adjustment, and under different aggregation strategies across machines and runs, with the corresponding standard deviations also reported. The results show large variability across machines and show that PCA can achieve performance comparable to OmniAnomaly, and even outperform it when point-adjustment is not applied. These findings question the added value of more complex architectures under current benchmarking practices and highlight the critical role of evaluation methodology in MTSAD research.
Fast and Interpretable Autoregressive Estimation with Neural Network Backpropagation
Mar 19, 2026Autoregressive (AR) models remain widely used in time series analysis due to their interpretability, but convencional parameter estimation methods can be computationally expensive and prone to convergence issues. This paper proposes a Neural Network (NN) formulation of AR estimation by embedding the autoregressive structure directly into a feedforward NN, enabling coefficient estimation through backpropagation while preserving interpretability. Simulation experiments on 125,000 synthetic AR(p) time series with short-term dependence (1 <= p <= 5) show that the proposed NN-based method consistently recovers model coefficients for all series, while Conditional Maximum Likelihood (CML) fails to converge in approximately 55% of cases. When both methods converge, estimation accuracy is comparable with negligible differences in relative error, R2 and, perplexity/likelihood. However, when CML fails, the NN-based approach still provides reliable estimates. In all cases, the NN estimator achieves substantial computational gains, reaching a median speedup of 12.6x and up to 34.2x for higher model orders. Overall, results demonstrate that gradient-descent NN optimization can provide a fast and efficient alternative for interpretable AR parameter estimation.
Unified Taxonomy for Multivariate Time Series Anomaly Detection using Deep Learning
Mar 19, 2026The topic of Multivariate Time Series Anomaly Detection (MTSAD) has grown rapidly over the past years, with a steady rise in publications and Deep Learning (DL) models becoming the dominant paradigm. To address the lack of systematization in the field, this study introduces a novel and unified taxonomy with eleven dimensions over three parts (Input, Output and Model) for the categorization of DL-based MTSAD methods. The dimensions were established in a two-fold approach. First, they derived from a comprehensive analysis of methodological studies. Second, insights from review papers were incorporated. Furthermore, the proposed taxonomy was validated using an additional set of recent publications, providing a clear overview of methodological trends in MTSAD. Results reveal a convergence toward Transformer-based and reconstruction and prediction models, setting the foundation for emerging adaptive and generative trends. Building on and complementing existing surveys, this unified taxonomy is designed to accommodate future developments, allowing for new categories or dimensions to be added as the field progresses. This work thus consolidates fragmented knowledge in the field and provides a reference point for future research in MTSAD.
AIDetx: a compression-based method for identification of machine-learning generated text
Nov 29, 2024



This paper introduces AIDetx, a novel method for detecting machine-generated text using data compression techniques. Traditional approaches, such as deep learning classifiers, often suffer from high computational costs and limited interpretability. To address these limitations, we propose a compression-based classification framework that leverages finite-context models (FCMs). AIDetx constructs distinct compression models for human-written and AI-generated text, classifying new inputs based on which model achieves a higher compression ratio. We evaluated AIDetx on two benchmark datasets, achieving F1 scores exceeding 97% and 99%, respectively, highlighting its high accuracy. Compared to current methods, such as large language models (LLMs), AIDetx offers a more interpretable and computationally efficient solution, significantly reducing both training time and hardware requirements (e.g., no GPUs needed). The full implementation is publicly available at https://github.com/AIDetx/AIDetx.
Automatic analysis of artistic paintings using information-based measures
Feb 02, 2021

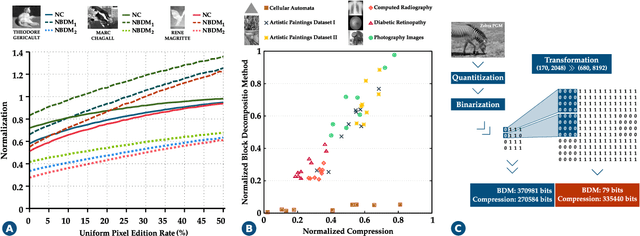

The artistic community is increasingly relying on automatic computational analysis for authentication and classification of artistic paintings. In this paper, we identify hidden patterns and relationships present in artistic paintings by analysing their complexity, a measure that quantifies the sum of characteristics of an object. Specifically, we apply Normalized Compression (NC) and the Block Decomposition Method (BDM) to a dataset of 4,266 paintings from 91 authors and examine the potential of these information-based measures as descriptors of artistic paintings. Both measures consistently described the equivalent types of paintings, authors, and artistic movements. Moreover, combining the NC with a measure of the roughness of the paintings creates an efficient stylistic descriptor. Furthermore, by quantifying the local information of each painting, we define a fingerprint that describes critical information regarding the artists' style, their artistic influences, and shared techniques. More fundamentally, this information describes how each author typically composes and distributes the elements across the canvas and, therefore, how their work is perceived. Finally, we demonstrate that regional complexity and two-point height difference correlation function are useful auxiliary features that improve current methodologies in style and author classification of artistic paintings. The whole study is supported by an extensive website (http://panther.web.ua.pt) for fast author characterization and authentication.