 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardioDiT: Latent Diffusion Transformers for 4D Cardiac MRI Synthesis
Mar 26, 2026Latent diffusion models (LDMs) have recently achieved strong performance in 3D medical image synthesis. However, modalities like cine cardiac MRI (CMR), representing a temporally synchronized 3D volume across the cardiac cycle, add an additional dimension that most generative approaches do not model directly. Instead, they factorize space and time or enforce temporal consistency through auxiliary mechanisms such as anatomical masks. Such strategies introduce structural biases that may limit global context integration and lead to subtle spatiotemporal discontinuities or physiologically inconsistent cardiac dynamics. We investigate whether a unified 4D generative model can learn continuous cardiac dynamics without architectural factorization. We propose CardioDiT, a fully 4D latent diffusion framework for short-axis cine CMR synthesis based on diffusion transformers. A spatiotemporal VQ-VAE encodes 2D+t slices into compact latents, which a diffusion transformer then models jointly as complete 3D+t volumes, coupling space and time throughout the generative process. We evaluate CardioDiT on public CMR datasets and a larger private cohort, comparing it to baselines with progressively stronger spatiotemporal coupling. Results show improved inter-slice consistency, temporally coherent motion, and realistic cardiac function distributions, suggesting that explicit 4D modeling with a diffusion transformer provides a principled foundation for spatiotemporal cardiac image synthesis. Code and models trained on public data are available at https://github.com/Cardio-AI/cardiodit.
Investigating Data Memorization in 3D Latent Diffusion Models for Medical Image Synthesis
Jul 06, 2023



Generative latent diffusion models have been established as state-of-the-art in data generation. One promising application is generation of realistic synthetic medical imaging data for open data sharing without compromising patient privacy. Despite the promise, the capacity of such models to memorize sensitive patient training data and synthesize samples showing high resemblance to training data samples is relatively unexplored. Here, we assess the memorization capacity of 3D latent diffusion models on photon-counting coronary computed tomography angiography and knee magnetic resonance imaging datasets. To detect potential memorization of training samples, we utilize self-supervised models based on contrastive learning. Our results suggest that such latent diffusion models indeed memorize training data, and there is a dire need for devising strategies to mitigate memorization.
Comparison of Evaluation Metrics for Landmark Detection in CMR Images
Jan 28, 2022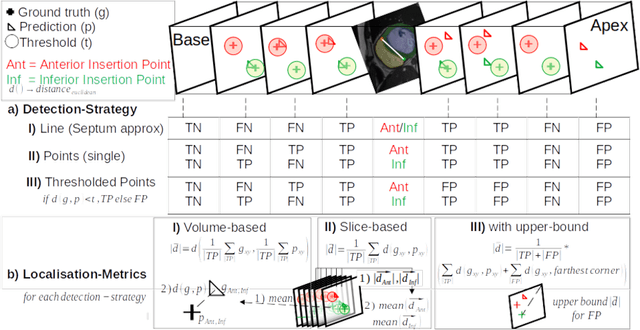

Cardiac Magnetic Resonance (CMR) images are widely used for cardiac diagnosis and ventricular assessment. Extracting specific landmarks like the right ventricular insertion points is of importance for spatial alignment and 3D modeling. The automatic detection of such landmarks has been tackled by multiple groups using Deep Learning, but relatively little attention has been paid to the failure cases of evaluation metrics in this field. In this work, we extended the public ACDC dataset with additional labels of the right ventricular insertion points and compare different variants of a heatmap-based landmark detection pipeline. In this comparison, we demonstrate very likely pitfalls of apparently simple detection and localisation metrics which highlights the importance of a clear detection strategy and the definition of an upper limit for localisation-based metrics. Our preliminary results indicate that a combination of different metrics is necessary, as they yield different winners for method comparison. Additionally, they highlight the need of a comprehensive metric description and evaluation standardisation, especially for the error cases where no metrics could be computed or where no lower/upper boundary of a metric exists. Code and labels: https://github.com/Cardio-AI/rvip_landmark_detection