 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum policy gradient algorithms
Dec 19, 2022
Understanding the power and limitations of quantum access to data in machine learning tasks is primordial to assess the potential of quantum computing in artificial intelligence. Previous works have already shown that speed-ups in learning are possible when given quantum access to reinforcement learning environments. Yet, the applicability of quantum algorithms in this setting remains very limited, notably in environments with large state and action spaces. In this work, we design quantum algorithms to train state-of-the-art reinforcement learning policies by exploiting quantum interactions with an environment. However, these algorithms only offer full quadratic speed-ups in sample complexity over their classical analogs when the trained policies satisfy some regularity conditions. Interestingly, we find that reinforcement learning policies derived from parametrized quantum circuits are well-behaved with respect to these conditions, which showcases the benefit of a fully-quantum reinforcement learning framework.
A Sublinear-Time Quantum Algorithm for Approximating Partition Functions
Jul 18, 2022

We present a novel quantum algorithm for estimating Gibbs partition functions in sublinear time with respect to the logarithm of the size of the state space. This is the first speed-up of this type to be obtained over the seminal nearly-linear time algorithm of \v{S}tefankovi\v{c}, Vempala and Vigoda [JACM, 2009]. Our result also preserves the quadratic speed-up in precision and spectral gap achieved in previous work by exploiting the properties of quantum Markov chains. As an application, we obtain new polynomial improvements over the best-known algorithms for computing the partition function of the Ising model, and counting the number of $k$-colorings, matchings or independent sets of a graph. Our approach relies on developing new variants of the quantum phase and amplitude estimation algorithms that return nearly unbiased estimates with low variance and without destroying their initial quantum state. We extend these subroutines into a nearly unbiased quantum mean estimator that reduces the variance quadratically faster than the classical empirical mean. No such estimator was known to exist prior to our work. These properties, which are of general interest, lead to better convergence guarantees within the paradigm of simulated annealing for computing partition functions.
Near-Optimal Quantum Algorithms for Multivariate Mean Estimation
Nov 18, 2021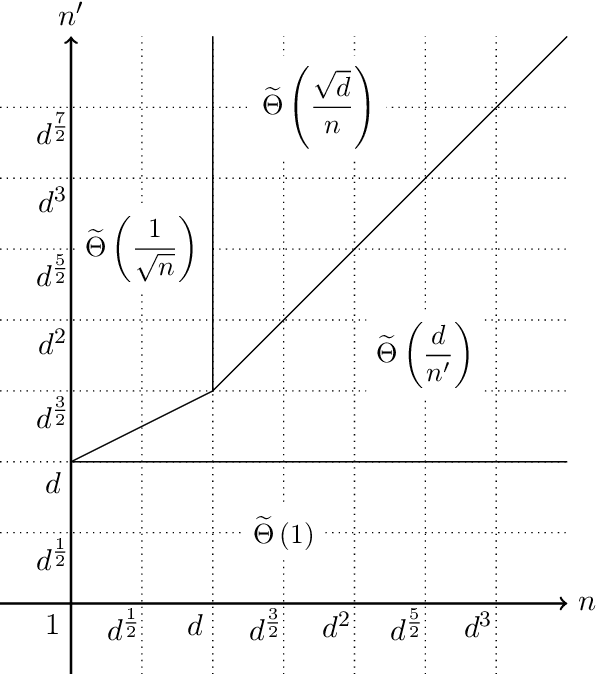
We propose the first near-optimal quantum algorithm for estimating in Euclidean norm the mean of a vector-valued random variable with finite mean and covariance. Our result aims at extending the theory of multivariate sub-Gaussian estimators to the quantum setting. Unlike classically, where any univariate estimator can be turned into a multivariate estimator with at most a logarithmic overhead in the dimension, no similar result can be proved in the quantum setting. Indeed, Heinrich ruled out the existence of a quantum advantage for the mean estimation problem when the sample complexity is smaller than the dimension. Our main result is to show that, outside this low-precision regime, there is a quantum estimator that outperforms any classical estimator. Our approach is substantially more involved than in the univariate setting, where most quantum estimators rely only on phase estimation. We exploit a variety of additional algorithmic techniques such as amplitude amplification, the Bernstein-Vazirani algorithm, and quantum singular value transformation. Our analysis also uses concentration inequalities for multivariate truncated statistics. We develop our quantum estimators in two different input models that showed up in the literature before. The first one provides coherent access to the binary representation of the random variable and it encompasses the classical setting. In the second model, the random variable is directly encoded into the phases of quantum registers. This model arises naturally in many quantum algorithms but it is often incomparable to having classical samples. We adapt our techniques to these two settings and we show that the second model is strictly weaker for solving the mean estimation problem. Finally, we describe several applications of our algorithms, notably in measuring the expectation values of commuting observables and in the field of machine learning.