 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotometric Redshift Estimation Using Scaled Ensemble Learning
Jan 12, 2026The development of the state-of-the-art telescopic systems capable of performing expansive sky surveys such as the Sloan Digital Sky Survey, Euclid, and the Rubin Observatory's Legacy Survey of Space and Time (LSST) has significantly advanced efforts to refine cosmological models. These advances offer deeper insight into persistent challenges in astrophysics and our understanding of the Universe's evolution. A critical component of this progress is the reliable estimation of photometric redshifts (Pz). To improve the precision and efficiency of such estimations, the application of machine learning (ML) techniques to large-scale astronomical datasets has become essential. This study presents a new ensemble-based ML framework aimed at predicting Pz for faint galaxies and higher redshift ranges, relying solely on optical (grizy) photometric data. The proposed architecture integrates several learning algorithms, including gradient boosting machine, extreme gradient boosting, k-nearest neighbors, and artificial neural networks, within a scaled ensemble structure. By using bagged input data, the ensemble approach delivers improved predictive performance compared to stand-alone models. The framework demonstrates consistent accuracy in estimating redshifts, maintaining strong performance up to z ~ 4. The model is validated using publicly available data from the Hyper Suprime-Cam Strategic Survey Program by the Subaru Telescope. Our results show marked improvements in the precision and reliability of Pz estimation. Furthermore, this approach closely adheres to-and in certain instances exceeds-the benchmarks specified in the LSST Science Requirements Document. Evaluation metrics include catastrophic outlier, bias, and rms.
* 10 pages, 2 figures, 3 tables
ERATTA: Extreme RAG for Table To Answers with Large Language Models
May 07, 2024



Large language models (LLMs) with residual augmented-generation (RAG) have been the optimal choice for scalable generative AI solutions in the recent past. However, the choice of use-cases that incorporate RAG with LLMs have been either generic or extremely domain specific, thereby questioning the scalability and generalizability of RAG-LLM approaches. In this work, we propose a unique LLM-based system where multiple LLMs can be invoked to enable data authentication, user query routing, data retrieval and custom prompting for question answering capabilities from data tables that are highly varying and large in size. Our system is tuned to extract information from Enterprise-level data products and furnish real time responses under 10 seconds. One prompt manages user-to-data authentication followed by three prompts to route, fetch data and generate a customizable prompt natural language responses. Additionally, we propose a five metric scoring module that detects and reports hallucinations in the LLM responses. Our proposed system and scoring metrics achieve >90% confidence scores across hundreds of user queries in the sustainability, financial health and social media domains. Extensions to the proposed extreme RAG architectures can enable heterogeneous source querying using LLMs.
Automated Heterogeneous Low-Bit Quantization of Multi-Model Deep Learning Inference Pipeline
Nov 10, 2023

Multiple Deep Neural Networks (DNNs) integrated into single Deep Learning (DL) inference pipelines e.g. Multi-Task Learning (MTL) or Ensemble Learning (EL), etc., albeit very accurate, pose challenges for edge deployment. In these systems, models vary in their quantization tolerance and resource demands, requiring meticulous tuning for accuracy-latency balance. This paper introduces an automated heterogeneous quantization approach for DL inference pipelines with multiple DNNs.
Hallucination-minimized Data-to-answer Framework for Financial Decision-makers
Nov 09, 2023Large Language Models (LLMs) have been applied to build several automation and personalized question-answering prototypes so far. However, scaling such prototypes to robust products with minimized hallucinations or fake responses still remains an open challenge, especially in niche data-table heavy domains such as financial decision making. In this work, we present a novel Langchain-based framework that transforms data tables into hierarchical textual data chunks to enable a wide variety of actionable question answering. First, the user-queries are classified by intention followed by automated retrieval of the most relevant data chunks to generate customized LLM prompts per query. Next, the custom prompts and their responses undergo multi-metric scoring to assess for hallucinations and response confidence. The proposed system is optimized with user-query intention classification, advanced prompting, data scaling capabilities and it achieves over 90% confidence scores for a variety of user-queries responses ranging from {What, Where, Why, How, predict, trend, anomalies, exceptions} that are crucial for financial decision making applications. The proposed data to answers framework can be extended to other analytical domains such as sales and payroll to ensure optimal hallucination control guardrails.
Cross-Lingual Training for Automatic Question Generation
Jun 06, 2019
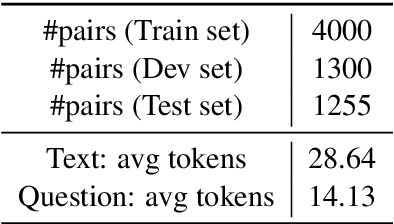
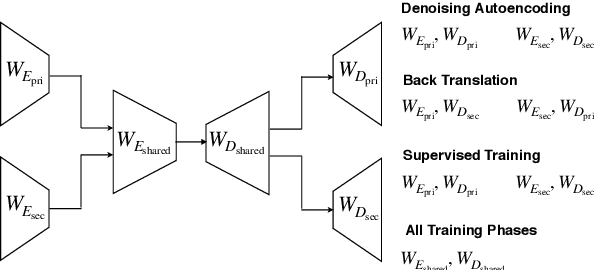
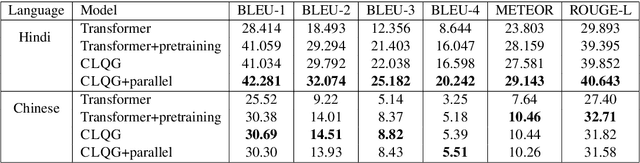
Automatic question generation (QG) is a challenging problem in natural language understanding. QG systems are typically built assuming access to a large number of training instances where each instance is a question and its corresponding answer. For a new language, such training instances are hard to obtain making the QG problem even more challenging. Using this as our motivation, we study the reuse of an available large QG dataset in a secondary language (e.g. English) to learn a QG model for a primary language (e.g. Hindi) of interest. For the primary language, we assume access to a large amount of monolingual text but only a small QG dataset. We propose a cross-lingual QG model which uses the following training regime: (i) Unsupervised pretraining of language models in both primary and secondary languages and (ii) joint supervised training for QG in both languages. We demonstrate the efficacy of our proposed approach using two different primary languages, Hindi and Chinese. We also create and release a new question answering dataset for Hindi consisting of 6555 sentences.