 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriLite: Efficient Weakly Supervised Object Localization with Universal Visual Features and Tri-Region Disentanglement
Feb 26, 2026Weakly supervised object localization (WSOL) aims to localize target objects in images using only image-level labels. Despite recent progress, many approaches still rely on multi-stage pipelines or full fine-tuning of large backbones, which increases training cost, while the broader WSOL community continues to face the challenge of partial object coverage. We present TriLite, a single-stage WSOL framework that leverages a frozen Vision Transformer with Dinov2 pre-training in a self-supervised manner, and introduces only a minimal number of trainable parameters (fewer than 800K on ImageNet-1K) for both classification and localization. At its core is the proposed TriHead module, which decomposes patch features into foreground, background, and ambiguous regions, thereby improving object coverage while suppressing spurious activations. By disentangling classification and localization objectives, TriLite effectively exploits the universal representations learned by self-supervised ViTs without requiring expensive end-to-end training. Extensive experiments on CUB-200-2011, ImageNet-1K, and OpenImages demonstrate that TriLite sets a new state of the art, while remaining significantly more parameter-efficient and easier to train than prior methods. The code will be released soon.
Deep Learning meets Liveness Detection: Recent Advancements and Challenges
Dec 29, 2021
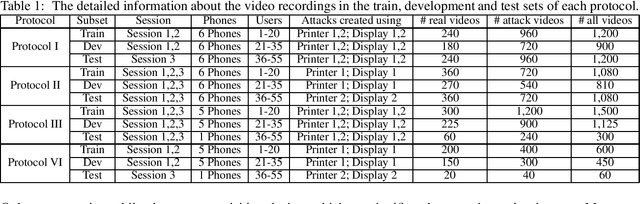
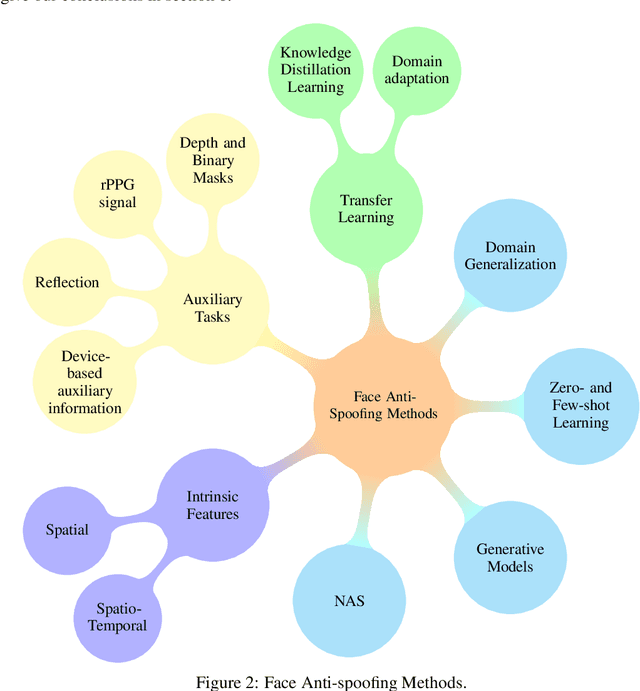
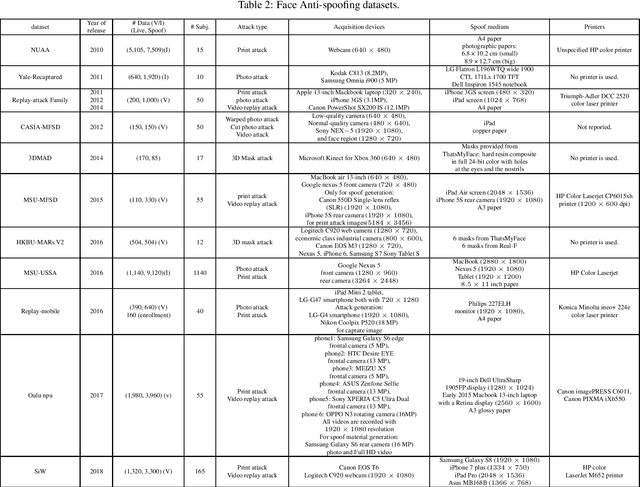
Facial biometrics has been recently received tremendous attention as a convenient replacement for traditional authentication systems. Consequently, detecting malicious attempts has found great significance, leading to extensive studies in face anti-spoofing~(FAS),i.e., face presentation attack detection. Deep feature learning and techniques, as opposed to hand-crafted features, have promised a dramatic increase in the FAS systems' accuracy, tackling the key challenges of materializing the real-world application of such systems. Hence, a new research area dealing with the development of more generalized as well as accurate models is increasingly attracting the attention of the research community and industry. In this paper, we present a comprehensive survey on the literature related to deep-feature-based FAS methods since 2017. To shed light on this topic, a semantic taxonomy based on various features and learning methodologies is represented. Further, we cover predominant public datasets for FAS in chronological order, their evolutional progress, and the evaluation criteria (both intra-dataset and inter-dataset). Finally, we discuss the open research challenges and future directions.
Advances and Challenges in Deep Lip Reading
Oct 15, 2021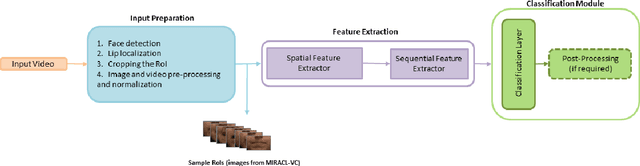

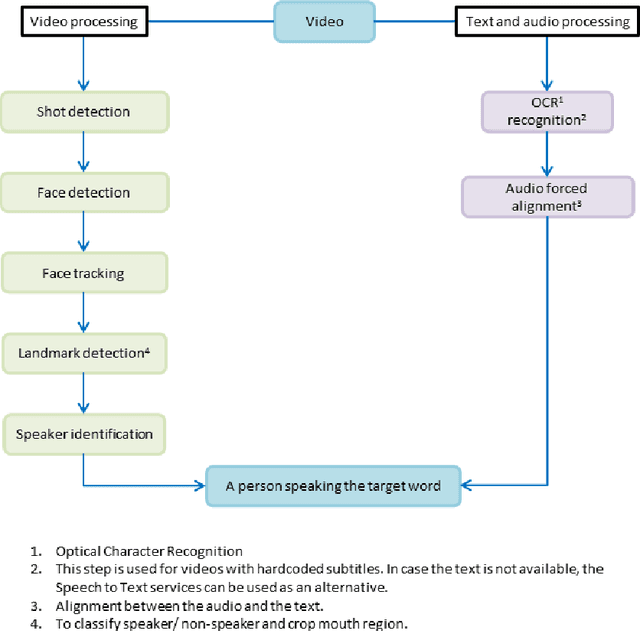
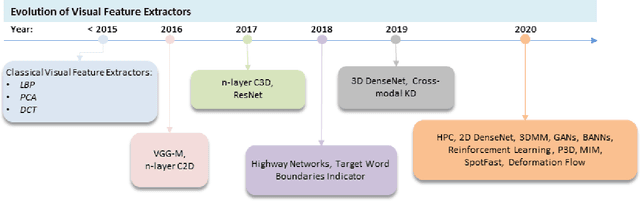
Driven by deep learning techniques and large-scale datasets, recent years have witnessed a paradigm shift in automatic lip reading. While the main thrust of Visual Speech Recognition (VSR) was improving accuracy of Audio Speech Recognition systems, other potential applications, such as biometric identification, and the promised gains of VSR systems, have motivated extensive efforts on developing the lip reading technology. This paper provides a comprehensive survey of the state-of-the-art deep learning based VSR research with a focus on data challenges, task-specific complications, and the corresponding solutions. Advancements in these directions will expedite the transformation of silent speech interface from theory to practice. We also discuss the main modules of a VSR pipeline and the influential datasets. Finally, we introduce some typical VSR application concerns and impediments to real-world scenarios as well as future research directions.