 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Active Learning for Few-Shot Example Selection in Text-to-SQL
Jun 08, 2026Few-shot example retrieval is the dominant paradigm for grounding large language models (LLMs) in domain-specific text-to-SQL systems. However, the quality of the annotated example bank directly governs system accuracy, and expert annotation is prohibitively expensive. We formalize the active selection of these examples as a constrained experimental design problem over the intrinsic, low-dimensional manifold of semantic query embeddings. Unlike standard active learning frameworks, our setting introduces three critical challenges: varying, query-dependent annotation reliability (heteroscedasticity), strict requirements for spatial diversity across semantic topics (partition matroid constraints), and the inherent reality that the true covariance structure of the embedding space is unknown (misspecification). To address these, we propose a stratified greedy algorithm that maximizes a heteroscedastic mutual information objective. We prove that this objective remains submodular and approximately monotonic on the intrinsic manifold, yielding a theoretical constant-factor approximation guarantee. We establish a spectral bound demonstrating that this approximation guarantee degrades gracefully, rather than catastrophically, when the assumed surrogate kernel diverges from the true underlying data-generating process. Empirical results demonstrate that the proposed strategy significantly reduces labeling effort while maintaining high text-to-SQL retrieval accuracy.
A Bayesian framework for local calibration of expensive computational models through non-isometric matching
Sep 22, 2018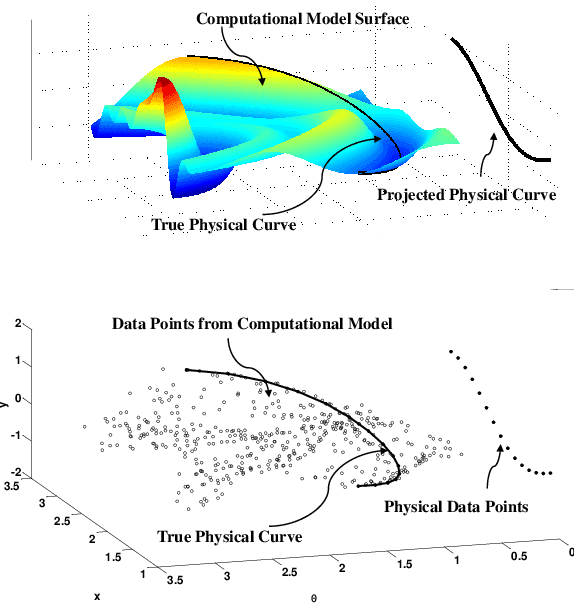
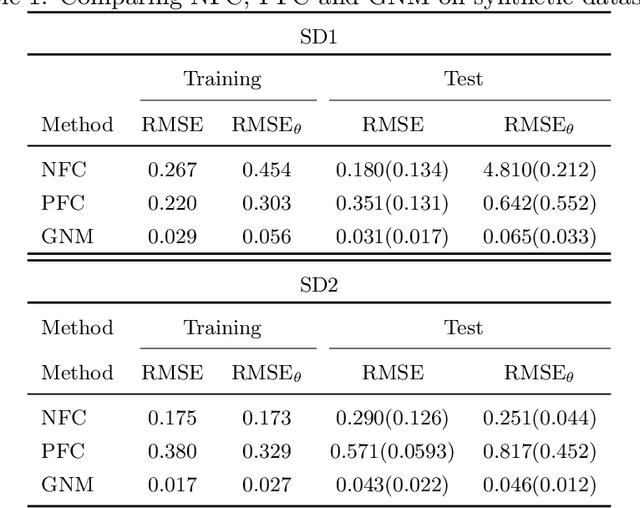
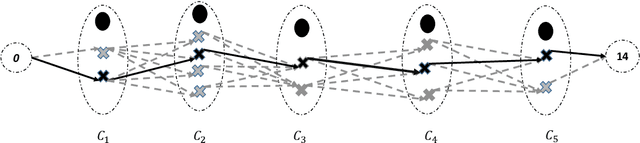
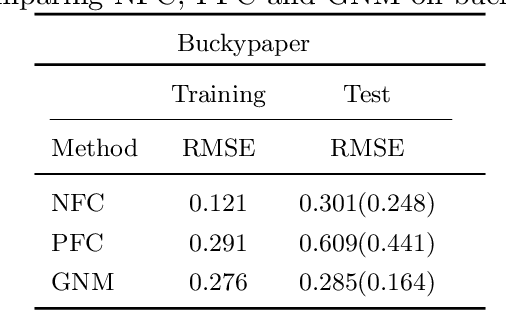
We study statistical calibration, i.e., adjusting features of a computational model that are not observable or controllable in its associated physical system. We focus on local, or functional, calibration, which arises in many manufacturing processes where the unobservable features, called calibration variables, are a function of the input variables. A major challenge in many applications is that computational models are expensive and can only be evaluated a limited number of times. Furthermore, without making strong assumptions, the calibration variables are not identifiable. We propose Bayesian non-isometric matching calibration (BNMC) that allows calibration of expensive computational models with only a limited number of samples taken from a computational model and its associated physical system. BNMC replaces the computational model with a dynamic Gaussian Process (GP) whose parameters are trained in the calibration procedure. To resolve the identifiability issue, we present the calibration problem from a geometric perspective of non-isometric curve to surface matching, which enables us to take advantage of combinatorial optimization techniques to extract necessary information for constructing prior distributions. Our numerical experiments demonstrate that in terms of prediction accuracy BNMC outperforms, or is comparable to, other existing calibration frameworks.
Sparse Pseudo-input Local Kriging for Large Non-stationary Spatial Datasets with Exogenous Variables
Jun 15, 2018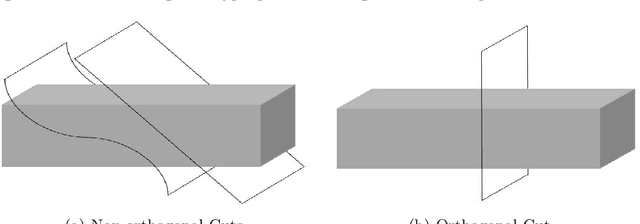
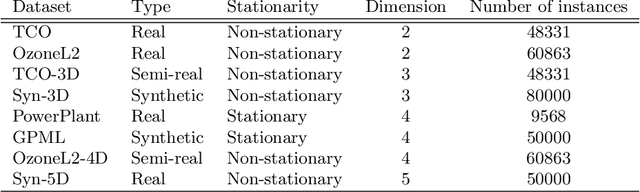
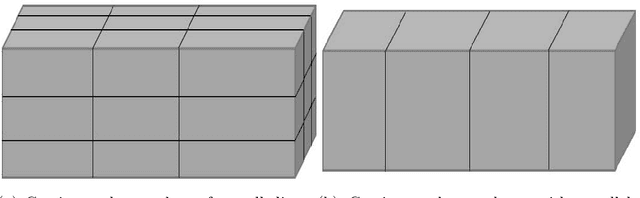
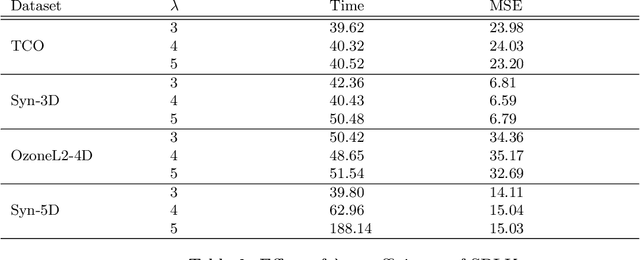
We study large-scale spatial systems that contain exogenous variables, e.g. environmental factors that are significant predictors in spatial processes. Building predictive models for such processes involve two major challenges. First, the spatial processes are highly non-stationary and characterized by a heterogeneous covariance structure primarily due to the presence of exogenous variables. Second, it is inefficient to apply full Kriging because of the large numbers of observations present. The new theorems proposed in this paper form the basis for a new partitioning policy and a method, which we call Sparse Pseudo-input Local Kriging (SPLK). The proposed method handles heterogeneity in covariance and computational complexity by utilizing hyperplanes to partition a domain into smaller subdomains and then applying a sparse approximation of the full Kriging to each subdomain. We also develop a procedure to find the optimal hyperplanes. We impose continuity constraints on the boundaries of the neighboring subdomains to alleviate the problem of discontinuity of the global predictor. Numerical experiments demonstrate that SPLK outperforms, or is comparable to, the algorithms commonly applied to spatial datasets.
Empirical Similarity for Absent Data Generation in Imbalanced Classification
May 12, 2016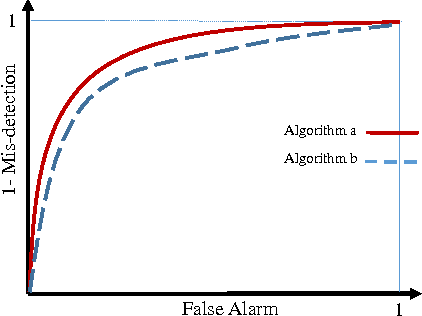
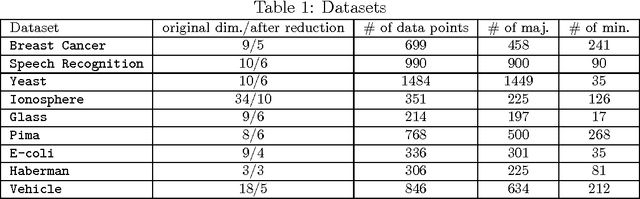
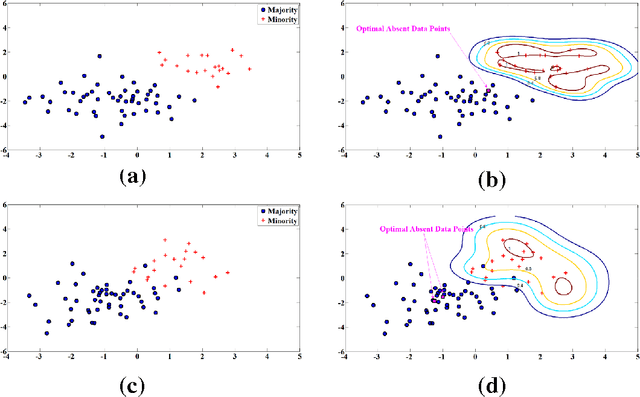
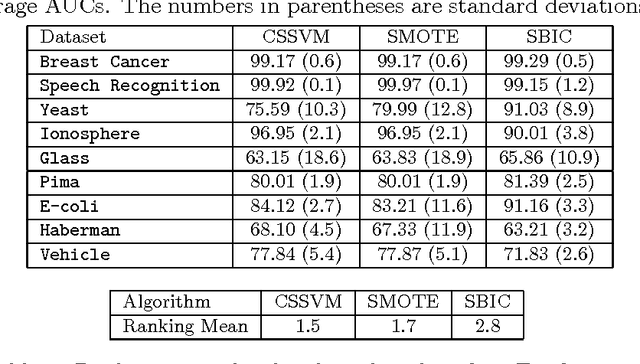
When the training data in a two-class classification problem is overwhelmed by one class, most classification techniques fail to correctly identify the data points belonging to the underrepresented class. We propose Similarity-based Imbalanced Classification (SBIC) that learns patterns in the training data based on an empirical similarity function. To take the imbalanced structure of the training data into account, SBIC utilizes the concept of absent data, i.e. data from the minority class which can help better find the boundary between the two classes. SBIC simultaneously optimizes the weights of the empirical similarity function and finds the locations of absent data points. As such, SBIC uses an embedded mechanism for synthetic data generation which does not modify the training dataset, but alters the algorithm to suit imbalanced datasets. Therefore, SBIC uses the ideas of both major schools of thoughts in imbalanced classification: Like cost-sensitive approaches SBIC operates on an algorithm level to handle imbalanced structures; and similar to synthetic data generation approaches, it utilizes the properties of unobserved data points from the minority class. The application of SBIC to imbalanced datasets suggests it is comparable to, and in some cases outperforms, other commonly used classification techniques for imbalanced datasets.