 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning research landscape & roadmap in a nutshell: past, present and future -- Towards deep cortical learning
Jul 30, 2019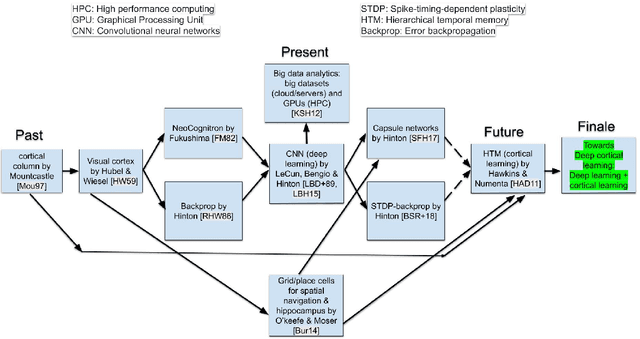
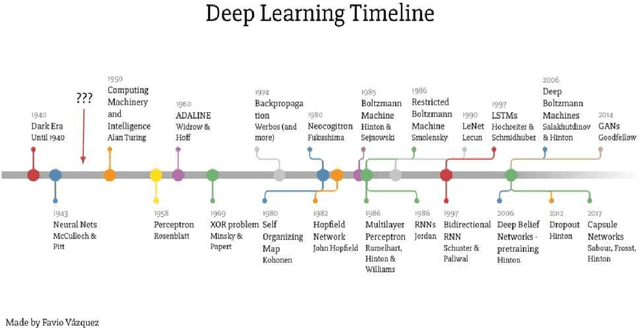
The past, present and future of deep learning is presented in this work. Given this landscape & roadmap, we predict that deep cortical learning will be the convergence of deep learning & cortical learning which builds an artificial cortical column ultimately.
Stereo-based terrain traversability analysis using normal-based segmentation and superpixel surface analysis
Jul 16, 2019

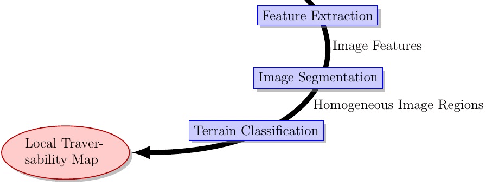

In this paper, an stereo-based traversability analysis approach for all terrains in off-road mobile robotics, e.g. Unmanned Ground Vehicles (UGVs) is proposed. This approach reformulates the problem of terrain traversability analysis into two main problems: (1) 3D terrain reconstruction and (2) terrain all surfaces detection and analysis. The proposed approach is using stereo camera for perception and 3D reconstruction of the terrain. In order to detect all the existing surfaces in the 3D reconstructed terrain as superpixel surfaces (i.e. segments), an image segmentation technique is applied using geometry-based features (pixel-based surface normals). Having detected all the surfaces, Superpixel Surface Traversability Analysis approach (SSTA) is applied on all of the detected surfaces (superpixel segments) in order to classify them based on their traversability index. The proposed SSTA approach is based on: (1) Superpixel surface normal and plane estimation, (2) Traversability analysis using superpixel surface planes. Having analyzed all the superpixel surfaces based on their traversability, these surfaces are finally classified into five main categories as following: traversable, semi-traversable, non-traversable, unknown and undecided.
Iterative temporal differencing with random synaptic feedback weights support error backpropagation for deep learning
Jul 15, 2019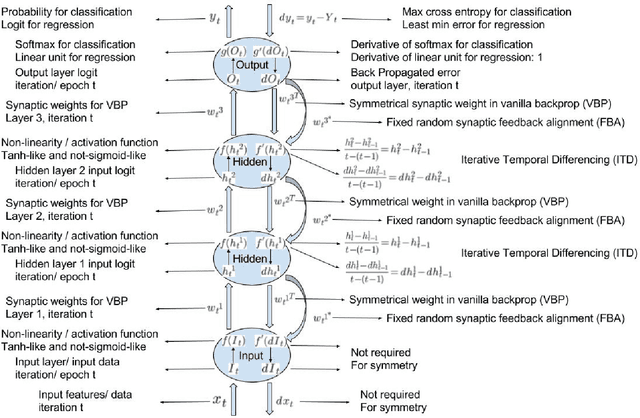
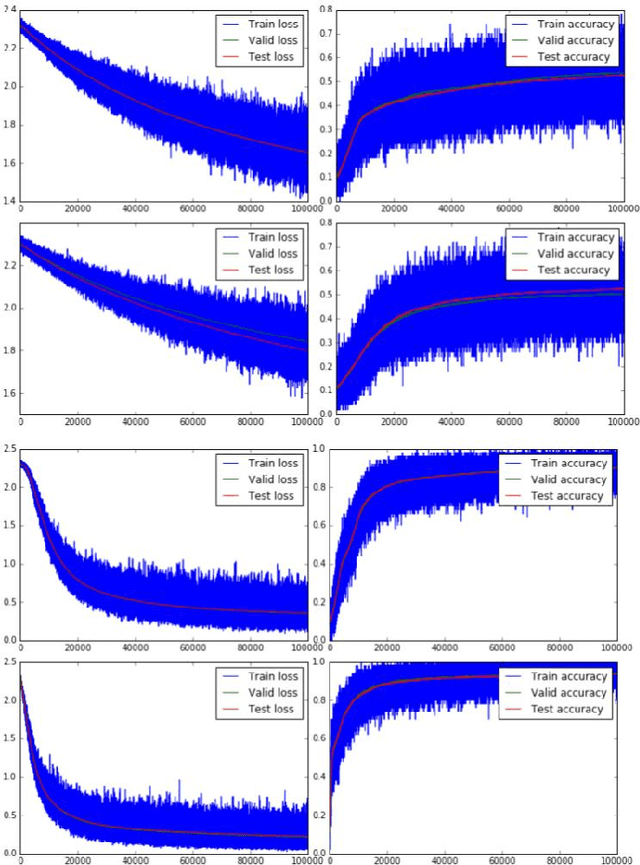
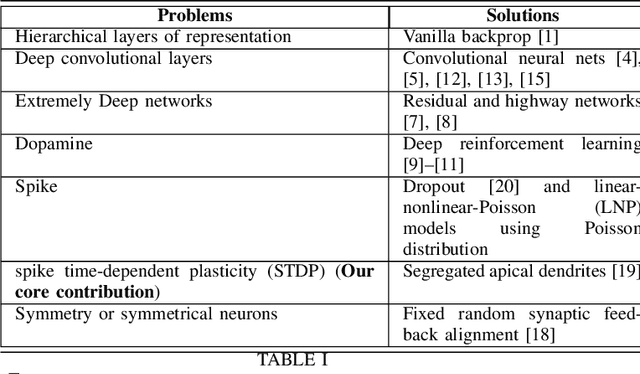
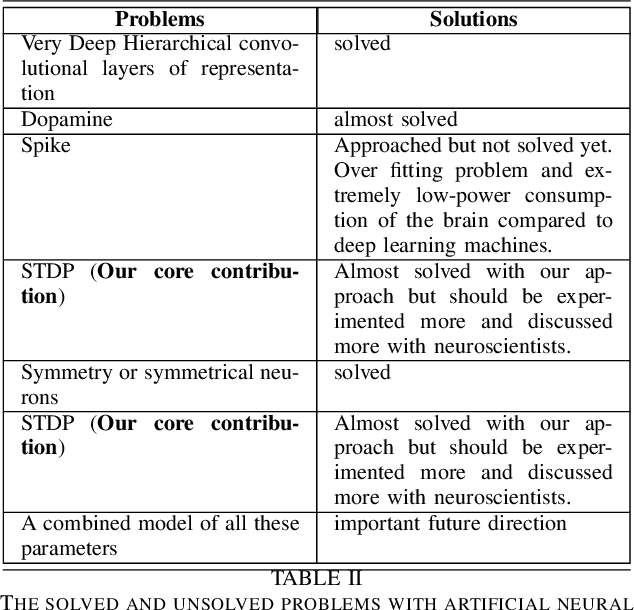
This work shows that a differentiable activation function is not necessary any more for error backpropagation. The derivative of the activation function can be replaced by an iterative temporal differencing using fixed random feedback alignment. Using fixed random synaptic feedback alignment with an iterative temporal differencing is transforming the traditional error backpropagation into a more biologically plausible approach for learning deep neural network architectures. This can be a big step toward the integration of STDP-based error backpropagation in deep learning.
MLR : A General Cognitive Model -- applied to Intelligent Robots and Systems Control
Jul 12, 2019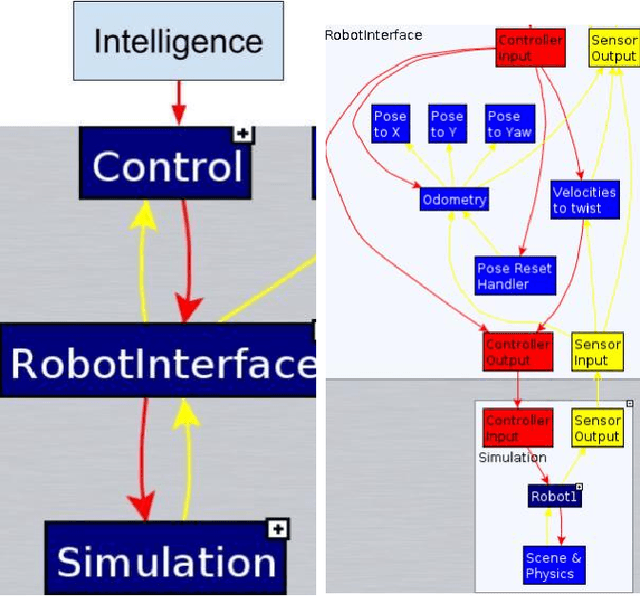
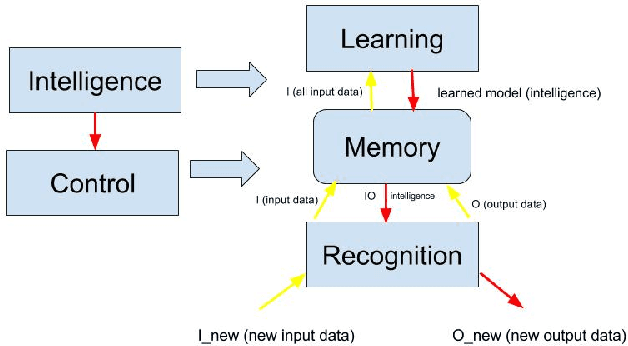
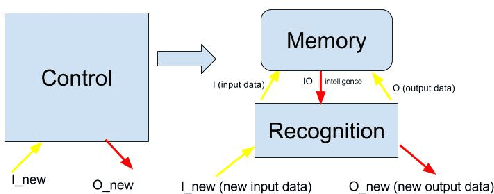
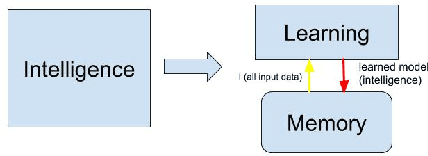
This paper introduces a new perspective of intelligent robots and systems control. The presented and proposed cognitive model: Memory, Learning and Recognition (MLR), is an effort to bridge the gap between Robotics, AI, Cognitive Science, and Neuroscience. The currently existing gap prevents us from integrating the current advancement and achievements of these four research fields which are actively trying to define intelligence in either application-based way or in generic way. This cognitive model defines intelligence more specifically, parametrically and detailed. The proposed MLR model helps us create a general control model for robots and systems independent of their application domains and platforms since it is mainly based on the dataset provided for robots and systems controls. This paper is mainly proposing and introducing this concept and trying to prove this concept in a small scale, firstly through experimentation. The proposed concept is also applicable to other different platforms in real-time as well as in simulation.
Human Body Parts Tracking: Applications to Activity Recognition
Jul 02, 2019As cameras and computers became popular, the applications of computer vision techniques attracted attention enormously. One of the most important applications in the computer vision community is human activity recognition. In order to recognize human activities, we propose a human body parts tracking system that tracks human body parts such as head, torso, arms and legs in order to perform activity recognition tasks in real time. This thesis presents a real-time human body parts tracking system (i.e. HBPT) from video sequences. Our body parts model is mostly represented by body components such as legs, head, torso and arms. The body components are modeled using torso location and size which are obtained by a torso tracking method in each frame. In order to track the torso, we are using a blob tracking module to find the approximate location and size of the torso in each frame. By tracking the torso, we will be able to track other body parts based on their location with respect to the torso on the detected silhouette. In the proposed method for human body part tracking, we are also using a refining module to improve the detected silhouette by refining the foreground mask (i.e. obtained by background subtraction) in order to detect the body parts with respect to torso location and size. Having found the torso size and location, the region of each human body part on the silhouette will be modeled by a 2D-Gaussian blob in each frame in order to show its location, size and pose. The proposed approach described in this thesis tracks accurately the body parts in different illumination conditions and in the presence of partial occlusions. The proposed approach is applied to activity recognition tasks such as approaching an object, carrying an object and opening a box or suitcase.